Avec Kafka, on dispose du premier composant de notre architecture de gestion de données temps réel. Kafka sert de centre de distribution des messages : il reçoit les messages pour que d'autres composants puissent les récupérer et les traiter. Dans cette partie, on va aborder la phase de traitement des messages. Le traitement des messages est une étape bien distincte de leur distribution qui est réalisée à l'aide d'outils différents.
Pour comprendre en quoi peut consister le traitement de données temps réel, prenons l'exemple d'une application qui émet des logs dans des fichiers texte. Chaque ligne de log contient :
une date et une heure ("31/01/2017:11:57:17 +0200"),
l'url d'une page visitée et la méthode employée ("GET /index.html HTTP/1.1"),
le code de retour du serveur HTTP ("200"),
l'identifiant de l'utilisateur qui a visité la page ("userid=4127").
Ces lignes de log sont riches en information, à condition de savoir correctement les analyser. Par exemple, on peut envisager les applications suivantes :
Compter le nombre de visites du site par heure
Compter le nombre de visites par utilisateur et par page
Détecter les erreurs 500 du serveur pour lancer des alertes
Pour réaliser ces applications, il va falloir qu'on décompose chaque ligne pour en extraire la date, l'url, etc. Puis il va falloir transmettre ces données à des applications. Si la quantité de logs est élevée, ou si on veut réaliser des applications complexes à partir de ces données, il va falloir créer une architecture distribuée. Il ne faudra pas que l'échec d'une application impacte les autres applications.
Dans ce chapitre et ceux qui suivent, nous allons présenter Apache Storm qui est un système de traitement de données qui répond à ces impératifs. Comme on va le voir, Storm a été conçu pour interagir de manière assez naturelle avec Kafka et faire passer à l'échelle le traitement de données temps réel.
Concepts de base : tuples, spouts, bolts
Storm a été conçu pour traiter des flux illimités de tuples ("unbounded tuple streams") de manière distribuée. Les tuples correspondent à ce que nous avons appelé jusqu'à présent des "messages". Les flux de tuple sont créés et traités en parallèle ; comme ils sont "illimités", on considère que le traitement de ces flux est ininterrompu.
Dans Storm, les tuples sont générés par des spouts et les traitements sont réalisés par des bolts. La transmission des données des spouts vers les bolts peut se représenter sous la forme de graphes dont les nœuds sont les spouts et les bolts et les connexions entre les nœuds sont les flux. Pour une application donnée, un tel graphe est sa topologie.
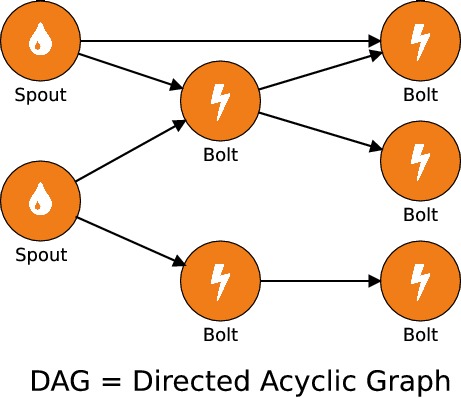
Topologies et graphes acycliques
Comme on peut le voir dans la topologie ci-dessus, un bolt peut recevoir des flux de tuples de la part de plusieurs spouts ou bolts différents. Cependant, toutes les connexions ne sont pas autorisées puisqu'il est interdit d'envoyer un flux de tuples à un nœud parent : le graphe des connexions est dit acyclique. Pour cette raison, on dit qu'une topologie Storm est un graphe orienté acyclique ("directed acyclic graph") ou DAG. C'est une notion que l'on retrouve dans d'autres outils de traitement des données massives dans un environnement distribué, comme Apache Spark. Pour en savoir plus n'hésitez pas à suivre notre cours sur les calculs distribués.
Comme pour Apache Spark, la représentation d'une topologie sous la forme d'un DAG permet une certaine tolérance aux pannes : il suffit qu'un des nœuds signale que le traitement d'un tuple a causé un échec pour faire remonter l'erreur au spout parent. Celui-ci pourra éventuellement décider de ré-émettre le tuple correspondant. Nous reverrons cette notion dans les chapitres suivants.
Traitements distribués
Comme on l'a laissé entendre jusqu'ici, les traitements sont effectués de manière distribuée dans une topologie Storm. Cela signifie que les différents bolts et spouts peuvent être exécutés sur des machines différentes. Mais la distribution des traitements va plus loin, puisqu'il est possible d'avoir plusieurs workers en parallèle pour chaque spout et chaque bolt. Donc en réalité, les échanges entre les nœuds du graphe ressemblent plutôt au schéma suivant :
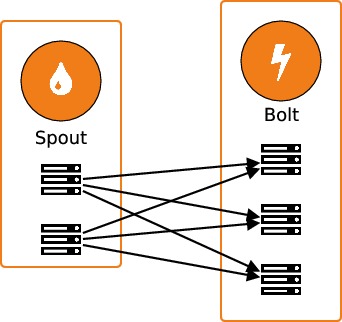
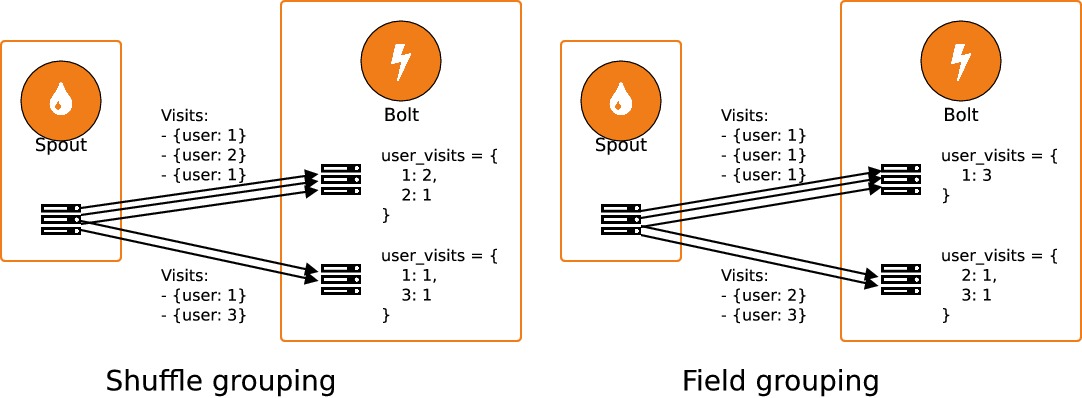
Comme on va le voir, le niveau de parallélisme de chaque spout et de chaque bolt peut être précisé manuellement, au moment de l'instanciation. Lorsque les traitements d'un bolt sont réalisés en parallèle sur plusieurs workers, il faut faire attention à la manière dont les données sont distribuées entre les workers. Par défaut, les données sont distribuées aléatoirement entre les workers : c'est le "shuffle grouping". Reprenons notre exemple précédent dans lequel on cherche à réaliser un décompte des visites de notre site utilisateur par utilisateur : il est alors nécessaire d'envoyer tous les tuples qui concernent un même utilisateur au même worker. On regroupe alors les tuples selon la valeur du champuser iden réalisant un "field grouping".
Nous allons voir dans le chapitre suivant comment utiliser ces notions en pratique.
