Cas linéairement séparable
Vous avez déjà vu comment transformer la régression linéaire pour prédire la probabilité de l'appartenance d'un point à la classe positive. Mais puisqu'on parle de modèles linéaires, peut-on essayer de trouver un hyperplan (en deux dimensions, une droite) qui sépare « au mieux » les deux classes ?
Comment définir « au mieux » ? Commençons par considérer le cas linéairement séparable, autrement dit celui dans lequel il existe au moins un hyperplan tel que tous les points d'une classe soient d'un côté de et tous les points de l'autre classe soient de l'autre côté de .
Marge d'un hyperplan séparateur
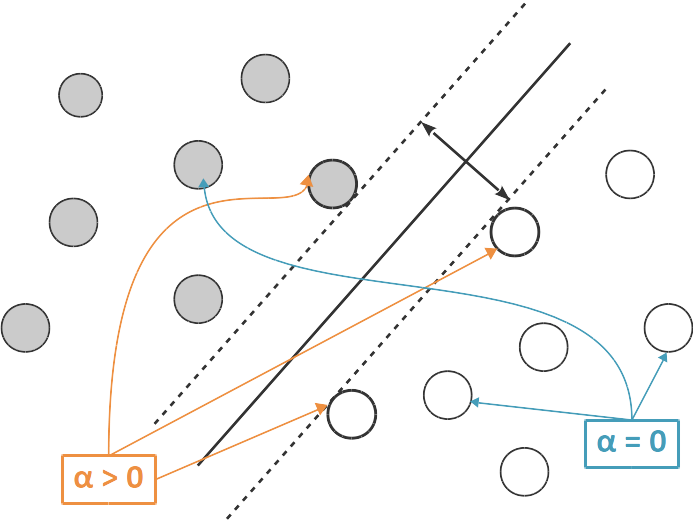
En fait, si les données sont linéairement séparables, il existe généralement une infinité d'hyperplans séparateurs qui classifient correctement les données. (le schéma ci-dessous, en dimension 2, devrait vous en convaincre). Pour formaliser lequel parmi ces multiples hyperplans nous convient le mieux, nous allons définir la marge d'un hyperplan séparateur comme deux fois la distance de au point du jeu de données qui en est le plus proche. (Il peut y avoir plusieurs points qui sont les plus proches de , comme sur le schéma ci-dessous.)
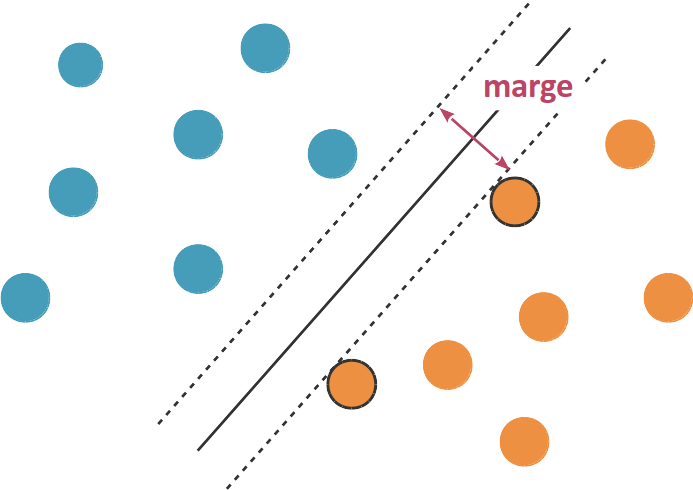
Comment utiliser ce concept de marge pour choisir un hyperplan séparateur ? L'idée derrière les SVMs est de chercher un hyperplan de marge maximale. Un hyperplan de marge maximale se situe à mi-distance entre les points positifs et les points négatifs dont il est le plus proche (voir illustration ci-dessous). En effet, si est plus proche des points positifs que des points négatifs, on peut le déplacer vers les points négatifs et augmenter sa marge.
