L’architecture du ReplicaSet
Nous avons pu voir comment interroger des données, mais nous n’avons pas encore attaqué le problème de la tolérance aux pannes. MongoDB utilise pour cela une architecture basée sur le principe « maître/esclave ».
Le serveur primaire "Primary", à qui toutes les requêtes sont envoyées (lecture/écriture), va s’occuper de gérer la cohérence des données. Ainsi, lors d’une mise à jour, une réplication est effectuée sur les serveurs secondaires "Secondary".
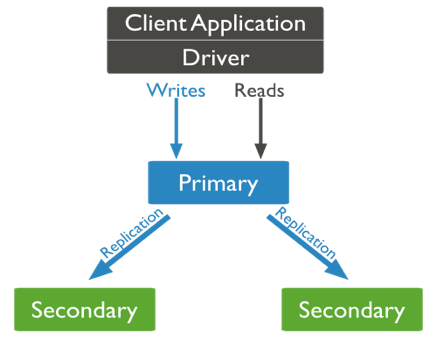
Toutefois, si l’on reste sur une architecture de la sorte, nous ne sommes pas tolérant aux pannes puisque le serveur primaire reste un point critique. Pour cela, nous allons rajouter un arbitre "arbiter", dont la tâche est de vérifier l’état du réseau. Ainsi, dès que le primary tombe, un système de vote va permettre d’élire le secondary qui remplacera le serveur tombé en panne. Nous sommes donc tranquilles : cette architecture tient tant qu’au moins un serveur tourne. C’est ce que l’on appelle un ReplicaSet.
Un ReplicaSet doit contenir au minimum 3 serveurs (1 Primary et 2 Secondary) pour garantir un minimum de tolérance aux pannes. Un ReplicaSet peut contenir jusqu’à 50 serveurs ; toutefois lorsqu’un vote a lieu pour élire le nouveau Primary, au maximum 7 peuvent participer à cette élection (les premiers ayant répondu à l’Arbiter).
Comment instancier un ReplicaSet ?
Nous allons simuler un ReplicaSet localement. Pour cela, les paramètres de chaque serveur doivent être définis :
Un nom de ReplicaSet : rs0
Un port d’écoute pour chaque serveur : 27018 (à incrémenter)
Créer un répertoire dédié : /data/R0S1 (ReplicaSet 0/Serveur 1) - Sous Windows, utilisez le répertoire C:\data\R0S1 (à remplacer par la suite)
Ouvrir une console et aller dans le répertoire de mongodb (dénommé ici $MONGO/bin)
Lancer le serveur :
mongod --replSet rs0 --port 27018 --dbpath /data/R0S1
Cette opération devra être répétée pour chaque serveur du ReplicaSet. Il faut maintenant initier celui-ci. En mode console (connexion sur le port 27018).
$MONGO/mongo --port 27018
rs.initiate ();
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "local:27018",
"ok" : 1
}Le ReplicaSet a été initié. Vous pouvez d’ailleurs connaître le nom réseau de votre machine dans la clé "me" (ici : local). Regardons la configuration du ReplicaSet :
rs.conf();
{
"_id" : "rs0",
"version" : 1,
"protocolVersion" : NumberLong(1),
"members" : [
{
"_id" : 0,
"host" : "local:27018",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : 2000,
"getLastErrorModes" : {},
"getLastErrorDefaults" : {"w" : 1,"wtimeout" : 0},
"replicaSetId" : ObjectId("595dea41036cb3d77737ca61")
}
}Notre serveur est le premier membre du ReplicaSet "rs0", il a récupéré 1 voix (la sienne) pour devenir PRIMARY, toutefois, sans arbitre. Vous pouvez d’ailleurs constater dans votre console que le serveur est bien primary pour rs0 :
rs0:PRIMARY >
Maintenant, ajoutons deux autres membres au ReplicaSet ; reprendre les étapes 1 à 5 ci-dessus (répertoires, ports, 1 console par serveur). Puis :
rs.add("local:27019");
rs.add("local:27020");Définir l’arbitre
Pour départager les votes (nombre pair de serveur par exemple), un arbitre sera nécessaire pour désigner le PRIMARY. Pour ce faire :
Créons le répertoire /data/arb (C:\data\arb sous Windows)
Exécutons un arbitre en spécifiant le port 30000 : mongod --port 30000 --dbpath /data/arb --replSet rs0
Ajoutons l'arbitre dans la console d’administration :
rs.addArb("local:30000")Pour consulter le statut actuel du ReplicaSet, il suffit de faire l’instruction suivante :
rs.status()
{
"set" : "rs0",
"date" : ISODate("2017-07-06T13:36:41.283Z"),
"myState" : 2,
"term" : NumberLong(2),
"syncingTo" : "local:27020",
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
},
"appliedOpTime" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
},
"durableOpTime" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
}
},
"members" : [
{
"_id" : 0,
"name" : "local:27018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 21186,
"optime" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
},
"optimeDate" : ISODate("2017-07-06T13:36:38Z"),
"syncingTo" : "local:27020",
"configVersion" : 3,
"self" : true
},
{
"_id" : 1,
"name" : "local:27019",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 5625,
"optime" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
