C'est bien beau de savoir la différence entre un spout et un bolt, mais à quoi bon si on ne sait pas créer des topologies Storm, concrètement ? C'est pour ça que dans ce chapitre, on va voir comment coder les différents composants de nos topologies.
L'API de Storm est en Java, ce qui veut dire que nous allons utiliser Java pour écrire le code de nos topologies. Nous allons commencer par mettre en place Eclipse, un environnement de développement intégré (IDE) (Eclipse) spécialement conçu pour le développement d'applications en Java, puis nous verrons comment créer une première application Storm.
Installation d'Eclipse
Nous allons avoir besoin d'un environnement de travail en Java ; pour ça, nous avons besoin d'un Java Development Kit (JDK). Les instructions d'installation sont différentes pour tous les OS ; sous Ubuntu 16.04, il suffit d'exécuter :
$ sudo apt install default-jdkVous pouvez vérifier au préalable si un JDK n'a pas déjà été installé en exécutant :
$ which javacLe paquetdefault-jdkinstallera alors à la fois OpenJDK-8 et le JRE (Java Runtime Environment) correspondant. Cependant, ce dernier devrait déjà avoir été installé sur votre système si vous avez réussi à utiliser Kafka dans le chapitre précédent.
Nous aurons également besoin du gestionnaire de projet Maven, qui peut être installé sous Ubuntu avec la commande :
$ sudo apt install mavenPour les autres OS (Mac OS, Windows), vous êtes invités à télécharger le JDK directement sur le site d'Oracle.
Vous pouvez ensuite télécharger Eclipse Neon IDE directement sur la page dédiée. À l'installation, choisissez "Eclipse IDE for Java Developers", puis allez prendre un café (un café court si vous avez une connexion internet rapide).
Création d'un projet Maven
Nous allons utiliser Apache Maven pour créer notre projet, ce qui nous permettra de gérer (plus ou moins) facilement les dépendances de notre projet. Voici comment créer le squelette d'un projet :
$ mkdir ~/code/workspace/
$ cd ~/code/workspace/
$ mvn archetype:generateAcceptez ensuite tous les choix par défaut de Maven, et choisissez "analytics" pourgroupIdet pourartifactId. LegroupIdd'un projet définit le chemin d'import d'un package tandis que l'artifactIdaffecte le nom du fichier.jarqui sera généré lors de l'étape de packaging suivante :
$ cd analytics/
$ mvn packageEntre autres choses, la commandemvn packagedevrait avoir produit un fichier.jarqui contient les binaires de projet, dont la classeAppqui contient unHello World. On peut exécuter cette classe en écrivant :
$ java -cp target/analytics-1.0-SNAPSHOT.jar analytics.App
Hello World!Pour créer des topolologies Storm, on va devoir installer le packagestorm-coreet indiquer que notre code dépend de ce package. Pour cela, modifiez le fichier de configuration du projet :
$ vim pom.xmlet ajoutez la dépendance suivante dans la section<dependencies>:
<dependencies>
...
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>Il ne nous reste qu'à générer les fichiers de configuration nécessaire pour ouvrir notre projet avec Eclipse :
$ mvn eclipse:eclipseEnfin ! On est prêts à ouvrir notre projet avec Eclipse et à développer des topologies Storm.
Web analytics
Le code de la topologie décrite dans cette section est disponible dans le dépôt git public de ce cours. Vous êtes encouragés à récupérer le contenu de ce dépôt pour en examiner le code en détail ; les sections importantes seront dupliquées dans le texte de ce chapitre. Pour ouvrir ce projet avec Eclipse, sélectionnez :File > Open Projects from File System... > Directory... > <Sélectionnez le répertoire gerez-des-flux-de-donnees-temps-reel/analytics>.
