Certains modèles de classification retournent des valeurs réelles
Bien que le but d'un algorithme de classification soit de faire des prédictions binaires, un grand nombre d'algorithmes retournent un nombre réel. Plus cette valeur est élevée, plus le point est susceptible d'être positif. Dans de nombreux cas (régression logistique, méthodes bayésiennes, réseaux de neurones…), il s’agit d’ailleurs d’une estimation de la probabilité que ce point soit positif.
Dans ce cas, pour retourner une prédiction binaire, il faut seuiller : si le score retourné est supérieur au seuil, alors on prédit positif ; s’il est inférieur, on prédit négatif.
Mais quel seuil choisir ?
La courbe ROC
Dans le chapitre précédent, nous avons évoqué l’évaluation du rappel (ou sensibilité) et la spécificité d'un modèle de prédiction binaire. C’est ce que nous allons faire ici, pour chaque seuil de décision possible. Nous allons ensuite construire une courbe pour montrer comment la sensibilité évolue en fonction de la spécificité (en fait, de 1 moins la spécificité, que l'on appelle parfois antispécificité).
En bas à gauche de la courbe ROC, on prend la plus grande valeur prédite pour seuil, et on prédit donc que tous les points sont négatifs. En haut à droite, on prend la plus petite valeur prédite comme seuil, tous les points sont au-dessus et donc prédits positifs. Le reste de la courbe décrit toutes les situations intermédiaires.
Prenons un exemple pour mieux comprendre comment construire cette courbe. Nous avons 6 observations, pour lesquelles notre classifieur a retourné les scores suivants (j'ordonne ici les observations par leur score):
Étiquette | + | - | + | + | - | - |
Score | 0.99 | 0.95 | 0.51 | 0.45 | 0.10 | 0.01 |
Quels seuils pouvons nous considérer ? Nous pouvons commencer par une valeur supérieure à 0.99 : que l'on choisisse 1.0, 10.0 ou 42.7, toutes nos observations seront prédites négatives. Comme aucune observation n 'est prédite positive, notre sensibilité (qui est le taux de vrais positifs TP/P) est égale à 0, de même que l'antispécificité (qui est le taux de faux positifs FP/P).
Considérons ensuite un seuil entre 0.95 et 0.99. Seule la première observation est prédite positive. La sensibilité est donc de 1/3, et l'antispécificité reste nulle. Et ainsi de suite, comme résumé ici :
Seuil | > 0.99 | 0.95 - 0.99 | 0.51 - 0.95 | 0.49 - 0.51 | 0.10 - 0.45 | 0.01 - 0.10 | < 0.01 |
TP/P | 0 | 1/3 | 1/3 | 2/3 | 1 | 1 | 1 |
FP/P | 0 | 0 | 1/3 | 1/3 | 1/3 | 2/3 | 1 |
Et voilà la courbe ROC correspondante !
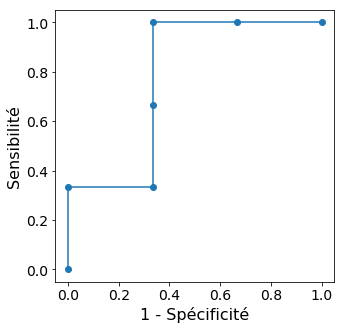
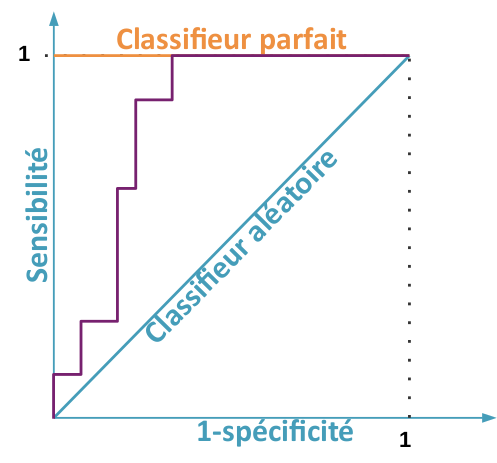
Un modèle parfait va systématiquement associer des valeurs plus faibles aux exemples négatifs qu’aux exemples positifs. La courbe ROC correspondante dessine donc le coin supérieur gauche du carré.
Un modèle aléatoire, par contraste, va dessiner la diagonale du carré : quelle que soit le seuil utilisé, comme le modèle est aléatoire, on aura la même proportion de prédictions positives correctes que de prédictions positives incorrectes. Le taux de faux positifs et le taux de vrais positifs seront donc égaux, et ainsi la sensibilité sera égale au complément à 1 de la sensitivité.
