Les algorithmes de machine learning sont nombreux. Vous avez peut-être déjà entendu parler de régression linéaire, de kNN (algorithme des k plus proches voisins), de réseaux de neurones ou de random forests (forêts aléatoires). La plupart de ces algorithmes ont des hyperparamètres, comme le nombre k de voisins dans le kNN, qu’il faut se fixer.
Comment faire pour choisir l’algorithme et les hyperparamètres qui permettent de construire le modèle le plus adapté à mon problème ?
Naturellement, vous n’allez pas appliquer un algorithme de classification à un problème de régression. Vous n’allez pas non plus utiliser un algorithme qui s’applique à des données décrites par des nombres réels quand les vôtres sont décrites par des catégories (par exemple, une des variables que vous utilisez pour prédire quel film un client aimera est son genre, de fantastique à art et essai en passant par action). Mais cela ne va pas vous suffire pour choisir.
Ce que vous voulez vraiment, c’est construire un modèle qui vous donne de bons résultats. Mais qu’est-ce que ça veut dire, exactement ? C’est ce que nous allons voir.
Généralisation
Un bon modèle de machine learning, c’est un modèle qui généralise.
Qu’est-ce que c’est, déjà, la généralisation ?
La généralisation, c’est la capacité d’un modèle à faire des prédictions non seulement sur les données que vous avez utilisées pour le construire, mais surtout sur de nouvelles données : c’est bien pour ça que l’on parle d’apprentissage !
Pour vous donner un exemple un peu extrême, imaginez que vous vouliez catégoriser des images : certaines représentent des chats, d’autres non. Pour construire votre modèle, vous disposez d’un jeu de données de 500 images de chats, et 500 images qui ne sont pas des chats. Vous pouvez construire un algorithme très simple : pour classer une image, regarder pixel par pixel si elle est exactement identique à une de celles dans vos données. Si c’est le cas, retournez l’étiquette (chat ou pas-chat) associée. Dans le cas contraire, répondez au hasard. Cet algorithme marche très bien sur le jeu de données initial, mais n’a rien appris du tout : il ne sait pas faire de prédictions !