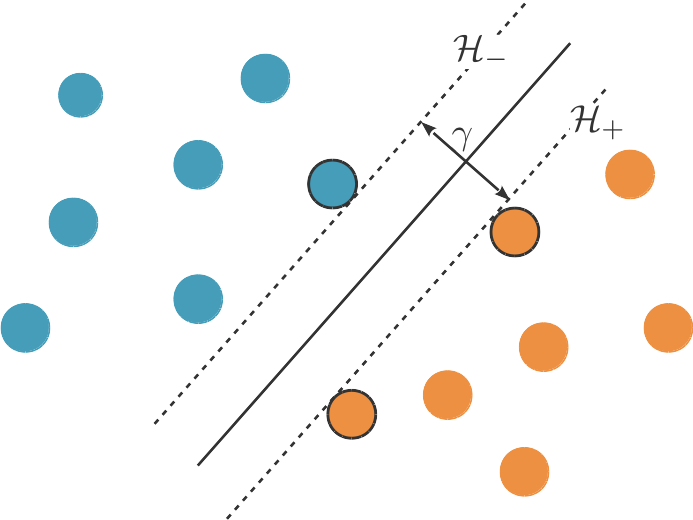
Un hyperplan séparateur de marge maximale définit une zone, un « no man's land » en quelque sorte, délimitée par deux hyperplans et parallèles à , situés chacun à une distance de , et entre lesquels il n'y a aucun point du jeu de données. Ce no man's land est souvent appelé la zone d'indécision car on manque d'information pour classifier les points dans cette zone (notre décision de positionner la frontière de décision, c'est-à-dire l'hyperplan séparateur, au milieu de cette zone est basée sur un choix de modélisation et non pas sur les données).
Le(s) point(s) positif(s) le(s) plus proche(s) de sont situés sur , et de même, le(s) point(s) négatif(s) le(s) plus proche(s) de sont situés sur . Ainsi, ces points supportent (ou, disons, soutiennent) et et s'appellent les vecteurs de support, d'où le nom de machine à vecteurs de support ou Support Vector Machine (SVM) de l'algorithme que nous allons découvrir aujourd'hui.
Formulation du SVM
Très bien, mais comment trouver un hyperplan séparateur à marge maximale ?
Considérons nos données : n points en p dimensions, représentés par la matrice d'étiquettes représentées par un vecteur
L'équation d'un hyperplan en dimension p est paramétrisée par les coordonnées du vecteur normal à cet hyperplan, ainsi que par un scalaire . Nous pouvons ainsi poser que l'équation de notre hyperplan séparateur de marge maximale est .
Les hyperplans et sont parallèles à et ont donc le même vecteur normal . De plus, ils sont équidistants par rapport à , et leurs équations peuvent donc s'écrire et ou est une constante. Comme nous pouvons arbitrairement multiplier , et par n'importe quel scalaire pour obtenir les mêmes équations, nous pouvons fixer , et ainsi avoir et
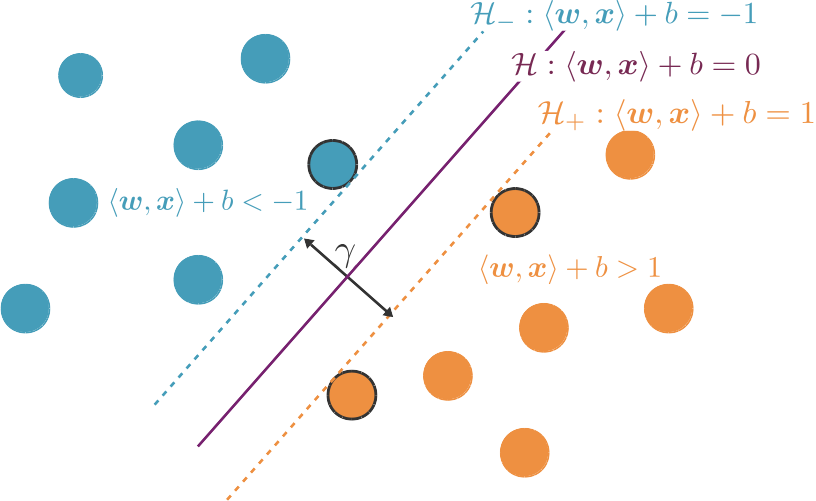
Nous pouvons maintenant utiliser ces équations pour deux choses :
- Calculer la marge autrement dit la distance entre et Quelques manipulations vous permettront d'arriver à
- Garantir que nos données soient correctement classifiées : les points positifs doivent tous être à l'extérieur de et les points négatifs doivent tous être à l'extérieur de Plus précisément, nous cherchons à ce que tous les points d'étiquette vérifient et que tous les points d'étiquette vérifient On peut combiner ces deux conditions en une seule :
Nous avons donc le problème d'optimisation suivant :
Pour simplifier les calculs, nous allons choisir de non pas maximiser , mais de minimiser , ce qui est équivalent. Nous obtenons ainsi le problème suivant :
Il s'agit d'un problème d'optimisation quadratique sous contrainte, qui peut être résolu avec un certain nombre de solveurs numériques. Cependant nous verrons plus bas que l'on peut le reformuler d'une façon qui nous donnera une solution plus facilement interprétable.
