Discover How Google Interprets JavaScript
JavaScript referencing is a hot topic because more and more websites are using modern JavaScript frameworks and libraries, such as Angular, React, and Vue.js.
Familiarize Yourself With the Issues Googlebot can Have With JavaScript
Since 2014, Google has said its search engine is better able to understand web pages; however, experience shows that its understanding of JavaScript is not yet perfect. Therefore, it's a good idea to follow all best practices and optimize your site as best you can! :)
There are three important factors concerning the referencing of JavaScript:
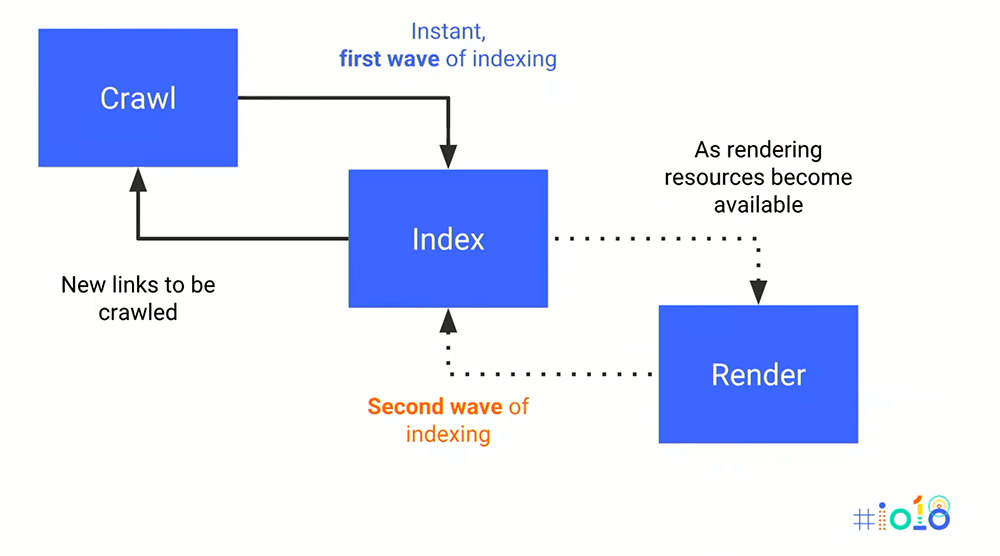
Crawling: Googlebot must be able to crawl your site by navigating through links;
Rendering: Googlebot must be able to read the content of your web page (rendering being the act of interpreting the code on the page to actually display your website);
Crawl budget: Googlebot uses a lot of resources to browse and index sites. If it's too difficult to crawl your site and takes too many resources, it won’t finish the job.
Googlebot is increasingly able to understand JavaScript, but there are additional steps you must take!
Why is it difficult for Google to crawl JavaScript?
Three reasons for this:
First, it's easy to make a mistake in JavaScript, as in any language. The problem is that an error can prevent the remaining code from executing properly. You can run into major problems if your entire page is displayed using JavaScript.
Second, Googlebot behaves like the Chromium browser to render your website. It follows Chromium's updates. However, due to their popularity, JavaScript frameworks evolve quickly. Consequently, Googlebot might not understand certain new syntaxes.
Finally, it's possible to use techniques such as transpiling or polyfilling to make your JavasSript code compatible with older browsers, but it won't solve everything. Letting Googlebot render your JavaScript forces it to expend a lot more resources. Instead of exploring and downloading multiple pages simultaneously as it would for HTML/CSS, Googlebot will have to:
First crawl.
Download the page.
Render.
Index a first time.
Find other links once the page has rendered, then repeat the operation.
As you have seen, it's always better to make Google's job easier and not harder!
Pick the Right Technology for Your Site
Here are three scenarios if you don't already have a website online:
1. Your Site Has Few Business Functions and Is Mainly Used for Marketing (Customer Acquisition)
Simple! Opt for a standard site and not one based on a JavaScript framework like websites with a few, simple functionalities, such as a reservation or payment form.
2. Your Site Is a Web App With Important Business Functions. You Also Need a Place to Showcase Products and Acquire New Customers
This is the case for most SaaS platforms, such as OnCrawl.
If you already have a web-app, but not a marketing-oriented site, you are better off coding it in HTML/CSS and then linking to your web app! That way, you will have the best of both worlds: a more user-friendly web app in JavaScript, and a classic site for acquiring new customers, which is easier to maintain.
3. You Want to Build, or Already Have Built, an SPA (Single-Page Application)
If your site is already coded in JavaScript because you wanted to use the same technology for your showcase site as your app, you will need to help Googlebot index it. That is the subject of the following chapter! :)
Adopt SEO Best Practices if Your Website Is in Angular, React, or Vue
It's possible to confuse problems caused by JavaScript or SPA with certain easy-to-solve SEO problems. Practice good habits, regardless of what web technology you use and don’t be too quick to blame JavaScript! Remember:
Indexable URLs - Pages always need unique, distinct, and indexable URLs.
There must be a real page, with a server response of 200 OK for each individual page you want to index. The SPA must provide server-side URLs for each category, article, or product.
Do not use # in URLs to indicate separate pages.
Pages always need titles, meta descriptions, meta robots, their own URLs (that contains the keyword), textual content, images, alt attributes, etc.
JavaScript site content must be audited just like a website in HTML/CSS.
Googlebot follows links to crawl your site, so don’t forget to put them in (href for attributes, src for images).
Duplicate content - JavaScript rendering can create multiple versions of the same page (pre-DOM and post-DOM). Be sure to minimize differences and don’t forget the canonical tag!
Let's Recap!
Googlebot can crawl JavaScript, but it's not ideal.
If you need a customer-facing website, you should consider building it in HTML/CSS.
If you already have a website coded in a JavaScript framework, follow best practices and study the next chapter!