Sur-apprentissage et compromis biais-variance
Sans tomber dans le cas extrême que j’ai décrit plus haut, on peut facilement se retrouver sans le vouloir avec un modèle qui colle trop aux données sur lesquelles on apprend (aussi appelées "jeu d’entraînement"), et qui soit trop sensible à leurs moindres variations pour bien les représenter. Un tel modèle aura de très bonnes performances sur le jeu d'entraînement mais sera mauvais sur de nouvelles données. On parle alors de sur-apprentissage (overfitting en anglais).
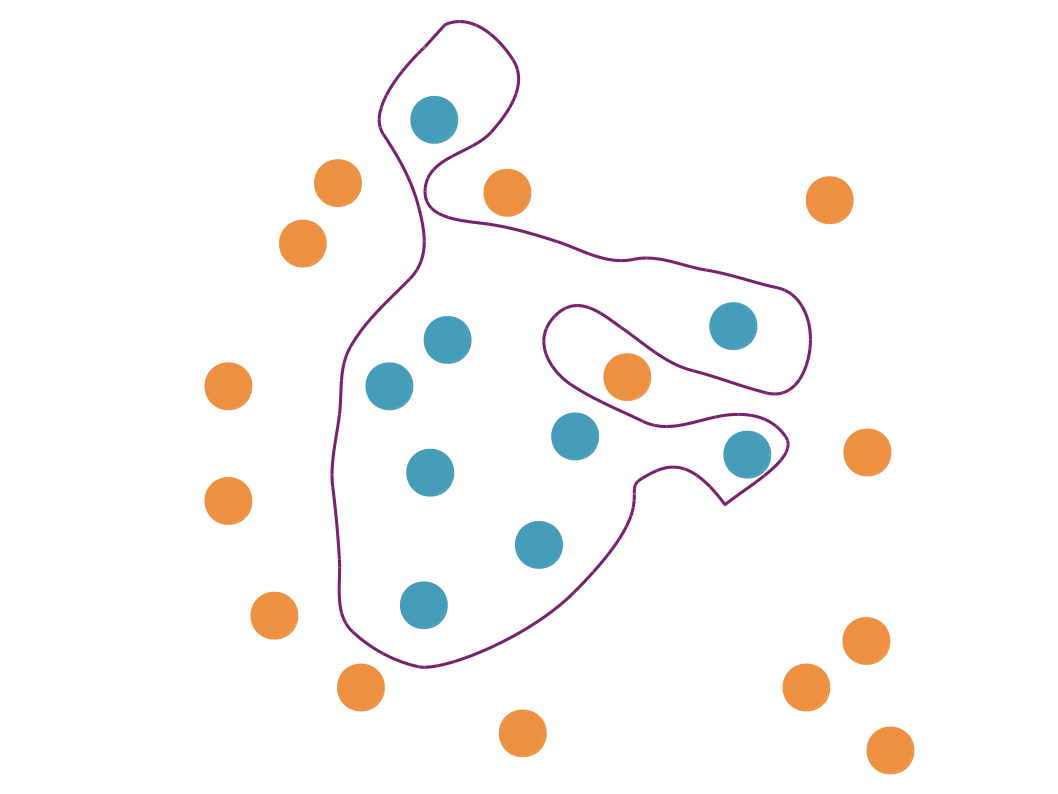
Un modèle qui sur-apprend est un modèle qui est trop complexe par rapport à la réalité qu’il essaie de représenter. Nous avons tendance à préférer des modèles simples ; c’est le principe du rasoir d’Ockham (ou Occam), selon lequel les hypothèses suffisantes les plus simples sont les plus vraisemblables. Par ailleurs, coller de trop près aux données est une mauvaise idée car elles sont inévitablement bruitées :
Par des erreurs de mesure (les appareils que nous utilisons pour mesurer les variables qui représentent nos données peuvent faire des erreurs techniques) ;
Par des erreurs d’étiquetage (l’erreur est humaine, et il se peut que certaines des étiquettes ne soient pas les bonnes) ;
Parce que nous n’avons pas mesuré les variables les plus pertinentes, soit parce qu'on ne les connaît pas, soit parce qu'elles sont très compliquées à mesurer.
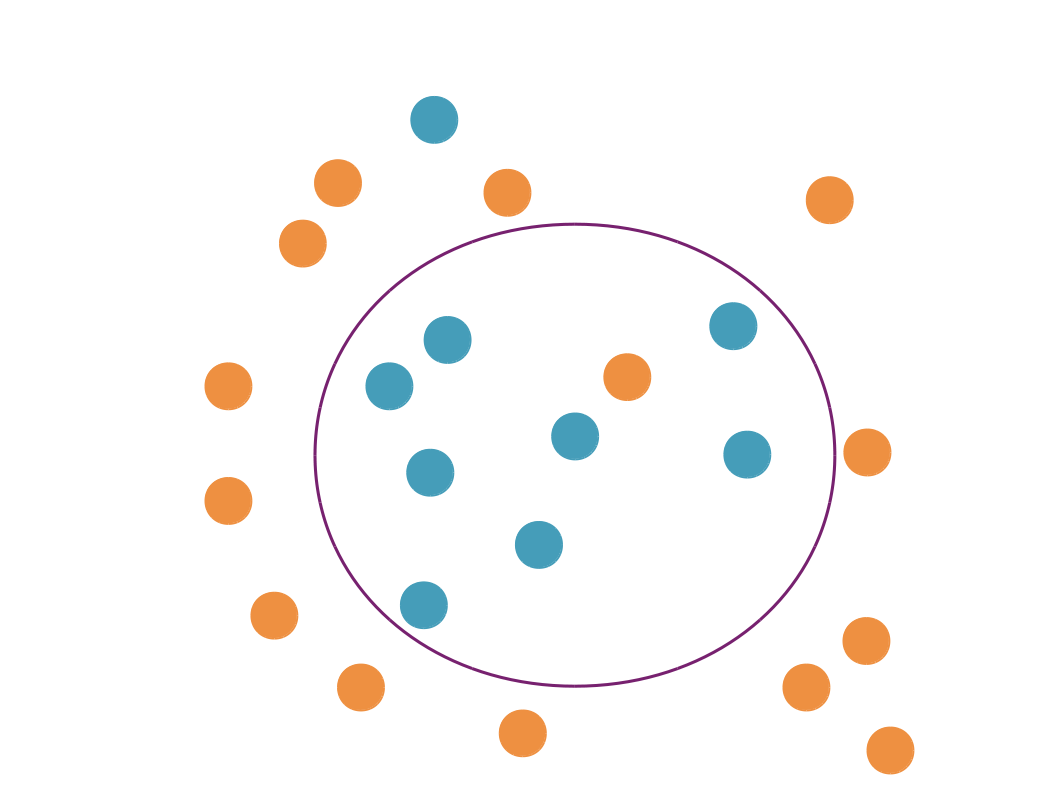
Il faut néanmoins aussi éviter les modèles trop simples, qui ne parviendront pas à bien représenter le phénomène qui nous intéresse, et qui ne feront pas de bonnes prédictions. On parle dans ce cas de "sous-apprentissage".
