Dans ce cours, jusqu'à présent on a uniquement vu comment lancer des applications distribuées en local... donc pas vraiment de manière distribuée. J'ai le plaisir de vous annoncer que le moment est venu de lancer des clusters de calcul complets ! Vous ne regretterez pas d'avoir attendu aussi longtemps.
Les machines que nous allons lancer se trouvent sur AWS. Il s'agit de machines EC2 (Elastic Cloud Compute) qui seront coordonnées par EMR (Elastic Map Reduce). Nous allons lancer grâce à EMR un cluster de calcul Spark. EMR se chargera d'instancier le driver, les workers, ainsi que le cluster manager (YARN). EMR nous fournira également des UI nous permettant de superviser notre cluster et l'exécution d'une application.
Création d'une paire de clés EC2
Nous allons lancer des machines EC2 : pour pouvoir accéder à ces machines il faudra utiliser une clé SSH qui sera stockée dans les instances lors de leur création. Il faut donc créer une paire de clés privée/publique. Peut-être disposez-vous déjà d'une clé SSH ? Dans ce cas vous avez la possibilité d'importer votre clé publique dans la console AWS.
Consultez la page dédiée à EC2 dans la console AWS et cliquez sur "Paires de clés" sous l'onglet "Réseau et sécurité". En cliquant sur "Créer une paire de clés" vous générez une clé privée que vous pouvez nommer et télécharger. Par exemple, chez moi, cette clé est stockée dans~/.ssh/regis-ec2-rsa.pem. Lors de la connexions aux machines EC2, il est un peu fastidieux de devoir spécifier à chaque fois la clé que vous voulez utiliser. Je vous suggère plutôt de créer un fichier~/.ssh/configsur votre machine qui contiendra la ligne suivante :
Host *.compute.amazonaws.com
IdentityFile ~/.ssh/regis-ec2-rsa.pemSi vous disposez déjà d'une clé SSH, vous pouvez importer la clé publique (surtout pas la clé privée !!!) en cliquant sur "Importer une paire de clés". À vous de configurer votre client SSH pour utiliser votre clé lors de la connexion aux machines.
Administration d'un cluster à partir de la console AWS
Commençons par consulter la page dédiée à EMR dans la console AWS. Faites bien attention à choisir la bonne région dans le coin supérieur droit : les tarifs varient légèrement d'une région à une autre, et il est important de choisir une région proche de vous pour des raisons de latence.