Prédire avec une SVM
D'accord, mais avant ça, comment utiliser une SVM pour faire des prédictions ?
Supposons notre problème d'optimisation résolu. Nous avons donc trouvé et qui minimisent la fonction objective (correspondant à l'inverse de la marge) sous contrainte que tous les points du jeu de données soient du bon côté de la zone d'indécision.
Nous allons maintenant étiqueter comme positif un point qui est du même côté de que les points positifs du jeu d'entraînement, autrement dit pour lequel À l'inverse, nous prédisons comme négatif un point situé de l'autre côté de l'hyperplan séparateur, autrement dit pour lequel
Nous utilisons donc directement l'hyperplan séparateur comme fonction de décision :
Si cette fonction est positive, le point est étiqueté positif, et inversement, si elle est négative, le point est étiqueté négatif.
Formulation duale et interprétation géométrique
Selon le vocabulaire en vigueur dans le domaine de l'optimisation sous contraintes, le problème d'optimisation que nous avons posé plus haut s'appelle un problème primal. Par une technique connue sous le nom des multiplicateurs de Lagrange, ce problème primal peut être reformulé en introduisant un scalaire (appelé, sans surprise, un multiplicateur de Lagrange) pour chacune de nos \(n\) contraintes ; il est équivalent à
La fonction suivante s'appelle le lagrangien du problème.
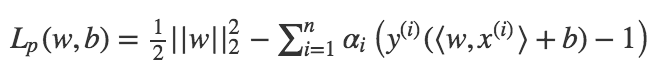
De plus les coefficients vérifient les conditions, dites de Karush-Kuhn-Tucker (ou KKT), que pour tout
- soit et — dans ce cas, la contrainte est vérifiée strictement : En d'autres termes, est situé à l'extérieur de la frontière de la zone d'indécision ;
- soit et — dans ce cas, la contrainte est vérifiée à l'égalité : En d'autres termes, est situé sur la frontière de la zone d'indécision.
Cela signifie que les points pour lesquels sont les vecteurs de support, et ceux pour lesquels sont ceux situés loin de et .
Appelons une solution de la minimisation du lagrangien. Celle-ci peut s'obtenir en annulant le gradient du lagrangien
- en et donc
- et en et donc
Et donc
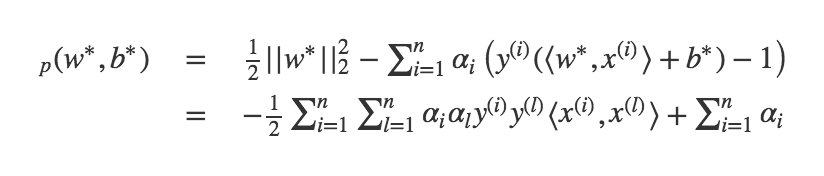 Le problème d'optimisation devient donc
Le problème d'optimisation devient donc
avec et
Cette nouvelle formulation s'appelle la forme duale du SVM. On peut donc trouver les coefficients du SVM en résolvant ce problème d'optimisation plutôt que le primal.
Mais on aurait pu résoudre le primal directement, non ? Quel est l'intérêt d'avoir fait tous ces calculs ?
Une fois que nous avons trouvé la solution du problème dual, nous pouvons réécrire notre fonction de décision en remplaçant par sa valeur :
Nous avons donc écrit notre fonction de décision en termes de produits scalaires entre le point à étiqueter et les points du jeu d'entraînement. Cela jouera un rôle important dans le fait de pouvoir étendre les SVM à des problèmes de classification non linéaire, comme nous le verrons dans un autre cours.
