Supposons maintenant que nous ayons plus de deux classes. Par exemple, un problème de classification d'images entre « voiture », « vélo », « bus de ville », « piéton », « scooter ». Comment utiliser les classifieurs binaires que nous savons construire pour résoudre un tel problème ?
Nos données sont toujours n points en p dimensions, représentés par la matrice , et leurs étiquettes, Nous avons donc K classes.
One-versus-rest
Une première approche consiste à créer un classifieur pour chacune des classes, qui sépare les points de cette classe de tous les autres points.
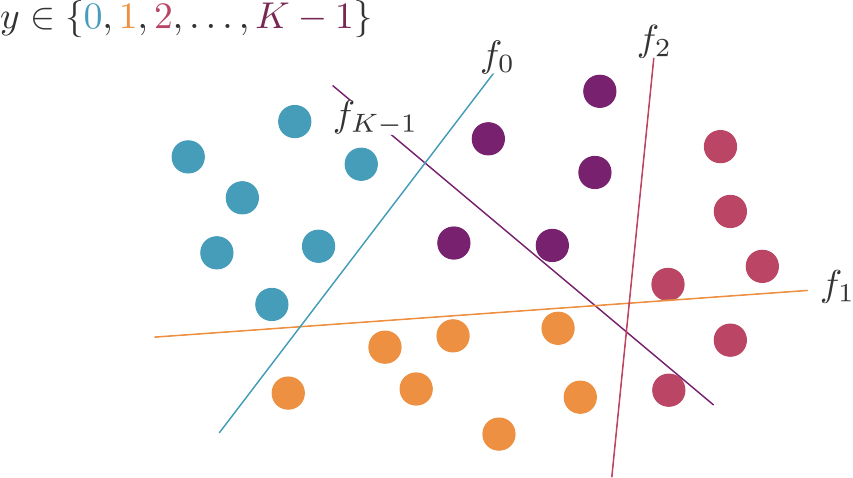
Cette méthode est appelée one-versus-rest (« une contre le reste », OVR en abrégé) ou one-versus-all (« une contre toutes », OVA en abrégé).
Nous avons maintenant K classifieurs. Comment obtenir une seule prédiction finale ?
Supposons que nos classifieurs soient des régressions logistiques. Alors , il est logique de prédire que x appartient à la classe pour laquelle cette prédiction est la plus élevée. Dans le cas des SVM, indique la distance entre x et l'hyperplan qui sépare la classe k des autres. Plus cette valeur est élevée, plus nous sommes convaincus que x appartient à la classe k.
Nous allons donc simplement prédire la classe pour laquelle la fonction de décision retourne la valeur la plus élevée :
Complexité algorithmique
Pour entraîner notre algorithme, nous avons dû entraîner K classifieurs sur n points chacun. Si j'appelle la complexité algorithmique du classifieur de base, la complexité de l'entraînement de notre OVR est donc
En ce qui concerne la prédiction, il faut faire K prédictions, puis en prendre le maximum. Nous avons donc une complexité de où est la complexité de la prédiction d'un de nos classifieurs de base.
OVR est implémenté dans scikit-learn : sklearn.multiclass.OneVsRestClassifier.
One-versus-one
Une autre façon de faire consiste à calculer K(K-1) classifieurs, chacun séparant une classe d'une autre en ignorant les autres classes (et les observations qui leur appartiennent).
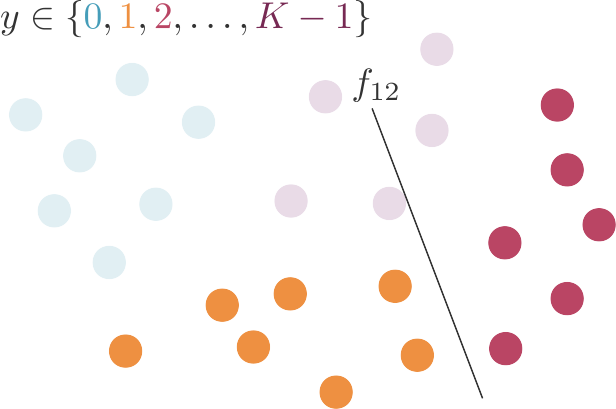
Cette méthode est appelée one-versus-one (« une contre une », OVO en abrégé).
Comment fait-on une prédiction maintenant, avec K(K-1) classifieurs ?
Pour prédire, nous allons utiliser un vote de la majorité : la classe prédite est celle retournée par le plus grand nombre de classifieurs.
Complexité algorithmique
Nous devons maintenant construire classifieurs plutôt que K. Nos temps de calcul vont augmenter ! Eh bien, tout dépend de . Nous entraînons certes classifieurs, mais chacun d'entre eux est entraîné sur points seulement.
OVO est implémenté dans scikit-learn : sklearn.multiclass.OneVsOneClassifier.
SVM multi-classe
Regardons maintenant de plus près le cas des SVM.
Appliquons l'algorithme OVR dans un contexte multiclasse. Nous allons construire l'un après l'autre K hyperplans séparateurs d'équations Chacun de ces hyperplans vérifie
avec et où
vaut 1 si et -1 sinon.
Nous avons donc K problèmes d'optimisation à 2n contraintes à résoudre. Chacune des contraintes dit que chaque point doit être au pire à une distance du « mauvais côté » de la frontière de la zone d'indécision entre sa classe et l'union des autres classes.
Mais nous pouvons changer la contrainte pour chercher à découvrir les K hyperplans simultanément, de sorte que chaque point du jeu d'entraînement soit (1) du bon côté de l'hyperplan séparateur de sa classe, d'équation et plus loin de cet hyperplan séparateur que de tous les autres, définis par . Idéalement, nous voudrions donc que pour chaque point
Comme cela va certainement ne pas être systématiquement possible, on peut réintroduire ici les variables d'ajustement et imposer
Nous pouvons donc formuler le SVM multi-classe comme le problème suivant, qui utilise n variables au lieu de :
avec et
Comme dans OVR, la prédiction se fait selon la fonction de décision maximale :
Cette méthode a été proposée par Crammer et Singer en 2002. Elle est implémentée dans scikit-learn via l'optionmulti_class="crammer_singer" de sklearn.svm.LinearSVC. Par défaut, LinearSVC gère le multi-classe avec une approche OVR.
Conclusion
L'approche one-versus-rest de la classification multi-classes consiste à créer K classifieurs binaires qui séparent chaque classe k de l'union des autres classes. On prédit alors la classe pour laquelle la fonction de décision est maximale.
L'approche one-versus-one consiste à créer K(K-1) classifieurs binaires qui séparent chacun une classe d'une autre, en ignorant tous les autres points. On utilise alors un vote de la majorité pour prédire. Cette approche crée plus de classifieurs, mais chacun est entraîné sur moins d'observations.
On peut créer des SVM multiclasse en optimisant simultanément K classifieurs binaires (méthode de Crammer et Singer).
Nous verrons aussi dans un prochain cours qu'il existe plusieurs algorithmes non-linéaires qui sont naturellement multi-classes.
