Dans le chapitre précédent, nous avons défini les critères que doivent remplir les clusters que l'on forme : nous cherchons à faire en sorte de séparer des clusters homogènes. Cependant, optimiser exactement une mesure comme le coefficient de silhouette ou l'index de Davies-Bouldin est très intensif en termes de temps de calcul. Nous sommes donc obligés d'adopter des heuristiques.
Dans ce chapitre, nous allons parler d'algorithmes de clustering hiérarchique, qui cherchent à créer des clusters homogènes bien séparés, par récurrence.
Partition hiérarchique des observations
Dans le cas du clustering agglomératif (ou bottom-up), on commence par considérer que chaque point est un cluster à lui tout seul. Ensuite, on trouve les deux clusters les plus proches, et on les agglomère en un seul cluster. On répète cette étape jusqu'à ce que tous les points appartiennent à un seul cluster, constitué de l'agglomération de tous les clusters initiaux.
L'approche inverse, le clustering divisif (ou top-down), consiste à initialiser avec un unique cluster contenant tous les points, puis à itérativement séparer chaque cluster en plusieurs, jusqu'à ce que chaque point appartienne à son propre cluster.
Dendrogrammes
Un dendrogramme est un arbre dont les feuilles sont les points d'un jeu de données. Chaque nœud de l'arbre représente un cluster (les feuilles sont des clusters contenant chacun un point). Les clusters qui ont le même parent sont agglomérés pour former ce cluster parent. La longueur des U est proportionnelle à la distance entre les deux clusters qu'ils connectent.
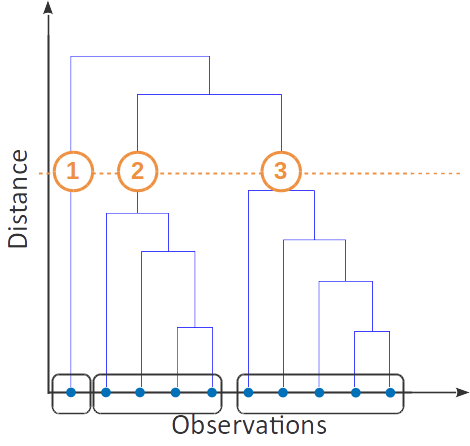
Pour les grands jeux de données, vous pourrez vous contenter de visualiser uniquement la partie supérieure du dendrogramme, pour éviter d'avoir à représenter tous les points.
Distance entre deux clusters
Mais comment calculer la distance entre deux clusters ? Il existe pour cela plusieurs méthodes, dites méthodes de lien (linkage methods) car elles permettent de lier les clusters entre eux.
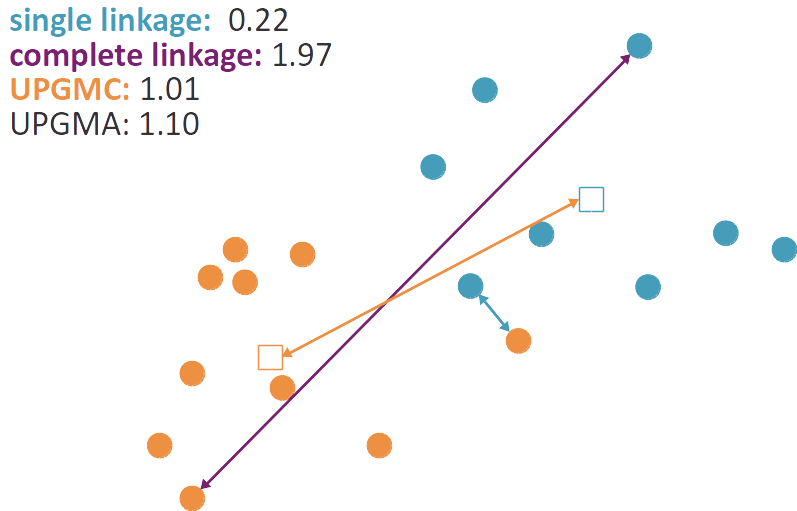
On peut dire que deux clusters sont proches si deux de leurs points sont proches. Ainsi, la distance entre deux clusters est la distance minimale entre deux points, l'un appartenant au premier cluster et l'autre au deuxième :
C'est ce qu'on appelle le lien simple, ou single linkage, en anglais.