Cliquez sur "Créer un cluster" : vous accédez alors à la page de configuration de votre cluster de calcul. Commençons par lancer un cluster Spark doté de trois instances m3.xlarge, c'est à dire un driver et deux workers. Vous utiliserez une application Spark et la clé EC2 que vous avez créée juste avant. Voici à quoi ressemble la configuration de mon cluster :
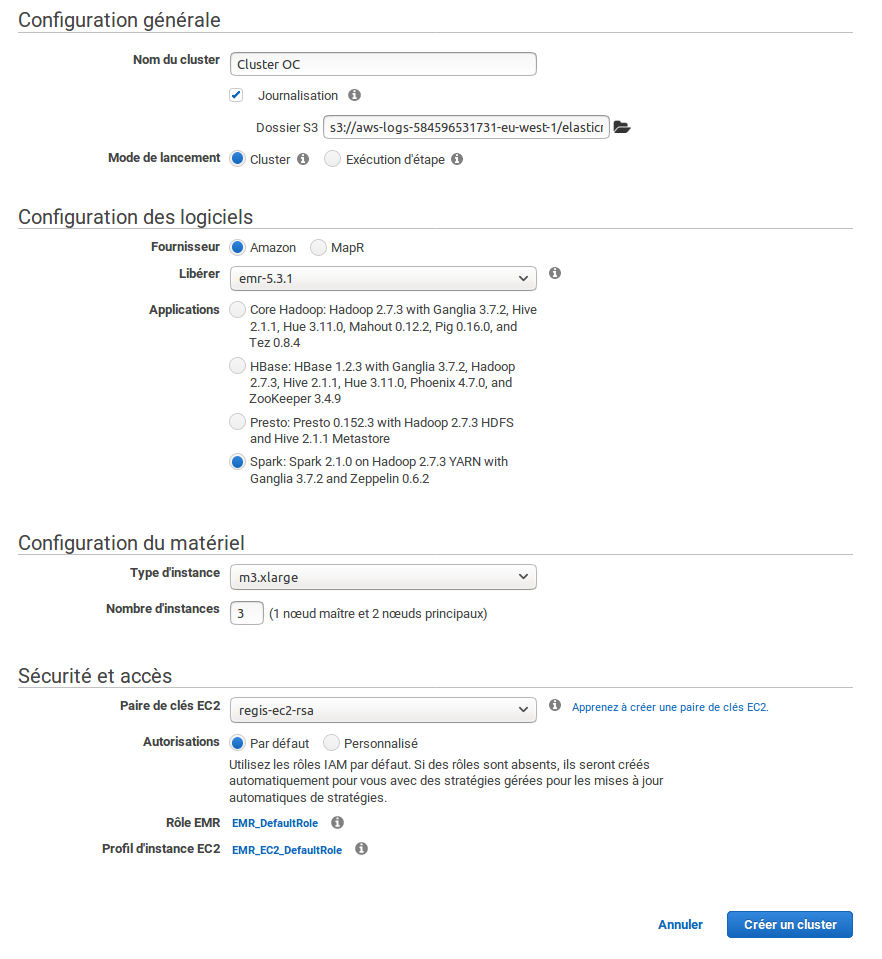
Je vous sens piaffer d'impatience... allez, on clique sur "Créer un cluster" ! Vous allez rire, mais il est possible que le lancement de votre cluster échoue à cause d'un bug d'AWS :-D Si vous recevez un message d'erreur indiquant des rôles manquants, re-créez simplement un nouveau cluster : les rôles auront automatiquement été créés entre-temps.
Le lancement des instances de votre cluster met quelques minutes. En attendant, vous pouvez préparer l'application Spark que vous souhaitez exécuter ainsi que les données associées. Je vous laisse deviner l'application que nous allons exécuter... vous ne voyez pas ? vraiment ?
$ cat wordcount.py
import sys
from pyspark import SparkContext
sc = SparkContext()
word_counts = sc.textFile(sys.argv[1])\
.flatMap(lambda line: line.split(' ')) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda count1, count2: count1 + count2) \
.takeOrdered(50, lambda (word, count): -count)
# Log results to S3
import json
import boto.s3, boto.s3.key
conn = boto.s3.connect_to_region("eu-west-1")
bucket = conn.get_bucket("oc-calculsdistribues")
key = boto.s3.key.Key(bucket, "words.txt")
key.set_contents_from_string(json.dumps(word_counts, indent=2))Vous avez reconnu notre application de comptage de mots ? Je pense que oui, ou alors vous êtes vraiment arrivés ici par hasard... La différence avec l'application telle qu'on l'a vue jusqu'à présent est que cette application écrit ses résultats dans un objet nomméwords.txtstocké dans le bucketoc-calculsdistribues. D'ailleurs, n'oubliez pas de modifier le nom du bucket utilisé dans l'application !
Nous allons stocker notre application Spark ainsi que les données associées sur S3 (n'oubliez pas de changer le bucket dans lequel vous stockez les données, là aussi) :
$ aws s3 cp wordcount.py s3://oc-calculsdistribues/
upload: ./wordcount.py to s3://oc-calculsdistribues/wordcount.py
$ aws s3 cp iliad.mb.txt s3://oc-calculsdistribues/
upload: ./iliad.mb.txt to s3://oc-calculsdistribues/iliad.mb.txtEst-ce que votre cluster de calcul est prêt ? Il devrait être indiqué comme "En attente" (en vert) dès qu'il est prêt ; la page indiquant le statut du cluster ne se met pas à jour toute seule ! Vous devez rafraîchir la page vous-mêmes.
