Installation
Pour exécuter des applications Spark en local, il suffit de télécharger la version 3.0.0 compilée pour Hadoop 2.7 :
mkdir code
cd code/
wget http://apache.crihan.fr/dist/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
tar xzf spark-2.3.1-bin-hadoop2.7.tgzVous pouvez tester votre installation de Spark en exécutant le scriptwordcount.pyprésenté dans le chapitre précédent :
import sys
from pyspark import SparkContext
sc = SparkContext()
lines = sc.textFile(sys.argv[1])
word_counts = lines.flatMap(lambda line: line.split(' ')) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda count1, count2: count1 + count2) \
.collect()
for (word, count) in word_counts:
print(word, count)Créez également un fichier contenant quelques lignes de texte :
echo "Sur mes cahiers d'écolier Sur mon pupitre et les arbres Sur le sable de neige J'écris ton nom" > text.txt
echo "Sur les pages lues Sur toutes les pages blanches Pierre sang papier ou cendre J'écris ton nom" >> text.txt
echo "Sur les images dorées Sur les armes des guerriers Sur la couronne des rois J'écris ton nom" >> text.txtVous pouvez alors compter le nombre d'occurrences de chaque mot dans le fichiertext.txt:
$ ./spark-2.3.1-bin-hadoop2.7/bin/spark-submit ./wordcount.py ./text.txt
sable 1
cahiers 1
toutes 1
J'écris 3
dorées 1
ton 3
...Si, comme moi, vous trouvez que par défaut Spark émet trop de logs, vous pouvez réduire la quantité de logs émis en configurantlog4j. Pour cela, il suffit de créer un fichier de configuration approprié :
$ cp spark-2.3.1-bin-hadoop2.7/conf/log4j.properties.template spark-2.3.1-bin-hadoop2.7/conf/log4j.propertiesDans ce fichier, remplacez ensuite la lignelog4j.rootCategory=INFO, consoleparlog4j.rootCategory=ERROR, console. Seuls les logs d'un niveau de criticité supérieur ou égal à ERROR seront alors affichés dans la console.
Spark Shell
Pour prototyper des applications Spark, vous avez à votre disposition un interpréteur interactif, j'ai nommé : Spark Shell ! Spark Shell est disponible pour deux langages de programmation : Python et Scala. Vous pouvez accéder au Spark Shell en Python en exécutant :
$ ./bin/pysparkDe même, vous pouvez accéder au shell en Scala en exécutant :
$ ./bin/spark-shellVous noterez que, dans les deux langages, la variablescest déjà instanciée ; il s'agit duSparkContextde votre application.
Vous pouvez vous familiariser avec Spark Shell en reproduisantwordcountdans l'interpréteur, soit en Python, soit en Scala. Est-ce que vous remarquez que toutes les opérations s'exécutent instantanément jusqu'à l'appel à.collect()? Vous comprendrez pourquoi dans le prochain chapitre.
Architecture de l'environnement d'exécution
Jusqu'à présent, nous avons executé des applications Spark en local, et vous pensez peut-être que cela présente peu d'intérêt puisque nous cherchons à distribuer des calculs sur plusieurs machines. Cependant, vous n'aurez pas à réécrire vos applications locales avant de les distribuer sur plusieurs machines ; la couche d'abstraction que fournit Spark vous permet de ne pas vous soucier de l'architecture sur laquelle tourne votre application. Cela vous permet de prototyper des applications en local avant de les envoyer vers un cluster de plusieurs machines pour traiter des données de taille plus conséquente sans vous préoccuper du changement d'architecture. Vous pourrez donc utiliser votre environnement local pour déboguer vos applications distribuées, ce qui est tout de même bien pratique.
