Vous avez vu précédemment comment les professionnels de la DSI définissent un SI, et comment ils en gèrent la complexité. Comme nous l’avons vu, un SI repose en partie sur une architecture technique (des serveurs, des réseaux, des logiciels). Dans votre découverte du monde des SI, il est intéressant de vous attarder sur la partie technique du système : elle constitue la base sur laquelle reposent les activités métier de l’entreprise !
Dans ce contexte, qu’est-ce qu’une une infrastructure technique ? Quelles sont les briques qui la constituent ? Quels sont les critères qui guident les DSI dans leur choix ? Quelles sont les différentes manières de structurer la partie technique du SI, et quels en sont les enjeux ?
Nous allons voir tout cela en détail. Prêt ? C’est parti.
Qu’est-ce qu’une architecture technique ?
Retour sur le cycle de vie d’un SI
Comme nous l’avons vu précédemment, c’est la réflexion sur les processus métier ou les activités de l'entreprise qui donne naissance au SI, aux applications que l’on va développer ou acheter pour rendre ses activités possibles, et aussi au système informatique qui va les faire fonctionner.
Voyons en détail les différentes briques qui la composent.
Les composants du SI
Si vous réfléchissez à cette question, un élément vous vient certainement à l’esprit : l’ordinateur ! C’est juste, c’est un élément central, mais il n’est pas seul. On trouve aussi :
les équipements réseaux ;
les capteurs ;
les serveurs ;
les guichets automatiques bancaires ;
les boîtiers de stockage en réseau ;
les robots ;
les automates industriels ;
les cartes à puce et bien d’autres encore !
L’ordinateur : le cœur du SI
Un ordinateur est une machine qui permet de traiter automatiquement un jeu de données grâce à un programme enregistré dans la mémoire de l’ordinateur. Il comporte un ou des processeurs, une mémoire et des périphériques d’entrée (clavier, souris), de sortie (écran, imprimante) et de stockage (le disque dur de votre ordinateur).
Puis, l’évolution des technologies et la baisse des prix des composants ont permis au grand public d’accéder à l’ordinateur et de le spécialiser. Il existe aujourd’hui une très grande diversité d’ordinateurs, du plus petit qui tient en totalité sur une puce électronique d’un centimètre carré, au plus puissant, le supercalculateur capable de traiter d’énormes volumes de données pour déterminer des prévisions météorologiques, ou encore simuler une explosion nucléaire.
À ce jour, un utilisateur de smartphone a dans sa poche une puissance de calcul équivalente à celle d'un ordinateur d’il y a une vingtaine d’années.
Dans les SI actuels, les ordinateurs ont beaucoup de fonctions différentes :
stocker de la donnée : serveur de base de données, serveur de fichiers ou data center ;
participer à assurer la sécurité : firewall ou proxy ;
héberger des applications : serveur Web, serveur d’application.
Un autre élément fondamental : le réseau
Vous l’avez compris, les ordinateurs assurent le fonctionnement du SI. Mais ils ne sont pas isolés, ils sont interdépendants et communiquent entre eux. Ils sont placés au cœur de réseaux.
On a donc besoin d’équipements de traitement et de transmission de données :
les commutateurs réseau qui créent le réseau physique (c’est là que l’on branche les fils !) ;
les routeurs chargés de faire circuler l’information entre différents réseaux.
Ces réseaux peuvent être de différentes tailles :
LAN (Local Area Network) lorsqu’ils sont à l’échelle d’un bâtiment ;
MAN (Metropolitan Area Network) lorsqu’ils sont à l’échelle d’une ville ;
WAN (Wide Area Network) lorsqu’ils sont étendus à l’échelle mondiale. Internet est le plus grand des WAN !
Structures types de déploiement d’infrastructure technique
Comprendre les différentes briques fonctionnelles d’une infrastructure technique
Dans votre approche globale du SI, vous devez distinguer les différentes briques fonctionnelles. C’est leur agencement et leurs interactions respectifs qui déterminent le type d’architecture cible que vous souhaitez obtenir. On distingue :
les utilisateurs : client, administrateur, toute personne ayant une interaction avec le SI ;
les traitements : calcul, transformation ;
les données : tout ce qui est susceptible d'être stocké.
Différents types d'architectures
On trouve 2 types de déploiement principaux : les architectures centralisées et réparties.