Quand votre cluster sera prêt, vous allez rajouter une "Étape" à votre cluster : cette étape est une application Spark située dans votre bucket S3 à laquelle vous passez comme argument le chemin vers l'objet S3 contenant le texte de l'Iliade. Voici à quoi ressemble la configuration de l'étape sur mon cluster :
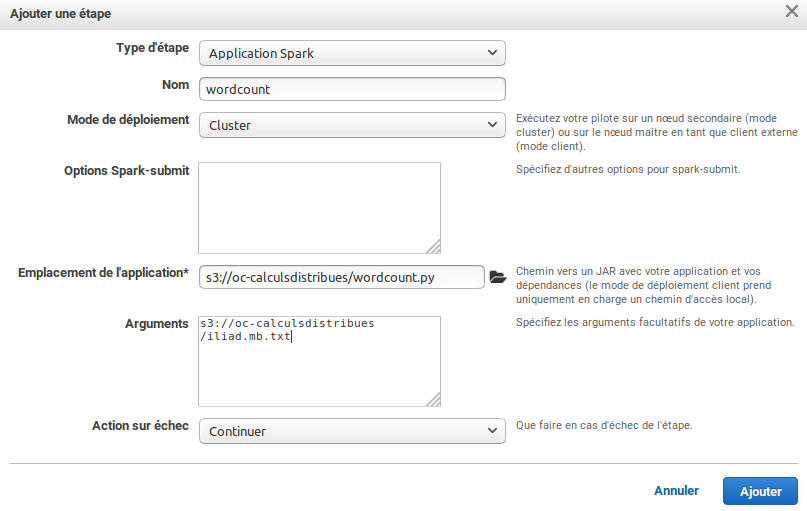
Une "étape" au sens d'AWS n'a rien à voir avec une étape au sens de Spark, que l'on a vue dans la partie précédente de ce cours. Une étape au sens d'AWS est plutôt une application à exécuter.
Vous pouvez visualiser la progression de l'étape dans la console AWS. Vous pouvez noter dans les propriétés de l'étape qu'elle a été lancée à l'aide de la commande suivante (cette commande nous sera utile par la suite) :
spark-submit --deploy-mode cluster s3://oc-calculsdistribues/wordcount.py s3://oc-calculsdistribues/iliad.mb.txtUne fois que l'étape est indiquée comme "terminée", vous pouvez vérifier qu'un fichierwords.txta bien été créé dans votre bucket. Vous pouvez le récupérer et vérifier qu'il contient bien les mots les plus fréquents de l'Iliade au format JSON :
$ aws s3 ls s3://oc-calculsdistribues
2017-03-02 18:37:00 808298 iliad.mb.txt
2017-03-02 20:16:39 539 wordcount.py
2017-03-02 20:19:17 1513 words.txt
$ aws s3 cp s3://oc-calculsdistribues/words.txt .