Par ailleurs, souvenez-vous de notre interprétation géométrique plus haut : seuls certains points auront un coefficient et ces points sont les vecteurs de support. La solution ne dépend donc pas des points qui ne sont pas vecteurs de supports, pour lesquels Et c'est logique, car si l'on déplace un peu ces points, ils restent loin de la zone d'indécision. et l'hyperplan séparateur ne changera pas. Par contre, si l'on déplace un vecteur de support, il pourra entraîner avec lui (ou s'il s'agit d'un point négatif), ce qui déplacera
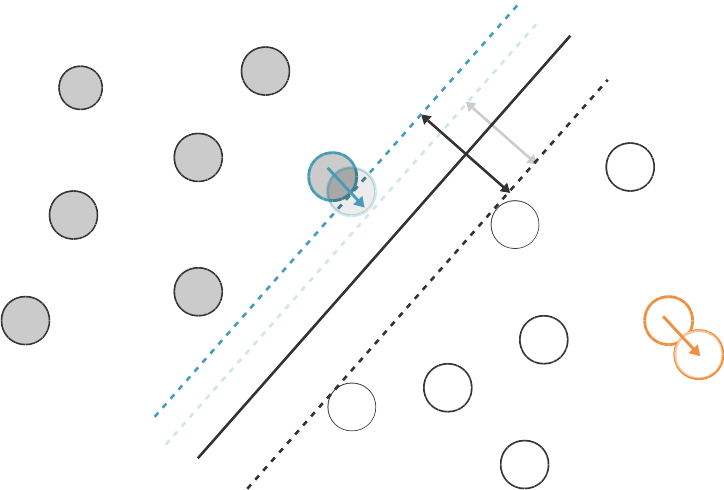
Ainsi, notre fonction de décision peut être calculée sur la base du produit scalaire entre le point à étiqueter et les vecteurs de support uniquement.
Remarquons que le primal est un problème d'optimisation en p dimensions, alors que le dual est un problème d'optimisation en n dimensions. Si , alors résoudre le primal sera plus efficace. À l'inverse, si l'on a peu d'échantillons et beaucoup de variables résoudre le dual sera plus efficace.
Cas non-linéairement séparable
Malheureusement, dans la plupart des cas, les données ne sont pas linéairement séparables. Il va donc falloir que nous acceptions de faire des erreurs, autrement dit que certains points de notre jeu d'entraînement se retrouvent du mauvais côté de la frontière de la zone d'indécision.
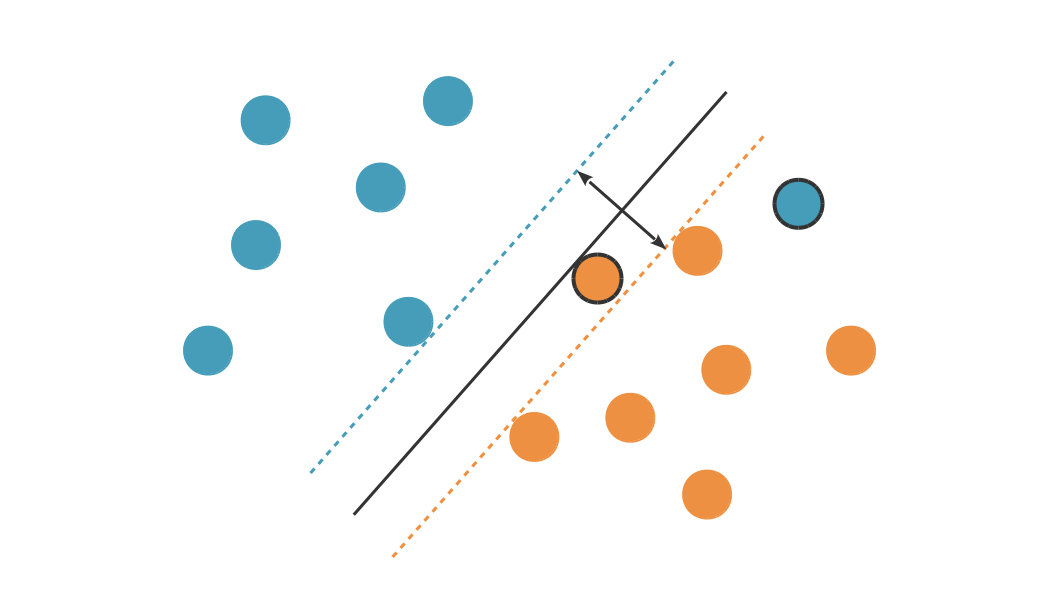
Plus la marge est grande, plus nous somme susceptibles d'avoir d'erreurs. Nous allons donc formuler un nouveau problème : minimiser la marge et l'erreur simultanément :
L'hyperparamètre C sert à quantifier l'importance relative du terme d'erreur et du terme de marge.
