Dans le chapitre précédent, nous avons vu que la régularisation permet d'éviter le sur-apprentissage d'une régression linéaire en rajoutant à la fonction objective (la somme des carrés des erreurs) un terme de régularisation qui mesure la complexité du modèle.
Régularisation de Tykhonov
La régularisation de Tykhonov est un cas particulier de régularisation, dans lequel on utilise pour régulariser la régression linéaire le carré de la norme du vecteur de poids .
Plus précisément, il s'agit de la norme , ou norme euclidienne, c'est-à-dire
Nous avons donc maintenant le problème d'optimisation suivant :
que l'on peut aussi écrire
Le modèle linéaire que l'on apprend en résolvant cette équation est appelé régression ridge, ou ridge regression en anglais.
Solution de la régression ridge
La fonction à minimiser est encore une fois une forme quadratique. Comme dans le cas de la méthode des moindres carrés (régression linéaire non régularisée), nous pouvons résoudre ce problème d'optimisation en annulant le gradient en de la fonction objective :
Encore une fois, il s'agit du gradient d'une forme quadratique, qui se calcule de manière analogue à la dérivée d'un polynôme de degré 2 :
Ce qui nous donne
Or si , la matrice est toujours inversible !
La régression ridge admet donc toujours une unique solution explicite :
Importance de la standardisation des variables
Que se passe-t-il si l'on multiplie la variable par une constante ? Regardons tout d'abord le cas de la régression linéaire sans régularisation. La solution de la régression linéaire vérifie
Maintenant, si j'appelle la matrice obtenue en remplaçant par dans , la solution de la régression linéaire qui explique comme une fonction linéaire de vérifie . On a donc ce dont on peut conclure que Ainsi, multiplier une variable par une constante équivaut à diviser le poids correspondant par la même constante.
Dans le cas de la régression ridge, cependant, l'effet de la multiplication de par une constante dépend aussi du terme de régularisation , et est bien moins clair.
Pour cette raison, l'échelle de la plage des valeurs prises par les différentes variables a un impact sur le résultat de la régression ridge (mais pas sur celui de la régression non régularisée). Pour cette raison, je vous recommande fortement de standardiser les variables avant d'apprendre une régression ridge. Il s'agit de faire en sorte que chaque variable ait un écart-type de 1, en leur appliquant la transformation suivante :
Cette transformation est implémentée dans sklearn.preprocessing.StandardScaler.
Chemin de régularisation
Comment la solution de la régression ridge évolue-t-elle en fonction du coefficient de régularisation ? Si est très grand, alors la régularisation prend le dessus, le terme d'erreur n'importe plus et la solution est . À l'inverse, si est très faible, le terme de régularisation n'est plus utilisé, et on retrouve la solution de la régression linéaire non régularisée.
On peut visualiser l'effet que la valeur du coefficient de régularisation a sur chaque variable en affichant la valeur des différents coefficients en fonction de quand décroît. Le résultat s'appelle le chemin de régularisation.
En pratique, on choisira la valeur optimale du coefficient de régularisation entre ces deux extrêmes (solution nulle et solution de la régression non régularisée) par validation croisée.
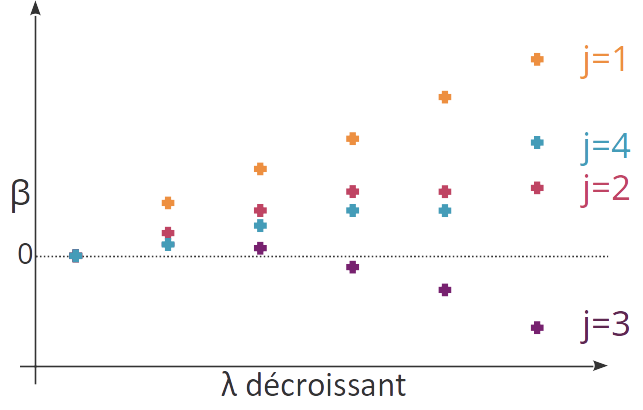
Un des effets de la régression ridge, que l'on peut observer sur le schéma entre les variables j=2 et j=4, est de grouper les variables corrélées, en leur affectant des coefficients similaires. Là où la régression non régularisée peut « répartir » le poids affecté à un groupe de variable corrélées de plusieurs façons, la régression régularisée les répartit de manière homogène.
Conclusion
La norme ℓ2 du vecteur de poids peut être utilisée comme terme de régularisation de la régression linéaire.
Cela s'appelle la régularisation de Tykhonov, ou régression ridge.
La régression ridge admet toujours une solution analytique unique.
La régression ridge permet d'éviter le surapprentissage en restraignant l'amplitude des poids.
La régression ridge a un effet de sélection groupée : les variables corrélées ont le même coefficient.
La régression ridge est implémentée dans scikit-learn : linear_model.Ridge.
linear_model.RidgeCVpermet de déterminer la valeur optimale du coefficient de régularisation par validation croisée.
