Comme nous l’avons vu dans le chapitre précédent, nous voulons nous assurer que notre modèle ne souffre pas de sur-apprentissage, et qu’il saura faire des prédictions sur de nouvelles données
Comment peut-on mesurer la performance d’un modèle sur des données inconnues ?
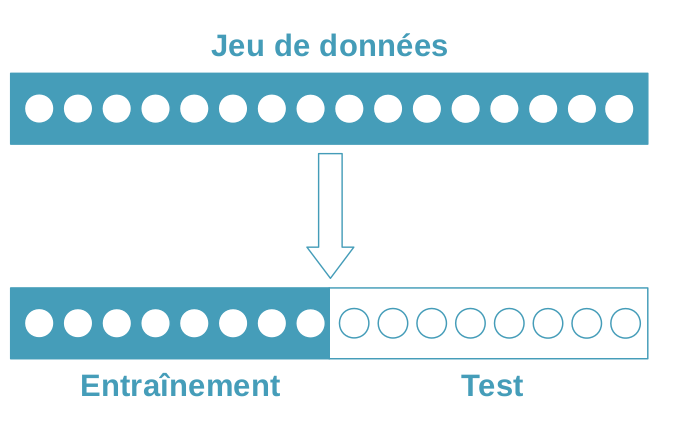
Jeux d’entraînement et de test
La première idée, c’est de couper notre jeu de données en deux parties : un jeu d'entraînement, et un jeu de test. On n’utilise ensuite pas du tout le jeu de test quand on choisit et qu’on entraîne notre modèle. Comme ça, on peut calculer la performance sur le jeu de test, et le résultat est une bonne approximation de la performance sur des données inconnues.
Validation croisée
C’est dommage, nous n’avons utilisé qu'une partie du jeu de données pour entraîner, et qu'une partie pour tester ! Et si nous avions par hasard créé un jeu de test vraiment difficile — ou vraiment facile — à prédire ? L’estimation de la performance serait biaisée !
Par ailleurs, moins on a de données, moins bien on apprend. Ne sommes-nous donc pas en train de créer des modèles moins bons, juste pour pouvoir les valider ?
La validation croisée va nous permettre d’utiliser l'intégralité de notre jeu de données pour l’entraînement et pour la validation ! Voilà comment ça marche :
On découpe le jeu de données en k parties (folds en anglais) à peu près égales. Tour à tour, chacune des k parties est utilisée comme jeu de test. Le reste (autrement dit, l’union des k-1 autres parties) est utilisé pour l'entraînement.
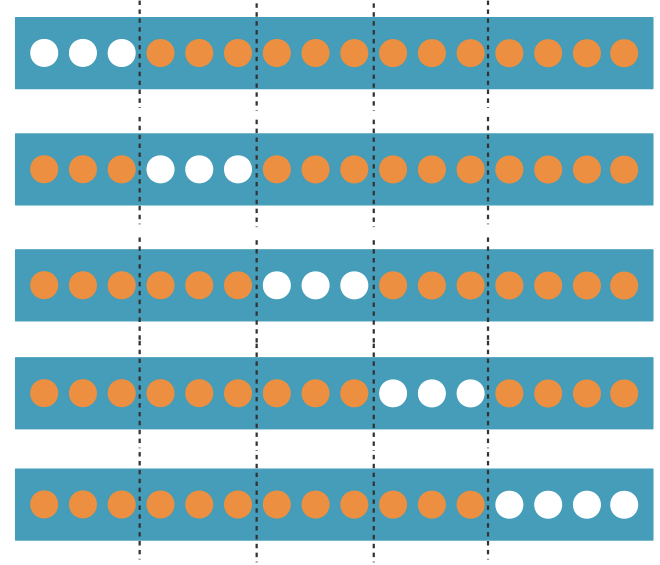
À la fin, chaque point (ou observation) a servi 1 fois dans un jeu de test, (k-1) fois dans un jeu d'entraînement. J'ai donc 1 prédiction par point de mon jeu initial, et aucune de ces prédictions n'a été faite avec un jeu d'entraînement qui contienne ce point. Je n'ai pas violé le principe de ne pas valider sur le jeu d'entraînement !
Je peux finalement rapporter la performance de mon modèle :
soit en évaluant les prédictions faites sur l’ensemble des données (puisque j’ai fait une prédiction par point du jeu de données complet) ;
soit en moyennant les performances obtenues sur les k folds, auquel cas je peux aussi rapporter l’erreur type, pour quantifier la variation de ces performances sur les k folds.
Entrée : données X (dimension nxp), étiquettes y (dimension n), nombre de folds k
Couper [0, 1, ..., n-1] en k parties de taille (n/k). (La dernière partie sera un peu plus petite si n n'est pas un multiple de k)
for i=0 to (k-1):
Former le jeu de test (X_test, y_test) en restreignant X et y aux indices contenus dans la i-ième partie.
Former le jeu d'entraînement (X_train, y_train) en restreignant X et y aux autres indices.