Voici le schéma de fonctionnement de notre topologie :
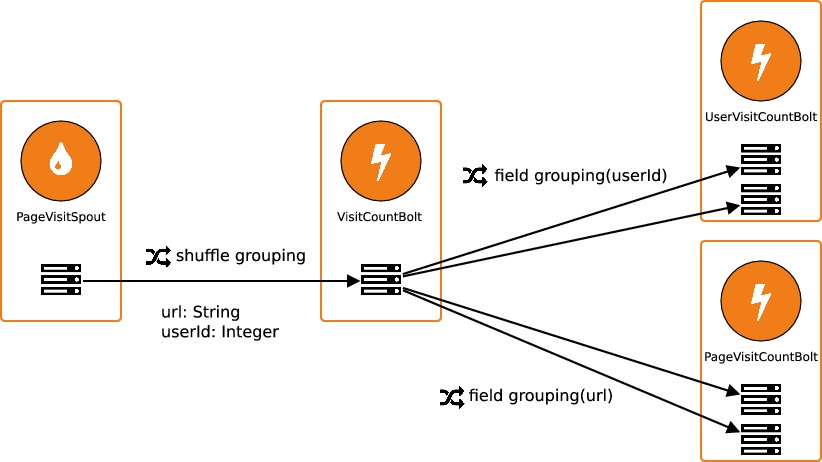
Le spout
PageVisitSpoutva émettre des tuples aléatoirement ; ces tuples contiennent un identifiant utilisateur ainsi que l'url d'une page visitée.Le bolt
VisitCountBoltva compter le nombre total de visites.Les bolts
UserVisitCountBoltetPageVisitCountBoltvont compter le nombre de visites par utilisateur et par page, respectivement. Chacun de ces deux bolts sera exécuté par deux tâches en parallèles. Ces deux bolts auraient tout aussi bien pu être connectés directement au spout.
Le spout émet des tuples via la méthodenextTuple qui est appelée en continu :
public class PageVisitSpout extends BaseRichSpout {
...
@Override
public void nextTuple() {
...
Values values = new Values(url, userId);
// On utilise la méthode 'emit' d'un SpoutOutputCollector (récupéré
// lors de l'appel à 'open()') pour émettre de nouveaux tuples
outputCollector.emit(values, values);
Utils.sleep(2000);
}
...
}Remarquez que la méthodeemitprend ici deux arguments : le second argument, facultatif, correspond à l'identifiant du tuple et il va nous permettre de gérer les erreurs de traitement, comme on va le voir un peu plus loin.
Pour émettre des tuples, il faut déclarer les noms des champs des tuples dans la méthodedeclareOutputFields:
public class PageVisitSpout extends BaseRichSpout {
...
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("url", "userId"));
}
...
}Cette méthode doit également être définie pour les bolts qui émettent des tuples. On va donc la retrouver dans le boltVisitCountBolt.
Chaque bolt reçoit et traite les tuples à l'aide de la méthodeexecute. Voici par exemple la méthodeexecutedePageVisitCountBolt :
public class PageVisitCountBolt extends BaseRichBolt {
...
@Override
public void execute(Tuple input) {
String url = input.getStringByField("url");
// pageVisitCounts est ici de type HashTable<String, Integer>
pageVisitCounts.put(url, pageVisitCounts.getOrDefault(url, 0) + 1);
outputCollector.ack(input);
}
}L'appel àackpermet de notifier le spout que le tupleinputa bien été traité sans erreur. Nous reviendrons sur ce sujet un peu plus loin.
Une fois que nos différents bolts et spouts ont été créés, il faut les connecter entre eux en créant une topologie. Notre topologie sera créée dans la méthodemainde notre application :
public class App {
public static void main(String[] args) ...
{
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("page-visits", new PageVisitSpout());
builder.setBolt("visit-counts", new VisitCountBolt(), 1)
.shuffleGrouping("page-visits");
builder.setBolt("user-visit-counts", new UserVisitCountBolt(), 2)
.fieldsGrouping("visit-counts", new Fields("userId"));
builder.setBolt("page-visit-counts", new PageVisitCountBolt(), 2)
.fieldsGrouping("visit-counts", new Fields("url"));
StormTopology topology = builder.createTopology();
# Pour prototyper notre application, il faut la soumettre à un cluster local
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("analytics-topology", new Config(), topology);
}
}Lorsque l'on exécute cette méthodemainon voit dans les logs que le traitement de certains tuples échoue :
...