Par ailleurs, en arrière plan, Spark a en fait déjà parallélisé votre application si vous disposez de plusieurs cœurs sur votre processeur. Pour observer la différence de vitesse de traitement, exécutez les commandes suivantes :
$ # Utilisation de tous les cœurs disponibles
$ time ./bin/spark-submit ./wordcount.py ./text.txt
$ # Utilisation d'un seul cœur
$ time ./bin/spark-submit --master local[1] ./wordcount.py ./text.txtPour observer une différence notable, vous devrez utiliser un texte assez long. Je vous propose de télécharger l'Iliade, un des plus beaux poèmes au monde (et aussi un des plus longs) :
$ wget http://classics.mit.edu/Homer/iliad.mb.txtL'Iliade tient dans un fichier de 790 ko, ce qui n'est pas mal pour un poème, mais est loin d'être suffisant pour représenter un problème de Big Data. Je vous propose donc de travailler sur le texte de l'Iliade concaténé cent fois à lui-même :
$ for i in {1..100}; do cat iliad.mb.txt >> iliad100.txt; doneRéalisons un comptage de mots sur l'Iliade. Sur ma machine, qui dispose de 4 cœurs, voici les durées que j'observe pour chacune de ces deux commandes :
$ # 20.81 s
$ ./spark-2.3.1-bin-hadoop2.7/bin/spark-submit --master local[1] ./wordcount/wordcount.py ./iliad100.txt
$ # 14.83 s
$ ./spark-2.3.1-bin-hadoop2.7/bin/spark-submit --master local[4] ../spark/wordcount/wordcount.py ./iliad100.txtLa seconde commande est presque 30% plus rapide que la première.
Alors que fait l'option--masterque l'on passe à la commandespark-submit? Elle permet de préciser le type de cluster auquel l'application est soumise. Pour comprendre ce que fait cette option, il faut comprendre qu'un cluster Spark est composé de :
un ou plusieurs workers : chaque worker instancie un executor chargé d'exécuter les différentes tâches de calculs.
un driver : chargé de répartir les tâches sur les différents executors. C'est le driver qui exécute la méthode
mainde nos applications.un cluster manager : chargé d'instancier les différents workers.
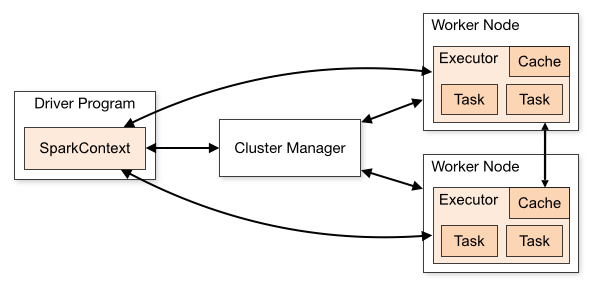 Source : Documentation de Spark
Source : Documentation de Spark
L'option--masterpermet de préciser à quel type de cluster manager l'application Spark peut être envoyée. Spark peut fonctionner en se connectant à des cluster managers de types différents :
--master spark://HOTE:PORT: utilise le cluster manager autonome de Spark.--master mesos://HOTE:PORT: se connecte à un cluster manager Mesos.--master yarn: se connecte à un cluster manager Yarn.--master local: pas de cluster manager, Spark fonctionne en mode local. Il est possible de spécifier le nombre d'executors dans le cluster en passant une valeur entre crochets :local[1]oulocal[4], par exemple.
Par défaut, si l'option--mastern'est pas spécifiée, Spark fonctionne en mode local avec un nombre d'executors égal au nombre de cœurs physique de la machine. Alors que si l'on spécifie--master local[1]un seul des quatre cœurs de la machine sera utilisé. C'est ce qui explique la différence de chronométrage que l'on a observée dans notre comptage de mots.
Comment choisir le bon cluster manager ? En local, vous n'aurez pas besoin d'instancier un cluster manager, le modelocalsuffira. Si vous disposez déjà d'un cluster manager Yarn ou Mesos, vous pouvez le réutiliser avec Spark. Et si ce n'est pas le cas, le cluster manager autonome de Spark sera tout à fait adapté.
Vous vous demandez peut-être à quoi sert le cluster manager puisqu'il y a déjà un driver dans cette architecture qui ressemble beaucoup à une architecture maître/esclave classique ? Le cluster manager est responsable de l'allocation des ressources, notamment lorsque plusieurs applications concurrentes sont exécutées sur le cluster Spark. Ce rôle d'allocation des ressources ne peut pas être confié au driver parce que le driver n'est responsable que de sa propre application.
Mais alors, comment le driver fait-il pour répartir les tâches entre les différents executors ? C'est la question à mille euros à laquelle nous allons répondre dans le prochain chapitre.