Une architecture est dite centralisée quand les utilisateurs, les traitements et les données sont situés sur le même ordinateur. Un ordinateur qui n’est pas raccordé à un réseau représente un bon exemple.
Une architecture répartie, a contrario, permet de distribuer les différentes briques fonctionnelles (application utilisateur, traitements et données sur des ordinateurs différents). Si l'on pousse cette logique à l'extrême, on trouve les architectures de type Cloud que nous verrons en détail dans ce cours.
Les différents types d'architectures que l’on peut trouver aujourd’hui dans les entreprises sont une combinaison des architectures du tableau ci-dessous :
Type | Description | Exemple |
Centralisée | Un ordinateur unique héberge le traitement, les données, et donne accès aux utilisateurs. | Un PC qui n’est pas en réseau. |
Maître-esclave | Plusieurs terminaux passifs sont reliés à un ordinateur central. | Distributeur automatique de billets. |
Client-serveur | Un ensemble de stations clientes consomme les ressources d’un serveur. | Tous les sites Web et applications construits avec WordPress. |
Peer to peer | Chaque ordinateur du réseau est un client et un serveur. | Emule / Napster. |
Hormis la version purement centralisée, regardons le détail de ces 3 manières de déployer une architecture :
Le modèle maître-esclave conjugue les avantages d'une solution centralisée pour les données et traitements, et répartie pour les utilisateurs et matériels. L'exemple le plus parlant est le distributeur de billets de banque. En effet, quand vous allez retirer de l’argent, vous utilisez un ordinateur avec une interface assez simple ; tous les traitements se font ailleurs sur les serveurs de la banque.
Le modèle client-serveur a permis de répondre à ce besoin impérieux de souplesse. Ici, plusieurs ordinateurs (des clients) consomment les ressources d’un autre ordinateur (le serveur), qui peut contenir de la musique, des photos ou bien encore des fichiers Excel. Par exemple, la plupart des blogs que vous visitez sur Internet se comportent de cette façon.
Le modèle peer-to-peer (égal à égal) a pour objectif d’exploiter au maximum les capacités des stations des utilisateurs. Son rôle est à la fois d'être client et serveur. Les sites de téléchargement de musique en streaming comme Napster fonctionnent de cette manière.
Dans ces différents cas se pose la question de savoir si l’on doit centraliser ou répartir l’architecture. Je vous propose de voir rapidement les avantages et les inconvénients de chaque manière de procéder.
Centraliser ou répartir ?
Au niveau global, centraliser l’infrastructure a un impact sur la manière d’opérer le SI.
Avantages | Inconvénients |
Exploitation plus aisée | Risque du surincident. En cas de panne, le système entier risque d'être pénalisé |
Formation des opérateurs plus facile
|
|
Sécuriser est plus simple |
|
Comme nous l’avons vu, l’autre possibilité est de concevoir une architecture globale distribuée ou répartie.
Avantages | Inconvénients |
Mutualisation des matériels et des compétences | Administration de l’architecture plus complexe |
Modularité de l’architecture | Spectre de compétences plus large |
Amélioration du temps de réponse | Problématiques de sécurité plus élevées |
Et au niveau des briques fonctionnelles ?
Au niveau des données, l’approche centralisée permet de les stocker en un endroit unique. Cela facilite la maintenance, la disponibilité, la cohérence et l’intégrité des données.
L’approche distribuée permet :
un accès rapide à la donnée ;
l’amélioration de la sécurité en rendant la redondance possible.
Au niveau des utilisateurs, l’approche centralisée représente la meilleure manière de procéder pour connaître et identifier les utilisateurs. L'approche répartie induit un trop grand nombre de points d’entrée, qui grèvent la performance de l’organisation.
Au niveau des traitements, la centralisation assure une administration facilitée et une diminution du trafic réseau généré. L’approche distribuée est souvent nécessaire pour des raisons de puissance de calcul nécessaire, mais les développements sont aussi plus complexes à mener.
Évolution vers le distribué : la virtualisation et le Cloud
La diversité et la multiplicité des usages entraînent une complexification croissante de l’architecture. Par ailleurs, la plus grande richesse de contenu traitée par les applications a entraîné une augmentation de besoin en volume et en capacité de traitement.
Ces évolutions ont été permises par l’émergence rapide des techniques de virtualisation qui ont donné naissance au Cloud.