},
"optimeDurable" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
},
"optimeDate" : ISODate("2017-07-06T13:36:38Z"),
"optimeDurableDate" : ISODate("2017-07-06T13:36:38Z"),
"lastHeartbeat" : ISODate("2017-07-06T13:36:40.037Z"),
"lastHeartbeatRecv" : ISODate("2017-07-06T13:36:41.030Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "local:27020",
"configVersion" : 3
},
{
"_id" : 2,
"name" : "local:27020",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 5625,
"optime" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
},
"optimeDurable" : {
"ts" : Timestamp(1499348198, 1),
"t" : NumberLong(2)
},
"optimeDate" : ISODate("2017-07-06T13:36:38Z"),
"optimeDurableDate" : ISODate("2017-07-06T13:36:38Z"),
"lastHeartbeat" : ISODate("2017-07-06T13:36:40.987Z"),
"lastHeartbeatRecv" : ISODate("2017-07-06T13:36:39.473Z"),
"pingMs" : NumberLong(0),
"electionTime" : Timestamp(1499342576, 1),
"electionDate" : ISODate("2017-07-06T12:02:56Z"),
"configVersion" : 3
},
{
"_id" : 3,
"name" : "local:30000",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 11,
"lastHeartbeat" : ISODate("2017-07-06T13:36:41.309Z"),
"lastHeartbeatRecv" : ISODate("2017-07-06T13:36:41.514Z"),
"pingMs" : NumberLong(0),
"configVersion" : 3
}
],
"ok" : 1
}Comme on peut le constater, le PRIMARY peut changer. Dans le ReplicaSet ci-dessus, le serveur 3 (_id = 2, state = 1, port 27020) est devant le serveur maître (state = 2).
Tester la réplication
Pour tester la tolérance aux pannes, importons notre jeu de données (mongoimport) comme dans le premier chapitre, en utilisant le port du serveur PRIMARY (ici 27020). Vérifions l’existence des données avec une requête.
Simulons maintenant une panne du serveur PRIMARY en fermant le processus correspondant (dans le cas présent, le serveur ayant le port 27020). Vous pourrez alors constater qu’un nouveau serveur est élu PRIMARY (cette opération peut prendre un peu de temps).
Après connexion au nouveau PRIMARY, vous pourrez constater que votre requête retourne toujours le même résultat. Vous êtes tolérant aux pannes avec votre premier ReplicaSet !
Configuration
Il est possible de faciliter l’instanciation des ReplicaSet en créant un objet de connexion :
rsconf = {
_id: "rs0",
members: [
{_id: 0, host: "local:27018"},
{_id: 1, host: "local:27019"},
{_id: 2, host: "local:27020"}
]
};
rs.initiate (rs.conf) ;En environnement de production, chaque serveur est unique avec un fichier de configuration associé. Il est format YAML et se trouve dans le répertoire $MONGO/mongod.conf (ou /etc/mongod.conf pour linux). Il se présente sous la forme suivante :
systemLog:
destination: file
path: "/var/log/mongodb/mongod.log" #Fichier de log que nous verrons ensuite
logAppend: true
storage:
journal:
enabled: true
processManagement:
fork: true
#Permet de lancer le processus et de reprendre la main
net:
bindIp: local
port: 27018
#Adresse du serveur local et port d’écoute
replication:
oplogSizeMB: 512
replSetName: rs0
#Le nom de votre ReplicaSet
sharding: #A voir dans le chapitre suivant
clusterRole: shardsvr #C’est le mode par défaut. Sinon "configsvr"Vous pourrez trouver l’ensemble des options du fichier de configuration ici.
Pour utiliser ce fichier de configuration :
mongod --config mongod.conf
Le fichier oPlog
Comment les données sont-elles répliquées ? Une collection particulière est définie automatiquement au niveau du serveur primaire : le fichier oPlog. Cette collection particulière va stocker toutes les opérations de mises à jour (journalisation), et les réplicas vont lire cette collection pour les appliquer directement sur leur image.
Par défaut, la réplication se fait en mode asynchrone ; les réplicas lisent en mode pull ce fichier oPlog. Toutefois, cela ne veut pas dire que notre système NoSQL est asynchrone. À partir du moment où nos données ne sont accessibles que sur le PRIMARY en permanence, la donnée est toujours cohérente. Toutefois, nous nous poserons la question autrement par la suite dans la haute disponibilité.
Vous pourrez retrouver cette collection dans la base de données « local » et la collection « oplog.rs ». Vous pouvez effectuer une requête pour voir le contenu.
use local;
db.oplog.rs.find().pretty();On pourra y retrouver le timestamp d’insertion (ts), la version (v), le type d’opération ("op" : "i" pour insertion) et la collection cible ("ns" : "new_york.restaurants").