download: s3://oc-calculsdistribues/words.txt to ./words.txt
$ head -10 words.txt
[
[
"the",
9573
],
[
"and",
6481
],
[Administration d'un cluster en ligne de commande
Comme je vous le disais dans le chapitre précédent, toutes les fonctionnalités d'AWS sont disponibles via la ligne de commande. En particulier, vous pouvez lancer un cluster à l'aide de la commandeaws emr create-cluster. Dans la console AWS, sur la page consacrée à votre cluster, vous pouvez trouver un bouton "Exporter AWS CLI". Quand vous cliquez sur ce bouton, AWS vous fournit la ligne de commande à exécuter pour lancer votre cluster. Pour moi, cette commande est :
aws emr create-cluster \
--name 'Cluster OC' \
--instance-groups '[{"InstanceCount":1,"InstanceGroupType":"MASTER","InstanceType":"m3.xlarge","Name":"Master Instance Group"},{"InstanceCount":2,"InstanceGroupType":"CORE","InstanceType":"m3.xlarge","Name":"Core Instance Group"}]' \
--release-label emr-5.3.1\
--applications Name=Ganglia Name=Spark Name=Zeppelin \
--ec2-attributes '{"KeyName":"regis-ec2-rsa","InstanceProfile":"EMR_EC2_DefaultRole","SubnetId":"subnet-0a6a3b52","EmrManagedSlaveSecurityGroup":"sg-8817f2f1","EmrManagedMasterSecurityGroup":"sg-9517f2ec"}' \
--service-role EMR_DefaultRole \
--enable-debugging \
--log-uri 's3n://aws-logs-584596531731-eu-west-1/elasticmapreduce/' \
--configurations '[{"Classification":"spark","Properties":{"maximizeResourceAllocation":"true"},"Configurations":[]}]' \
--scale-down-behavior TERMINATE_AT_INSTANCE_HOUR \
--region eu-west-1En ajoutant cette commande à un scriptcreate-cluster.shvous pouvez rapidement lancer un nouveau cluster qui possède les mêmes propriétés que votre cluster précédent. Vous pouvez également facilement modifier les options telles que le nombre d'instances ou le nom du cluster.
Le résultat de la commande précédente vous fournit un identifiant de cluster. Muni de cet identifiant, vous pouvez soumettre une nouvelle étape à ce cluster grâce à la ligne de commande :
aws emr add-steps \
--cluster-id j-CLUSTERID \
--steps Type=SPARK,Name="YOUR APP NAME",Args=[--deploy-mode,cluster,s3://oc-calculsdistribues/wordcount.py,s3://oc-calculsdistribues/iliad.mb.txt]Cette commande vous fournit l'identifiant de l'étape. Vous pouvez dorénavant surveiller l'évolution de l'étape à l'aide de la commande :
aws emr describe-step --cluster-id CLUSTERID --step-id STEPIDEncore une fois, n'oubliez pas d'éteindre vos clusters quand vous n'en avez plus besoin ! Pour résilier vos clusters, vous pouvez exécuter :
aws emr terminate-clusters --cluster-ids CLUSTERID1 CLUSTERID2 ...Lancement d'un cluster éphémère
Nous avons mentionné dans le chapitre précédent que l'on pouvait lancer des clusters éphémères ; c'était même un des critères de choix en faveur de S3 par rapport à d'autres solutions de stockage. Cependant, jusqu'à présent, nous avons considéré des clusters qu'il fallait éteindre manuellement. Alors, comment faire en sorte qu'un clusteer s'éteigne automatiquement à la fin d'un calcul ? Vous pouvez lancer un cluster éphémère à partir de la console AWS en cliquant sur "Accéder aux options avancées" à partir de la page de création d'un cluster. Vous devez alors choisir les paramères suivants :
Applications : cochez Spark, Zeppelin, Ganglia.
Ajouter des étapes - Type d'étape : sélectionnez Application Spark (Il vous faut alors paramétrer votre étape comme précédemment).
Cochez "Résilier automatiquement le cluster après la fin de la dernière étape".
Désactivez "Protection de la résiliation".