Perte hinge
Comment mesurer l'erreur de notre classifieur ? Rappelez-vous, nous souhaitons que soit du bon côte de la frontière de la zone d'indécision, autrement dit, que Si c'est le cas, nous voulons que notre fonction d'erreur vaille 0. Sinon, nous allons définir une erreur qui est d'autant plus grande que s'éloigne de la valeur 1, autrement dit, que s'éloigne de la frontière ( s'il est positif ou s'il est négatif).
Cette erreur s'appelle la perte hinge, ou « hinge loss » en anglais. « Hinge » signifie « charnière » en anglais, et correspond à la forme « en coude » de la perte hinge.
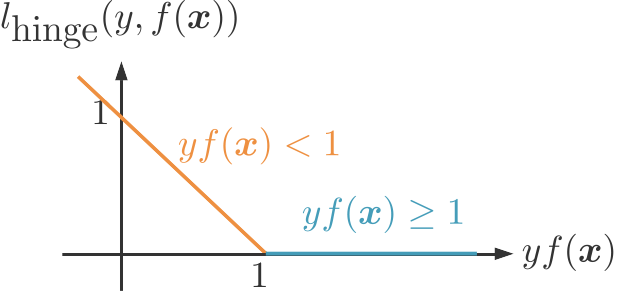
La perte hinge peut s'écrire de manière analytique de la fonction suivante :
SVM à marge souple
Nous pouvons maintenant formuler notre problème d'optimisation :
Malheureusement cette nouvelle fonction objective ne peut pas être minimisée analytiquement. Nous allons donc introduire n variables d'ajustement appelées slack variables en anglais, qui vont mesurer la distance entre et 1. Pour chaque point du jeu de données, la perte hinge vaut donc et l'on souhaite
- soit que soit correctement classifié : et ;
- soit que et
On peut reformuler ces deux possibilités en deux contraintes : et
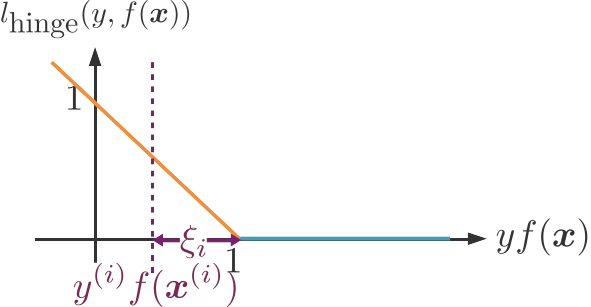
La variable d'ajustement est la distance entre et sa valeur souhaitée de 1.
Nous aboutissons donc à la formulation suivante :
avec pour tout et
C'est la forme primale de ce qu'on appelle le SVM à marge souple, ou soft-margin SVM en anglais.
Formulation duale
Avec les mêmes outils d'optimisation sous contrainte que pour le cas linéairement séparable, nous pouvons dériver la formulation duale du SVM à marge souple et les conditions KKT correspondantes.
Nous introduisons ainsi deux multiplicateurs de Lagrange par observation : pour la première contrainte, et pour la deuxième. Le primal devient équivalent à
Le lagrangien vaut ici
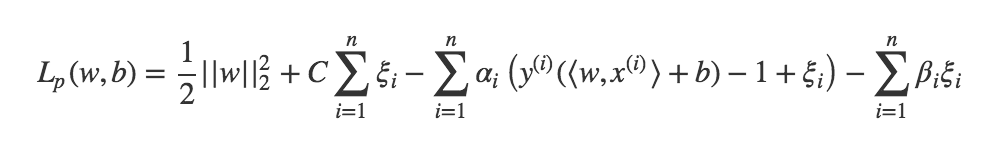
Les conditions de Karush-Kuhn-Tucker sont les suivantes :
- soit et
- soit et
- soit et
- soit et
La minimisation du lagrangien se fait en minimisant son gradient :
- en w, ce qui donne comme précédemment ;
- en b, ce qui donne comme précédemment ;
- en , ce qui donne
Cette dernière équation nous permet de lier à , et le problème de maximisation en et devient un problème de maximisation en seulement. De plus, la contrainte nous donne
La forme duale du SVM à marge souple est donc :
avec et
La seule différence avec le cas linéairement séparable est la contrainte !