Correctly processed: [http://example.com/index.html, 5]
Correctly processed: [http://example.com/subscribe.html, 3]
ERROR processing: [http://example.com/index.html, 4]
Correctly processed: [http://example.com/index.html, 4]
Correctly processed: [http://example.com/subscribe.html, 5]
Correctly processed: [http://example.com/404.html, 3]
...Ceci est dû au fait que nous avons artificiellement simulé l'échec du traitement de certains tuples dans la méthodeexecutedeUserVisitCountBolt : environ un tuple sur 10 est déclaré comme étant en échec. Pour comprendre ce qui se passe, il faut comprendre le comportement de notre topologie en cas d'erreur...
Gestion des erreurs
Comme on l'a vu dans le chapitre précédent, chaque topologie Storm est représentée sous forme de graphe acyclique (DAG). Pour chaque tuple émis par un spout, on peut suivre les tuples auxquels il a "donné naissance" dans les autres bolts. Ceci peut se faire à trois conditions :
Les tuples émis par le spout doivent posséder un identifiant qui leur est propre : ceci se fait en ajoutant un
messageIdà l'appel de la méthodeemitdans le spout. On aurait pu prendre un entier aléatoire comme identifiant d'un tuple, mais on a choisi le tuple lui-même pour une raison qui va bientôt devenir évidente.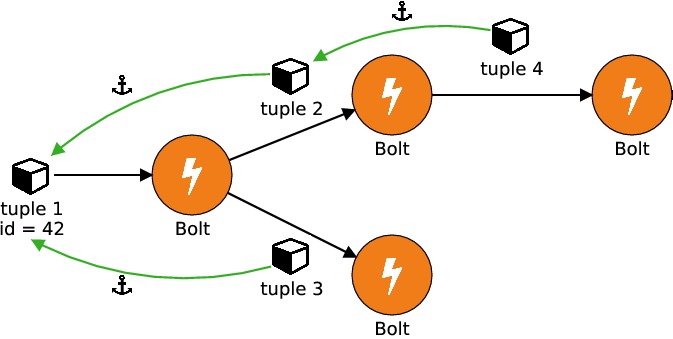
Les tuples émis par les bolts doivent être ancrés ("anchored") à un autre tuple. Un tuple y ancré à un tuple x sera appelé "descendant" de x ; un autre tuple z descendant de y sera également considéré comme un descendant de x. Dans le schéma suivant, le tuple 4 est un descendant du tuple 1 :
Après le traitement de chaque tuple, chaque bolt indique le succès ou l'échec du traitement du tuple à l'aide des méthodes
ack()etfail().
Dès lors qu'un tuple possède un identifiant (condition #1), la gestion des erreurs sera activée pour ce tuple. La méthodefaildu spout ayant émis un tuple sera appelée dès que le tuple ou l'un de ses descendants sera en échec. Un tuple donné peut être mis en échec de deux manières différentes :
En appelant la méthode
faild'unOutputCollector.Si le traitement d'un tuple excède un délai maximal défini par
TOPOLOGY_MESSAGE_TIMEOUT_SECS, qui est par défaut de trente secondes. Ce délai peut être modifié en modifiant la configuration passée au cluster :public class App { public static void main(String[] args) ... { ... // Les messages seront automatiquement mis en échec après une durée de // traitement supérieure à 10 secondes Config config = new Config(); config.setMessageTimeoutSecs(10); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("analytics-topology", config, topology); } }
Lorsqu'un tuple est mis en échec, le cluster recherche l'identifiant de son tuple parent émis un spout. La méthodefaildu spout est alors appelée avec en argument l'identifiant du tuple :
public class PageVisitSpout extends BaseRichSpout {
...
public void fail(Object msgId) {
System.out.printf("ERROR processing: %s\n", msgId);
Values tuple = (Values)msgId;
// En cas d'erreur, on choisit ici de ré-émettre le tuple lui-même.
outputCollector.emit(tuple, msgId);
}
}Le fait que l'identifiant du tuple soit le tuple lui-même nous permet de ré-émettre le tuple ! (je vous avais dit qu'il y avait une bonne raison au choix de l'identifiant du tuple)
A contrario, un tuple émis par un spout est considéré comme ayant été entièrement traité lorsque tous ses tuples enfant ont été traités. Pour indiquer qu'un tuple a été traité il faut appeler la méthodeackde l'objetOutputCollector. Lorsqu'un tuple a été entièrement traité, la méthodeackdu spout est appelée :
public class PageVisitSpout extends BaseRichSpout {
...