Options de sécurité : sélectionnez votre clé EC2
La ligne de commande correspondant au lancement de ce cluster temporaire et à l'exécution de l'applicationwordcount.pyest la suivante :
aws emr create-cluster \
--name 'Cluster OC' \
--instance-groups '[{"InstanceCount":1,"InstanceGroupType":"MASTER","InstanceType":"m3.xlarge","Name":"Master Instance Group"},{"InstanceCount":2,"InstanceGroupType":"CORE","InstanceType":"m3.xlarge","Name":"Core Instance Group"}]' \
--release-label emr-5.3.1\
--applications Name=Ganglia Name=Spark Name=Zeppelin \
--ec2-attributes '{"KeyName":"regis-ec2-rsa","InstanceProfile":"EMR_EC2_DefaultRole","SubnetId":"subnet-0a6a3b52","EmrManagedSlaveSecurityGroup":"sg-8817f2f1","EmrManagedMasterSecurityGroup":"sg-9517f2ec"}' \
--service-role EMR_DefaultRole \
--enable-debugging \
--log-uri 's3n://aws-logs-584596531731-eu-west-1/elasticmapreduce/' \
--configurations '[{"Classification":"spark","Properties":{"maximizeResourceAllocation":"true"},"Configurations":[]}]' \
--scale-down-behavior TERMINATE_AT_INSTANCE_HOUR \
--region eu-west-1 \
--steps '[{"Args":["spark-submit","--deploy-mode","cluster","s3://oc-calculsdistribues/wordcount.py","s3://oc-calculsdistribues/iliad.mb.txt"],"Type":"CUSTOM_JAR","ActionOnFailure":"CONTINUE","Jar":"command-runner.jar","Properties":"","Name":"Wordcount"}]' \
--auto-terminateEn fait, les seules différences avec la commandecreate-clusterprécédente concerne l'ajout des options--stepset--auto-terminate.
Notez cependant que le lancement d'un cluster, éphémère ou pas, nécessite quelques minutes. Pour un calcul nécessitant d'obtenir les résultats immédiatement, il vaut mieux utiliser un cluster existant plutôt que de lancer un nouveau cluster.
Bootstrapping
Dans notre application du chapitre précédent qui analyse l'Iliade et l'Odyssée nous avons utilisé une dépendance externe sous la forme d'un package à installer avant d'exécuter notre application. Nous avons également dû télécharger une liste de "stopwords" :
$ pip install nltk
$ python -c "import nltk; nltk.download('stopwords')"Nous aurons besoin de répéter ces étapes sur les workers de notre cluster avant de pouvoir y exécuter notre application. Pour cela, nous devrons exécuter un script au démarrage de nos workers qui installera les dépendances nécessaires. Ce genre d'action est appelée bootstrapping, ou amorçage en français.
Pour ajouter un script d'amorçage au lancement de notre cluster, il suffit d'ajouter une option--bootstrap-actionà votre commandeaws emr create-cluster:
aws emr create-cluster \
...
--bootstrap-action Path=s3://oc-calculsdistribues/bootstrap-emr.shVous pourriez même ajouter des arguments à votre script d'amorçage :
aws emr create-cluster \
...
--bootstrap-action Path=s3://oc-calculsdistribues/bootstrap-emr.sh,Args=[arg1,arg2]Il nous reste à créer et à ajouter sur S3 ce script d'amorçage :
$ cat bootstrap-emr.sh
#! /bin/bash
pip install --user nltk
python -c "import nltk; nltk.download('stopwords')"
sudo ln -s /home/hadoop/nltk_data /usr/share/nltk_data
$ aws s3 cp bootstrap-emr.sh s3://oc-calculsdistribues/
upload: ./bootstrap-emr.sh to s3://oc-calculsdistribues/bootstrap-emr.shEt vous pourrez alors exécuter des applications qui requièrentnltk.
Lancement d'une application à partir du driver
Il reste à voir une dernière modalité de lancement d'une application : nous ne sommes pas obligés de passer par l'API d'AWS pour lancer des applications Spark. Après tout, nous avons le contrôle des serveurs, donc rien ne nous empêche de nous connecter directement au driver du cluster pour y soumettre nos applications.
Pour cela, il faudra que l'on se connecte en SSH au driver de notre cluster. Par défaut, ce driver se situe derrière un firewall qui bloque l'accès en SSH. Pour ouvrir le port 22 qui correspond au port sur lequel écoute le serveur SSH, il faut modifier le groupe de sécurité EC2 du driver. Sur la page de la console consacrée à EC2, dans l'onglet "Réseau et sécurité", cliquez sur "Groupes de sécurité". Vous allez devoir modifier le groupe de sécurité deElasticMapReduce-Master. Dans l'onglet "Entrant", ajoutez une règle SSH dont la source est "N'importe où" (ou "Mon IP" si vous disposez d'une adresse IP fixe).