Mais de quoi s’agit-il exactement ?
Voyons ça en détail !
La virtualisation
Jusque dans les années 1990, les applications, les traitements et les données étaient hébergés sur des serveurs physiques. Ce terme désigne un ordinateur avec un système d’exploitation (comme Windows) équipé d’éléments de réseau pour pouvoir communiquer, et de logiciels pour offrir des services.
La virtualisation consiste à faire fonctionner plusieurs systèmes d’exploitation simultanément sur une seule machine physique.
Pour bien comprendre ce que c’est, on peut faire le parallèle avec le covoiturage. En comparant le système d’exploitation à un passager et le serveur à la voiture, il est aisé d’imaginer qu’un monospace avec 4 passagers est bien mieux utilisé que 4 citadines avec leur seul conducteur. Il consomme certes un peu plus, mais toujours moins que 4 automobiles.
Mais au fait, pourquoi on virtualise ?
La virtualisation offre de nombreux avantages :
Comme pour les voitures : on optimise l’espace, la consommation, la puissance !
L’administration des serveurs virtualisés est centralisée, et permet de gérer des parcs de machines virtuelles pouvant aller jusqu’à plusieurs milliers d’unités.
La disponibilité des plateformes virtualisées est souvent plus importante que celle de serveurs physiques équivalents, car ils sont sujets aux pannes.
La répartition de la charge de travail entre machines virtualisées est gérée de manière automatique.
Les infrastructures virtualisées sont beaucoup moins gourmandes en électricité et en climatisation qu’un ensemble de serveurs physiques. C’est important en cette période où nous devons faire des économies d’énergie pour protéger notre planète !
Le seul inconvénient de la virtualisation, c'est que le logiciel que l’on installe sur le serveur physique pour la rendre possible consomme environ 15 % de la puissance du serveur physique. À ce prix, pourquoi s’en priverait-on, hein ?
Comment applique-t-on la virtualisation au SI ?
Eh bien, grâce à ce procédé, les DSI sont en mesure de virtualiser l’ensemble des composants du SI : les applications, les systèmes, les systèmes de fichiers, le poste de travail client et les réseaux.
Cette partie nous a permis de comprendre ce qu’est la virtualisation. Les avantages qu’elle procure aux architectures sont tellement importants que la virtualisation a donné naissance à un nouveau modèle d’architecture : le Cloud Computing.
La tendance qui consiste pour les entreprises à adopter un mode de fonctionnement « Cloud » pour leur SI est une tendance de fond, qui transforme complètement le modèle économique d’exploitation du SI pour l’entreprise. Dans ce contexte, qu’est-ce que le cloud computing ? Quels sont les services offerts ? Quels en sont les enjeux ?
Prêt ? On y va !
Le Cloud Computing ou l’informatique en nuage
Le Cloud Computing est un modèle de consommation des ressources informatiques qui permet d’adapter la consommation aux besoins (à la demande) tout en s’affranchissant des contraintes matérielles et logicielles. On pourrait aussi dire, de manière plus simple, que c’est pouvoir utiliser des ressources informatiques sans les posséder.
On loue à la demande des serveurs à des fournisseurs externes comme Google avec Google Cloud Platform, OVH, Microsoft avec Azure, ou Amazon avec Amazon Web Services (les fameux AWS). Ces prestataires fournissent des services.
Pour bien comprendre la notion de services, prenons l’exemple de la musique. Avant l’avènement du Cloud, pour écouter votre morceau préféré, vous aviez besoin du CD, du lecteur muni de ses enceintes.
Aujourd’hui, un smartphone connecté à Internet suffit. On utilise un service qui remplace le matériel.
Pour résumer, on peut dire que le Cloud permet :
un service à la demande : c’est le client qui choisit le service de musique à la demande ;
un accès par le réseau : un smartphone connecté à Internet suffit pour écouter de la musique ;
une mutualisation des ressources : nous sommes des millions à utiliser les ressources de ce service ;
une flexibilité sur les ressources : votre bibliothèque musicale grandit ? Pas de souci, il suffit de demander pour obtenir plus d’espace ;
un service mesuré : le prestataire vous informe en temps réel de votre consommation, et donc de votre facturation !