Entraîner l'algorithme sur le jeu d'entraînement
Utiliser le modèle ainsi obtenu pour prédire sur le jeu de test
Calculer l'erreur du modèle en comparant les étiquettes prédites aux vraies étiquettes contenues dans y_test
Sortie : la valeur moyenne des erreurs calculées sur les k folds.Stratification
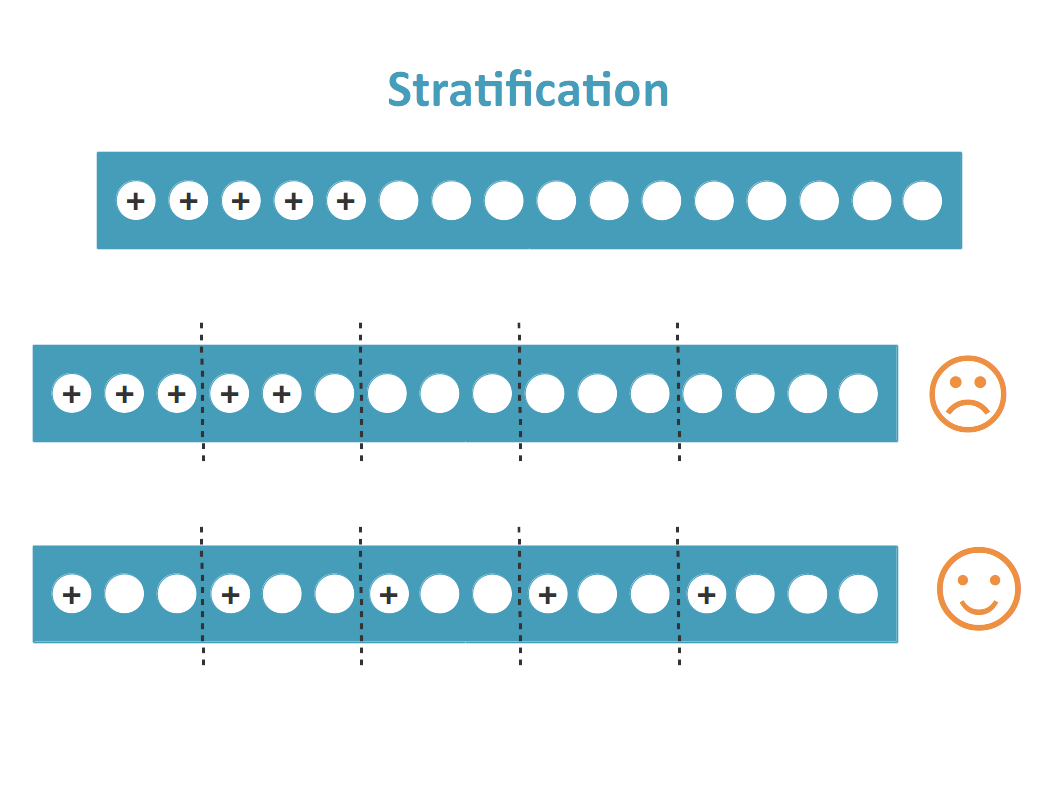
Dans le cas d’un problème de classification, on s’efforce généralement de créer les k folds de sorte à ce qu’elles contiennent à peu près les mêmes proportions d’exemples de chaque classe que le jeu de données complet. On cherche à éviter qu’un jeu d’entraînement ne contienne que des exemples positifs et que le jeu de test correspondant ne contienne que des exemples négatifs, ce qui va affecter négativement la performance du modèle !
Leave-one-out
Comment choisir le nombre de folds, k ?
Rappelez-vous, moins il y a de données disponibles pour l’entraînement, moins on est capable de bien apprendre. Or chaque fold contient points (si est la taille du jeu complet). Si on pousse ce raisonnement, on fait autant de folds que de points dans le jeu complet (c’est à dire n , et les jeux d’entraînement font quasiment la même taille que le jeu complet ! C’est ce qu’on appelle le leave-one-out (on ne laisse de côté qu’un seul exemple pour chaque jeu d’entraînement).
Ça a l’air bien ! Sauf que…
on augmente fortement le temps de calcul. Imaginez ça sur une base de données de 100 000 images ! Il faudrait entraîner 100 000 modèles sur 99 999 images chacun.
on forme ainsi des jeux d’entraînements très similaires entre eux, et des jeux de test très différents les uns des autres. On va avoir quasiment le même modèle sur chaque fold, et la qualité de ses prédictions risque de beaucoup varier. Il sera difficile de tirer des conclusions.
En résumé
Il ne faut jamais évaluer un modèle sur des points qui ont été utilisés pour l’entraîner.
On sépare donc les données entre un jeu d’entraînement, sur lequel on apprend le modèle, et un jeu de test, sur lequel on l’évalue.
Pour utiliser l’intégralité de nos données pour entraîner et pour tester, et pour éviter un biais potentiel lié au fait de faire une évaluation unique, on préfère faire une validation croisée.
Dans le cas d’un problème de classification, on fait attention à stratifier la validation croisée pour éviter d’introduire des biais.