Les groupes de sécurité deElasticMapReduce-Masterdoivent être similaires à la capture d'écran suivante :
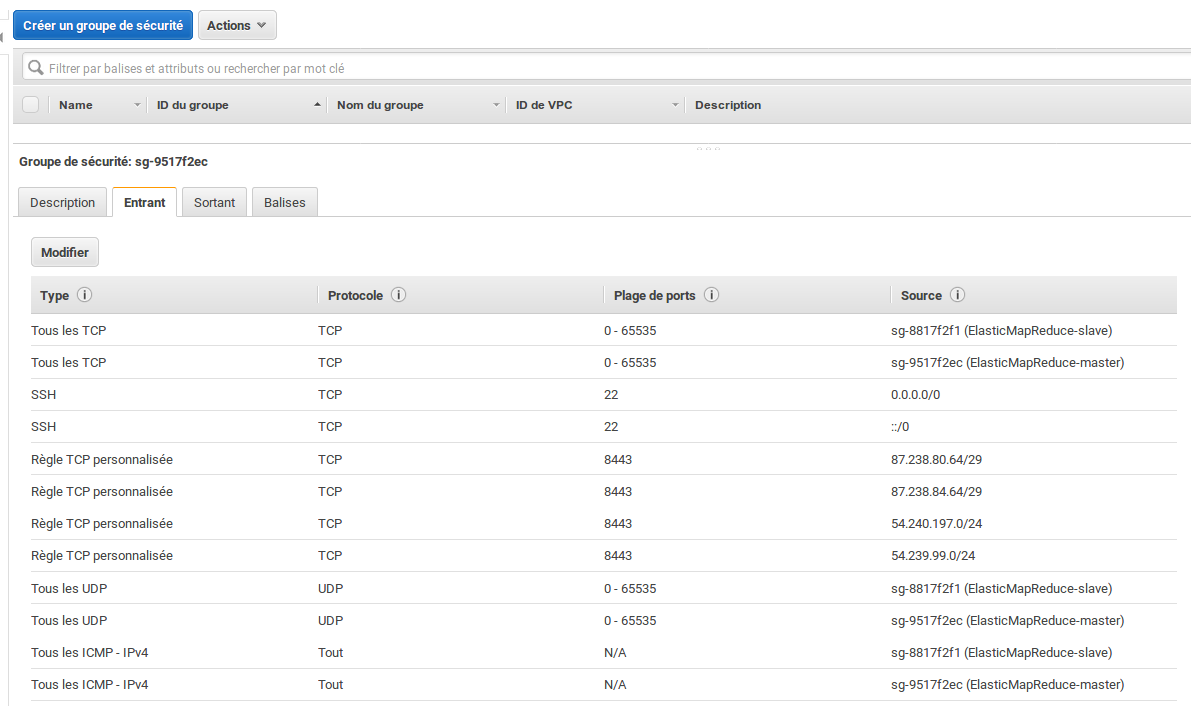
Vous pouvez vérifier que le groupe de sécurité a été correctement modifié en vous connectant au driver d'un cluster, existant ou nouveau. L'URL du driver est indiquée dans la page du cluster avec l'indication "DNS public principal".
Cette URL peut également être obtenue en exécutant la commande :
$ aws emr describe-cluster --cluster-id CLUSTERIDVérifiez que le serveur est joignable sur le port 22 :
$ telnet ec2-34-250-48-226.eu-west-1.compute.amazonaws.com 22Si vous avez correctement configuré votre client SSH, comme indiqué au début de ce chapitre, vous pouvez alors vous connecter avec l'utilisateurhadoop:
$ ssh hadoop@ec2-34-250-48-226.eu-west-1.compute.amazonaws.com
The authenticity of host 'ec2-34-250-48-226.eu-west-1.compute.amazonaws.com (34.250.48.226)' can't be established.