Ces caractéristiques me rappellent quelque chose, pas vous ? Eh oui, la virtualisation des composants rend ces prodiges possibles, car elle permet de fournir le volume de stockage et la puissance de calcul de manière adaptée et instantanée.
Quels sont les différents types de services offerts par le Cloud ?
Les prestataires offrent 3 grands types de services que l’on peut schématiser ainsi : IaaS, PaaS et SaaS.
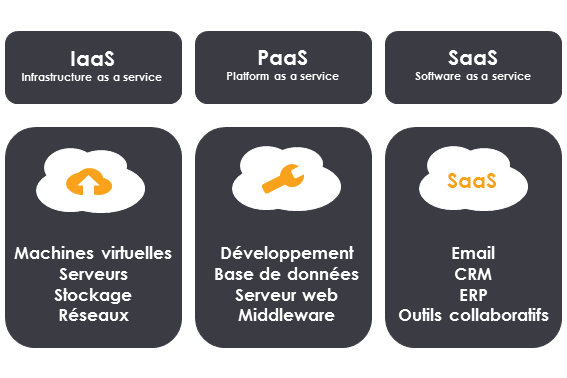
IaaS : l’infrastructure en tant que service
IaaS pour Infrastructure As A Service signifie Infrastructure en tant que service. Il s’agit du premier service que l’on rencontre dans le Cloud.
Pas besoin d’acheter un ensemble de matériel pour installer votre infrastructure, les entreprises se contentent de le louer. Très pratique pour disposer de serveurs de dernière génération et très rapidement disponibles.
Le fournisseur (AWS, Azure…) loue un parc informatique virtualisé créé et géré par lui-même dans son centre de données, à distance. Une couche logicielle de virtualisation sur les serveurs de son centre de données.
PaaS : plateforme en tant que service
Le deuxième service est le PaaS, pour Plateforme As A Service qui signifie Plateforme en tant que service.
Le fournisseur loue une plateforme permettant l'exécution complète d’applications comprenant un ensemble de machines virtuelles en réseau avec les outils pour la distribution des applications, le stockage, la sauvegarde, l’archivage, la surveillance la sécurité, etc.
Pour vous donner un exemple, les solutions DropBox ou Google Drive que vous utilisez certainement sont des solutions PaaS. Il s’agit de plateformes de stockage As A Service dans le Cloud.
SaaS : logiciel en tant que service
Enfin, le dernier service que proposent les acteurs du Cloud est le SaaS, Software As A Service, qui signifie Logiciel en tant que service.
Ici, le fournisseur loue une ou plusieurs applications accessibles au travers d'un simple navigateur Web. Par exemple, la solution de Google qui s’appelle Google Apps comprend des services professionnels de messagerie, de visioconférence, de stockage en ligne et d’édition de document bureautique. Microsoft offre le même niveau de service avec Office 365. En gros, vous n’utilisez plus les logiciels Word de façon physique (vous vous souvenez ? Il fallait installer via un CD-ROM Microsoft Office). Désormais, il vous suffit d’aller sur leur site.
Ce genre de service ouvre la perspective de SI accessibles en tout lieu, à tout moment et via n’importe quel appareil connecté (ordinateur, tablette, smartphone, téléviseur connecté, véhicule connecté…). Vous comprenez aisément que cela a un impact majeur sur le fonctionnement même des entreprises.
Maintenant que vous avez vu comment le SI est structuré par l’équipe de la DSI, je vous propose, dans le chapitre suivant, de découvrir les différents critères constituant l’infrastructure technique. Une fois le SI conçu, comment se construit l’infrastructure ? Quels critères sont pris en compte pour faire les choix ? Qui les fait ? Et pourquoi ?
En résumé
Un SI repose sur un ou plusieurs systèmes informatiques eux-mêmes composés de différents éléments, comme des ordinateurs et des équipements de communication.
Plusieurs types de déploiement sont possibles : centralisé ou réparti tant au niveau des traitements, des données, que des utilisateurs du SI.
La virtualisation permet de faire cohabiter sur un même serveur physique des systèmes d’exploitation différents.
La tendance majeure des dernières années consiste à distribuer les différents composants d’un système informatique comme le Cloud.
Les fournisseurs du Cloud proposent 3 services (IaaS, PaaS, Saas), et 4 déploiements types d’architecture Cloud sont possibles (privé, public, hybride et communautaire).