@Override
public void ack(Object msgId) {
System.out.printf("Correctly processed: %s\n", msgId);
}
}Dans le cas général, il n'est pas nécessaire de faire quoi que ce soit dans cette méthodeack. Nous avons choisi de l'implémenter dans notre exemple pour indiquer à quel moment un tuple est considéré comme complètement traité.
Parallélisation
Dans notre topologie, nous avons fait en sorte que les boltsUserVisitCountBoltetPageVisitCountBoltsoient exécutés sur plusieurs executors en même temps en passant le paramètreparallelism_hintaux méthodessetBolt:
public class App
{
public static void main( String[] args ) {
...
builder.setBolt("user-visit-counts", new UserVisitCountBolt(), 2)
...
builder.setBolt("page-visit-counts", new PageVisitCountBolt(), 2)
...
}
}Ce paramètre permet de distribuer les tâches relatives à un bolt sur plusieurs (ici : deux) threads en même temps. Dans un environnement distribué, cela se traduira par une distribution du calcul sur plusieurs machines.
La parallélisation des calculs soulève des questions propres à notre application : comment faire en sorte que le décompte des visites par utilisateur et par page soient correct dansUserVisitCountBoltetPageVisitCountBoltsi les tuples peuvent être envoyés indifféremment à l'un ou l'autre executor ? À chaque executor est associée une instance différente du bolt, donc les décomptes effectués par chacune des instances vont être faussés. Pour comprendre comment résoudre ce problème, il faut parler de "grouping"...
Tuple grouping
Si les tuples peuvent être envoyés indifféremment à n'importe quelle instance de bolt, on dit qu'on réalise un "shuffle grouping". Si, au contraire, les tuples sont envoyés à des executors différents en fonction des valeurs de leurs champs, il s'agit de "field grouping" : c'est exactement ce qu'il nous faut pour réaliser un décompte exact des visites par utilisateur et par page.
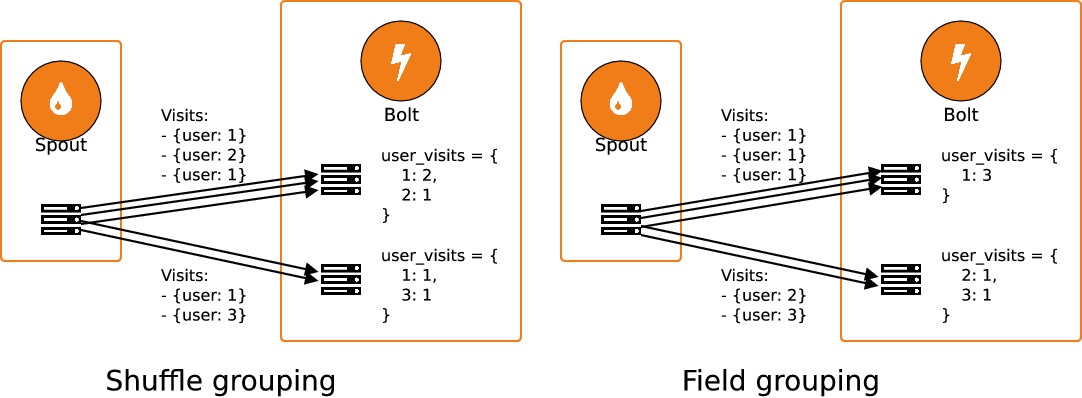
On réalise un groupage paruserIdou parurllors de la création de notre topologie :
public class App
{
public static void main( String[] args ) ... {
...
builder.setSpout("page-visits", new PageVisitSpout());
builder.setBolt("visit-counts", ...)
.shuffleGrouping("page-visits");
builder.setBolt("user-visit-counts", ...)
.fieldsGrouping("visit-counts", new Fields("userId"));
builder.setBolt("page-visit-counts", ...)
.fieldsGrouping("visit-counts", new Fields("url"));
...
}
}De cette manière, tous les tuples correspondant à un même utilisateur seront envoyés à la même instance deUserVisitCountBolt; et tous les tuples correspondant à la même url seront envoyés à la même instance dePageVisitCountBolt. Chaque instance n'aura donc qu'une partie des données d'ensemble, mais les décomptes récoltés seront exacts.