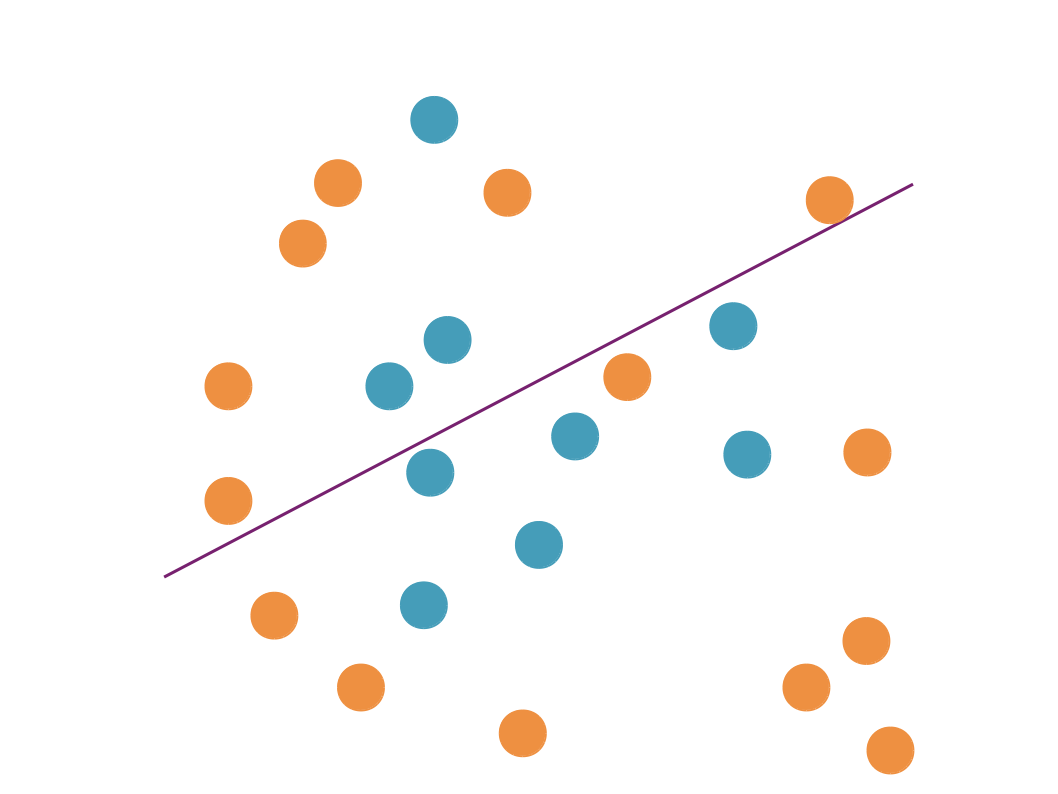
Le concept de compromis biais-variance nous permet de bien résumer la situation :
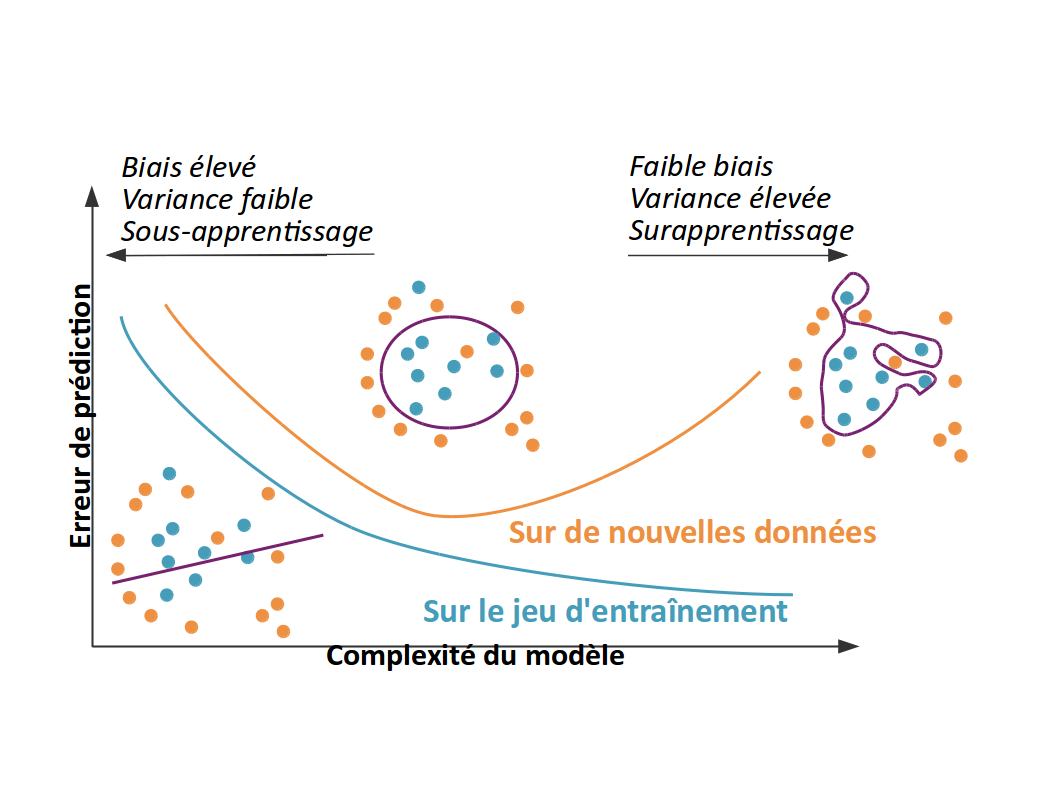
Compromis biais-variance : Un modèle simple (variance faible) risque le sous-apprentissage (biais élevé y compris sur les données d’entraînement). Un modèle complexe (variance élevée) risque le sur-apprentissage (biais faible sur les données d’entraînement mais élevé sur de nouvelles données). On souhaite trouver un modèle intermédiaire, vers le creux de la courbe orange, là où le biais de prédiction est le plus faible et la généralisation la meilleure.
Les problèmes mal posés
Pourquoi ne peut-on pas choisir a priori la complexité de notre modèle ?
En fait, toutes nos difficultés viennent du fait que les problèmes d'apprentissage sont des problèmes mal posés (ill-posed en anglais). Nous n'arrivons pas à les formuler de sorte à avoir une solution unique. Les données que nous observons ne sont pas suffisantes pour modéliser correctement le phénomène que nous cherchons à comprendre pour répondre à notre problématique, et nous devons rajouter des hypothèses (par exemple, que la frontière séparant les points bleus des points orange est un cercle) pour finalement arriver à un bon modèle. Ces hypothèses forment ce que l’on appelle le biais d’induction (inductive bias en anglais).
Ressources informatiques
Attention ! Vous pouvez être amenés à faire des compromis sur la complexité d’un modèle pour respecter des contraintes sur le temps de calcul (que ce soit pour l’entraînement ou pour la prédiction) ou les ressources en mémoire. Votre application nécessite-t-elle d’utiliser un modèle que vous devrez faire tourner pendant une heure pour produire une réponse, si un autre modèle peut vous donner une réponse de qualité légèrement inférieure en quelques secondes ?
En résumé
En apprentissage supervisé, le but est de produire des modèles qui généralisent, c’est-à-dire qui sont capables de faire de bonnes prédictions sur de nouvelles données
De bonnes performances sur le jeu d’entraînement ne garantissent pas que le modèle sera capable de généraliser !
On cherche à développer un modèle qui soit suffisamment complexe pour bien capturer la nature des données (et éviter ainsi le sous-apprentissage), mais suffisamment simple pour éviter le sur-apprentissage.
Attention aux contraintes de temps de calcul et aux ressources en mémoire !
