Prédire linéairement l'appartenance à une classe
Nous allons maintenant nous intéresser à des problèmes de classification binaire. Nos données sont toujours points en dimensions, représentés par la matrice mais leurs étiquettes, représentées par un vecteur représentent maintenant l'appartenance (1) ou non (0) à une classe.
Par exemple, les variables peuvent représenter le niveau de gris des pixels d'une image, et on peut disposer de images étiquetées en fonction de si elles représentent ou non un panda. Comment créer un modèle linéaire qui prédise si une image représente ou non un panda ?
Nous savons déjà (voir le chapitre Trouvez une combinaison linéaire de variables qui approxime leurs étiquettes de ce cours) résoudre des problèmes de régression linéaire. Peut-on utiliser cette base pour résoudre ce problème ?
Application directe de la régression linéaire
Dans un problème de régression, les étiquettes sont à valeurs dans . 0 et 1 sont des éléments de Peut-on utiliser directement une régression linéaire ?
Le problème de cette approche est que beaucoup de points de coordonnées différentes doivent avoir la même étiquette exactement : pour tous les points positifs. Une fonction linéaire n'est pas le bon outil pour cela…
Transformation d'une fonction linéaire en probabilité
Très bien, s'il faut que les points positifs puissent avoir des valeurs différentes les unes des autres, et pareil pour les points négatifs, peut-on essayer de prédire un nombre proche de 1 pour les points positifs, et un nombre proche de 0 pour les points négatifs ?
D'accord, mais « proches » et « différents » comment ? Cela ressemble de plus en plus à une probabilité : et si l'on essayait plutôt de prédire ?
Il nous reste encore quelques problèmes :
Une probabilité est comprise entre 0 et 1. Une fonction linéaire, à moins d'être constante, va nous sortir des nombres entre −∞ et + ∞ .
Les probabilités ne se comportent pas linéairement : on voudrait une fonction qui varie peu près de 0 et près de 1, et plus fortement près de 0.5.
Pour résoudre ces problèmes, nous allons utiliser une transformation logistique : au lieu de prédire directement comme la valeur d'une fonction linéaire en nous allons composer cette fonction linéaire avec la fonction logistique :
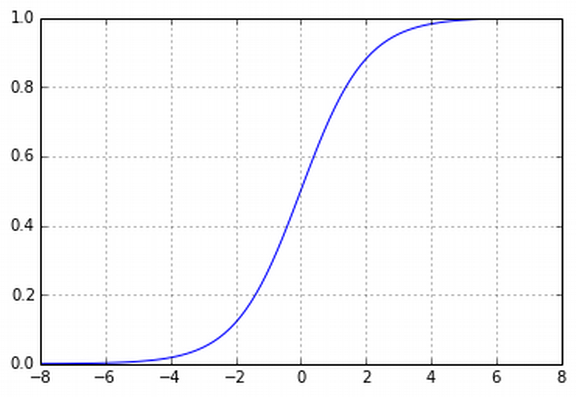
Nous avons donc le modèle suivant :
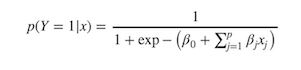
C'est ce qu'on appelle une régression logistique.
Solution de la régression logistique
Comme la régression linéaire, la régression logistique peut s'apprendre par maximum de vraisemblance (voir la section correspondante du chapitre « Trouvez une combinaison linéaire de variables qui approxime leurs étiquettes » de ce cours). Souvenez-vous, nous allons chercher à maximiser le logarithme de la vraisemblance, à savoir résoudre
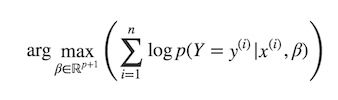
Comment calculer ? Il y a deux cas possibles :
- soit auquel cas il s'agit de ;
- soit auquel cas il s'agit de qui vaut
Autrement dit :
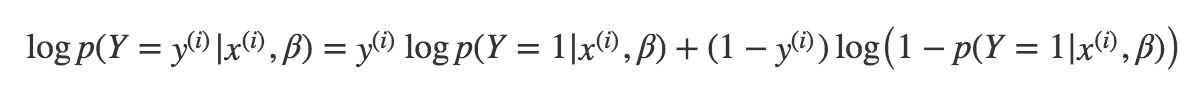
Il ne nous reste plus qu'à remplacer par sa valeur, à savoir la transformation logistique d'une combinaison linéaire des variables, et on obtient le problème suivant :
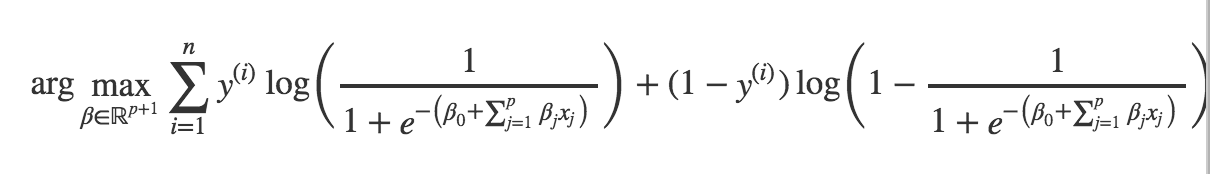
Contrairement au cas de la régression linéaire, le gradient de la fonction objective (celle que l'on cherche à maximiser) n'a pas de forme explicite et nous ne pouvons donc pas trouver de solution analytique. Cependant, la fonction objective est concave et nous pouvons utiliser la méthode du gradient.
La régression logistique est implémentée dans scikit-learn : sklearn.linear_model.LogisticRegression.
Régularisation
Nous avons vu dans les chapitres précédents que l'on peut utiliser la régularisation pour contrôler les coefficients d'une régression linéaire, et éviter le sur-apprentissage ou créer des modèles parcimonieux. Les mêmes concepts s'appliquent à la régression logistique, à la différence que la régression logistique régularisée par la norme n'admet pas de solution explicite.
On pourra donc utiliser :
La régression logistique avec régularisation ℓ2 pour éviter le sur-apprentissage (dans scikit-learn, c'est même l'implémentation par défaut de la régression logistique) ;
La régression logistique avec régularisation ℓ1 pour obtenir un modèle parcimonieux (dans scikit-learn, il suffit d'utiliser l'option
'penalty'=l1).
Conclusion
La régression logistique modélise la probabilité qu'une observation appartienne à la classe positive comme une transformation logistique d'une combinaison linéaire des variables.
Les coefficients d'une régression logistique s'apprennent par maximisation de vraisemblance, mais il n'existe pas de solution explicite.
La vraisemblance est convexe, et de nombreux solveurs peuvent être utilisés pour trouver une solution numérique.
Les concepts de régularisation ℓ1 et ℓ2 s'appliquent aussi à la régression logistique.