Mais on peut préférer penser que deux clusters sont proches si tous leurs points sont proches les uns des autres. Ainsi, la distance entre deux clusters est la distance maximale entre deux points, l'un appartenant au premier cluster et l'autre au deuxième :
C'est ce qu'on appelle le lien complet, ou complete linkage, en anglais. On peut aussi définir le lien moyen, dans lequel la distance entre deux clusters est la distance moyenne entre toutes les paires de points deux à deux :
Cette dernière distance, le lien moyen, est aussi parfois appelée UPGMA, pour Unweighted Paired Group Method with Arithmetic mean. Elle contraste avec le lien centroïdal (centroid linkage), qui est non pas la moyenne des distances entre paires de points appartenant chacun à un des clusters, mais la distance entre les moyennes des points de chaque cluster, autrement dit la distance entre les deux centroïdes :
Le lien centroïdal est aussi appelé UPGMC, pour Unweighted Paired Group Method with Centroid.
Clustering de Ward
Les méthodes que je viens de présenter permettent de garantir la séparation des clusters : les points éloignés les uns les autres ne sont agglomérés dans le même cluster que tardivement. Mais quid de l'homogénéité ? Nous allons maintenant essayer d'agglomérer les clusters de sorte à maximiser l'homogénéité du résultat. Rappelez-vous la mesure d'homogénéité :
Si on utilise la distance euclidienne pour d, alors
Remplaçons dans cette équation ; l'idée est conceptuellement similaire, mais on mesure maintenant la variance du cluster (on parle aussi d'inertie).
La variance (ou inertie) intracluster d'un clustering est alors donnée par :
Le clustering de Ward est une méthode de clustering hiérarchique qui choisit, à chaque étape, d'agréger deux clusters de sorte à minimiser l'augmentation de la variance intracluster que cette agrégation entraîne.
Le clustering hiérarchique est implémenté dans le module Cluster de scikit-learn .
Avantages et inconvénients du clustering hiérarchique
Le clustering hiérarchique a l'avantage qu'il n'est pas nécessaire de définir le nombre de clusters à l'avance (on explore toutes les possibilités). Cependant, cela ne fait que repousser cette décision. Celle-ci peut se faire sur la base d'un dendrogramme (cela suppose de pouvoir bien visualiser le dendrogramme, ce qui sera plus aisé sur un petit jeu de données). On peut aussi évaluer les différentes partitions trouvées (une pour chaque valeur possible de nombre de clusters), avec une mesure telle que le coefficient de silhouette ou l'indice de Davies-Bouldin.
Par contre, sa complexité algorithmique est lourde. À chaque itération, pour décider quels clusters joindre, nous aurons besoin des distances deux à deux entre toutes les paires de points du jeu de données. Les calculer a un coût quadratique en temps de calcul ; les stocker, un coût quadratique en espace mémoire. Pour cette raison, le clustering hiérarchique est plus adapté aux échantillons contenant un faible nombre d'individus.
Résumé
Le clustering hiérarchique permet de partitionner un jeu de données de manière hiérarchique.
À chaque étape, on agrège les deux clusters les plus proches.
La distance entre clusters peut être calculée de plusieurs manières :
Lien simple : la distance entre deux clusters est la distance entre les deux points les plus proches.
Lien complet : la distance entre deux clusters est la distance entre les deux points les plus éloignés.
Lien centroïdal : la distance entre deux clusters est la distance entre les deux centroïdes.
Lien moyen : la distance entre deux clusters est la distance moyenne entre les points des deux clusters.
Clustering de Ward : la distance entre deux clusters est calculée de façon à minimiser la variance intracluster.
On peut visualiser une partition hiérarchique des données avec un dendrogramme.