Traçons la courbe ROC du kNN utilisé à la fin du chapitre 1
y_pred_proba = clf.predict_proba(X_test_std)[:, 1]
[fpr, tpr, thr] = metrics.roc_curve(y_test, y_pred_proba)
plt.plot(fpr, tpr, color='coral', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('1 - specificite', fontsize=14)
plt.ylabel('Sensibilite', fontsize=14)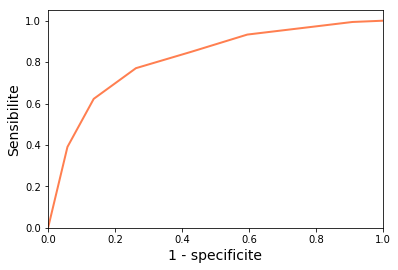
Autres courbes
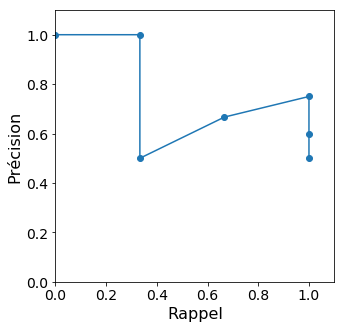
Une autre courbe fréquemment utilisée est la courbe précision-rappel (précision en ordonnée et rappel en abscisse), souvent appelée « PR curve ».
Reprenons notre exemple. Les valeurs de la précision (rapport du nombre de vrais positifs et du nombre de prédits positifs) et du rappel (égal à la sensibilité) sont les suivantes :
Seuil | > 0.99 | 0.95 - 0.99 | 0.51 - 0.95 | 0.49 - 0.51 | 0.10 - 0.45 | 0.01 - 0.10 | < 0.01 |
TP/P | 0 | 1/3 | 1/3 | 2/3 | 1 | 1 | 1 |
Précision | - | 1 | 1/2 | 2/3 | 3/4 | 3/5 | 3/6 |
Petit problème : pour le seuil le plus élevé, la précision n'est pas définie car aucune observation n'est prédite positive... Par convention, on choisira souvent une précision de 1 si la première observation à considérer est positive, et une précision de 0 sinon.
Voilà donc notre courbe précision-rappel :
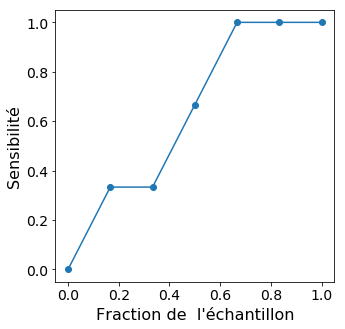
Enfin, la courbe lift, surtout utilisée dans le ciblage marketing, se construit aussi en parcourant le jeu de données ordonné par score. On représente en abscisse la fraction du jeu de données parcourue, et en ordonnée le taux de vrais positifs. Sur notre petit exemple, les valeurs à considérer sont donc :
Étiquette | + | - | + | + | - | - |
Fraction du jeu de données | 1/6 | 2/6 | 3/6 | 4/6 | 5/6 | 1 |
TP/P | 1/3 | 1/3 | 2/3 | 1 | 1 | 1 |
On obtient alors la courbe ci-dessous
Utiliser une courbe ROC
On peut résumer la courbe ROC par un nombre : "l'aire sous la courbe", aussi dénotée AUROC pour « Area Under the ROC », qui permet plus aisément de comparer plusieurs modèles.
Un classifieur parfait a une AUROC de 1 ; un classifieur aléatoire, une AUROC de 0.5
Revenons à l’exemple du vin portugais : l’aire sous la courbe ROC peut être calculée par :
print(metrics.auc(fpr, tpr))J’obtiens une AUROC de 0.815.
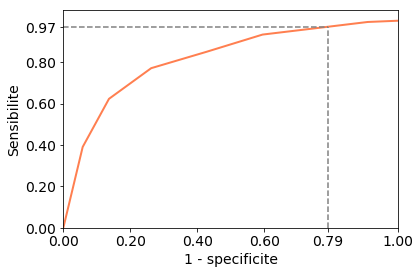
Comment choisir un seuil de décision à partir de cette courbe ? On se fixe soit la spécificité, soit la sensibilité que l'on désire, et on cherche le seuil correspondant.
Prenons l’exemple du vinho verde. Imaginons que l’algorithme doit être capable de détecter efficacement les vins de mauvaise qualité, qui ne seront pas ensuite examinés par un expert humain. On veut alors limiter le nombre de faux négatifs, pour limiter le nombre de rejets infondés. Fixons-nous un taux de faux négatifs tolérable (la proportion de positifs incorrectement prédits négatifs) de 5%. Cela équivaut à une sensibilité de 0.95 :
# indice du premier seuil pour lequel
# la sensibilité est supérieure à 0.95
idx = np.min(np.where(tpr > 0.95))
print("Sensibilité : {:.2f}".format(tpr[idx]))
print("Spécificité : {:.2f}".format(1-fpr[idx]))
print("Seuil : {:.2f}".format(thr[idx]))Utiliser un seuil de 0.29 nous garantit une sensibilité de 0.97 et une spécificité de 0.21, soit un taux de faux positifs de… 79%.
Résumé
De nombreux modèles de classification retournent des valeurs réelles, qui peuvent souvent être interprétées comme la probabilité que le point appartiennent à la classe positive.
Dans ce cas, il faut se fixer un seuil sur cette valeur réelle pour séparer les négatifs des positifs.
La courbe ROC permet de visualiser comment la spécificité et la sensibilité d’un modèle évolue en fonction de ce seuil.
L’AUROC permet de résumer la courbe ROC en un seul nombre : l’aire sous cette courbe.