Interprétation géométrique
Revenons aux conditions de KKT. Les deux dernières d'entre elles peuvent se réécrire
- et
- et
En prenant toutes les conditions de KKT en considération, on arrive donc à 3 cas possibles pour :
- . Dans ce cas, (car ) et Comme précédemment pour le cas linéairement séparable, est à l'extérieur de la zone d'indécision (frontière exclue) ;
- . Dans ce cas, (le point est correctement classifié) et . est donc un vecteur de support ;
- , auquel cas et est du mauvais côté de la frontière de la zone d'indécision.
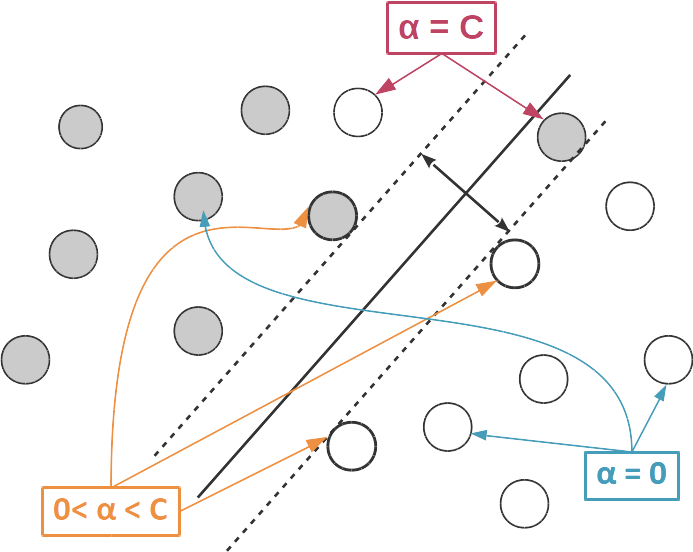
Les points qui vérifient sont ceux pour lesquels on a fait une erreur.
La SVM, aussi appelée SVC pour « Support Vector Classification », est implémentée dans scikit-learn : sklearn.svm.LinearSVC.
Et la régression dans tout ça ?
Les SVM peuvent aussi être utilisées pour des problèmes de régression. On cherche toujours à minimiser , mais les contraintes sont maintenant données par une fonction de perte différente : étant donné un hyperparamètre , nous souhaitons que la différence entre l'étiquette et sa valeur prédite soit, en valeur absolue, inférieure à . Nous séparons cette condition en deux :
Si la différence est positive, nous souhaitons que . Si elle est négative, cette condition sera naturellement vérifiée puisque .
Si la différence est négative, nous souhaitons que .
Comme cela ne pourra pas toujours être le cas, nous introduisons deux variables d'ajustement par observation dans nos données : pour ajuster la première condition, et pour ajuster la deuxième. Le primal s'écrit donc :
sous les conditions que et
Le dual s'écrit
avec et
La régression SVM, aussi appelée SVR pour Support Vector Regression, est implémentée dans scikit-learn : sklearn.svm.LinearSVR. Encore une fois, une implémentation duale et une implémentation primale sont disponibles via l'option 'dual' et il vaut généralement mieux choisir 'dual=False' quand on a beaucoup de données et 'dual=True' quand on a beaucoup de variables.
Conclusion
Les SVM (Support Vector Machines), aussi appelées en français Machines à Vecteurs de Support et parfois Séparatrices à Vaste Marge, cherchent à séparer linéairement les données.
La version primale résout un problème d'optimisation à p variables et est donc préférable si on a moins de variables que d'échantillons.
À l'inverse, la version duale résout un problème d'optimisation à n variables et est donc préférable si on a moins d'échantillons que de variables.
Les vecteurs de support sont les points du jeu de données qui sont les plus proches de l'hyperplan séparateur.
La fonction de décision peut s'exprimer uniquement en fonction du produit scalaire du point à étiqueter avec les vecteurs de support.