ECDSA key fingerprint is SHA256:eYgEgvKjkewJprT4XO1MldJ0pImm7VWKQ09wPpkvNkg.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'ec2-34-250-48-226.eu-west-1.compute.amazonaws.com,34.250.48.226' (ECDSA) to the list of known hosts.
Last login: Thu Mar 2 21:07:55 2017
__| __|_ )
_| ( / Amazon Linux AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2016.09-release-notes/
14 package(s) needed for security, out of 20 available
Run "sudo yum update" to apply all updates.
EEEEEEEEEEEEEEEEEEEE MMMMMMMM MMMMMMMM RRRRRRRRRRRRRRR
E::::::::::::::::::E M:::::::M M:::::::M R::::::::::::::R
EE:::::EEEEEEEEE:::E M::::::::M M::::::::M R:::::RRRRRR:::::R
E::::E EEEEE M:::::::::M M:::::::::M RR::::R R::::R
E::::E M::::::M:::M M:::M::::::M R:::R R::::R
E:::::EEEEEEEEEE M:::::M M:::M M:::M M:::::M R:::RRRRRR:::::R
E::::::::::::::E M:::::M M:::M:::M M:::::M R:::::::::::RR
E:::::EEEEEEEEEE M:::::M M:::::M M:::::M R:::RRRRRR::::R
E::::E M:::::M M:::M M:::::M R:::R R::::R
E::::E EEEEE M:::::M MMM M:::::M R:::R R::::R
EE:::::EEEEEEEE::::E M:::::M M:::::M R:::R R::::R
E::::::::::::::::::E M:::::M M:::::M RR::::R R::::R
EEEEEEEEEEEEEEEEEEEE MMMMMMM MMMMMMM RRRRRRR RRRRRR
[hadoop@ip-172-31-42-255 ~]$On dirait que ça marche :-)
Notez qu'une fois sur le cluster, vous avez encore accès à la commandeawsà laquelle vous êtes maintenant habitués :
$ aws s3 ls
2017-03-02 17:20:52 aws-logs-584596531731-eu-west-1
2017-03-02 16:17:22 oc-calculsdistribuesVous pouvez donc récupérer l'applicationwordcount.pyet la lancer à l'aide despark-submitsur les données stockées sur S3 :
$ spark-submit ./wordcount.py s3://oc-calculsdistribues/iliad.mb.txtNotez que vous pouvez à nouveau supprimer la section de l'application qui concerne l'écriture sur S3 et la remplacer par des appels àprint, puisque les logs sont alors affichés dans la console :
for word, count in word_counts:
print word, countStockage de données sur HDFS
Dans une application Spark exécutée sur un cluster EMR, les fichiers contenant des données ne sont pas chargés à partir du système de fichier local, mais à partir d'HDFS, le système de fichier distribué d'Hadoop. Cela signifie que lorsque vous écrivezsc.textFile("/home/somefile.txt"),somefile.txtest alors chargé à partir du répertoire/homede HDFS. Donc n'oubliez pas de transférer vos fichiers vers HDFS si vous utilisez cette méthode ! Nous verrons plus en détails dans un cours ultérieur comment utiliser HDFS ; en attendant, sachez que vous pouvez utiliser les commandes suivantes à partir du driver Spark :
$ hadoop fs -ls /
$ hadoop fs -mkdir /home
$ hadoop fs -mkdir /home
$ hadoop fs -copyFromLocal somefile.txt /home/Notez que ceci ne concerne pas les applications pour lesquelles les données sont chargées via S3, par exemple en écrivant :sc.textFile("s3://monbucket/monfichier.txt"). Cependant, vous voudrez parfois stocker les données directement sur votre cluster dans certains cas, par exemple pour accélérer le chargement des données.