{
"ts" : Timestamp(1499753548, 21),
"t" : NumberLong(9),
"h" : NumberLong("-7247221887537468914"),
"v" : 2,
"op" : "i",
"ns" : "new_york.restaurants",
"o" : {
"_id" : ObjectId("59646c4cb48094070fd0d7fc"),
"address" : {
"building" : "284",
"coord" : {
"type" : "Point",
"coordinates" : [
-73.9829239,
40.6580753
]
},
"street" : "Prospect Park West",
"zipcode" : "11215"
},
"borough" : "Brooklyn",
"cuisine" : "American ",
"grades" : [
{
"date" : ISODate("2014-11-19T00:00:00Z"),
"grade" : "A",
"score" : 11
},
{
"date" : ISODate("2013-11-14T00:00:00Z"),
"grade" : "A",
"score" : 2
},
{
"date" : ISODate("2012-12-05T00:00:00Z"),
"grade" : "A",
"score" : 13
},
{
"date" : ISODate("2012-05-17T00:00:00Z"),
"grade" : "A",
"score" : 11
}
],
"name" : "The Movable Feast",
"restaurant_id" : "40361606"
}
}Cette collection est donc régulièrement interrogée pour mettre à jour les réplicas. Il faut toutefois savoir que celle-ci a une taille limitée (capped collection). Elle garantit une lecture en continu des mises à jour. Toutefois, en fonction du taux de mises à jour effectuées sur la base MongoDB, il peut être important d’augmenter la taille de l’oPlog pour ne pas perdre d’information. Sa taille par défaut dépend du type de moteur de stockage (par défaut WiredTiger) et du système d’exploitation : comme indiqué dans la documentation. Par défaut, il correspond à 5% de l’espace disque libre. L’option peut être mise à jour dans le fichier de configuration pour spécifier la taille maximale de ce fichier (par défaut 5Go). Nous avions mis précédemment 512Mo :
replication:
oplogSizeMB: 512Haute disponibilité
Afin de garantir un temps de réponse pour votre application, il est possible de modifier la gestion du ReplicaSet. Par défaut, toutes les requêtes de lectures sont effectuées sur le PRIMARY. Toutefois, cela alourdit sa charge ; il est également possible que celui-ci se trouve éloigné (physiquement sur le réseau) du client. Du coup, il est possible de router les requêtes de lectures sur les SECONDARY.
Pour ce faire, il faut définir les préférences de lecture avec les options suivantes :
Primary : valeur par défaut, lecture sur le serveur d’écriture.
PrimaryPreferred : si jamais le PRIMARY n’est plus disponible, les requêtes sont routées vers le SECONDARY en attendant que celui-ci réapparaisse (ou qu’un nouveau soit élu).
Secondary : Routé uniquement sur les SECONDARY. Cela soulage la charge du serveur primaire. Toutefois, on perd alors en cohérence puisque les données sont répliquées de manière asynchrone.
Nearest : Le serveur physique le plus proche sur le réseau (latence la plus faible) est interrogé directement par le client. Là non plus, la cohérence n'est pas garantie.
Le paramètre localThresholdMS du fichier de configuration permet de modifier la stratégie employée :
replication :
localThresholdMS: <"primary"|"primaryPreferred"|"Secondary"| "Nearest">Bien sûr, ces solutions font perdre en cohérence puisque les mises à jour n’attendent pas d’acquittement. Pour changer la stratégie d’accès aux données du ReplicaSet, le paramètre readConcern du fichier de configuration peut être modifié :
replication :
readConcern: <"majority"|"local"|"linearizable">Par défaut (local), les mises à jour sont asynchrones et seul le PRIMARY est consulté. Mais il est possible de vérifier que la majorité des réplicas soit synchronisée (majority), ou bien la lecture des données peut être ordonnée en fonction de l’instant d’écriture et de lecture (linearizable). Cet ordonnancement garantit la cohérence des lectures sur les réplicas mais réduit considérablement les performances.
Une dernière possibilité qu’offre un ReplicaSet est de favoriser le vote dans le cas d’une panne du PRIMARY. En effet, le système de vote peut prendre un certain temps. Vous pouvez accélérer ce vote en donnant une priorité entre les réplicas. Les réplicas qui ont la priorité la plus haute vont donc passer avant tous ceux qui ont une priorité inférieure. Pour ce faire, il suffit de modifier celles-ci avec :
cfg = rs.conf();
cfg.members[0].priority = 0.5;
cfg.members[1].priority = 2;
cfg.members[2].priority = 3;
rs.reconfig(cfg);Le serveur « 2 » sera alors prioritaire lors d’une élection. Attention, la commande reconfig peut faire changer le PRIMARY !
