Commençons par démystifier le terme "Big Data", qui est malheureusement galvaudé : l'immense majorité des applications informatiques génèrent trop peu de données pour que leurs auteurs se sentent concernés par la tendance du Big Data. Alors pourquoi parle-t-on autant de données massives aujourd'hui ? Évidemment, les Big Data subissent un effet de mode, tous media confondus. Mais la raison de fond est que les données massives ont permis des réalisations tout à fait impressionnantes : sans refaire l'historique de ces prouesses, on peut simplement rappeler les progrès considérables qu'a fait le domaine de l'intelligence artificielle dans les dix dernières années. Ces progrès sont aussi dûs à l'amélioration des méthodes existantes, certes, mais également à la qualité et à la quantité des données récoltées pour alimenter les méthodes d'apprentissage artificiel.
Alors, les Big Data sont-ils uniquement l'apanage de quelques applications hautement techniques et nécessitant la mise en place de moyens techniques sophistiqués ? Paradoxalement, les données massives restent sous-employées dans la plupart des applications traditionnelles. La raison en est que les méthodes et outils utilisés pour les Big Data n'ont pas encore été suffisamment popularisés. Pourtant, ces outils existent. Dans ce cours, nous allons nous intéresser au premier problème que rencontrent les créateurs d'applications : comment agréger des quantités importantes de données pour les rendre exploitables sans faire exploser la facture de l'infrastructure de stockage ? Si l'on ne sait pas répondre à cette question, il est impossible de faire du Big Data. Donc, dans ce cours, on va y répondre :-)
Définition des besoins
Commençons par définir ce dont nous avons besoin : nous allons stocker une grande quantité de données dans un dépôt qui va être la source d'information principale, voire unique, d'un certain nombre d'applications. Dans le jargon du Big Data, un tel dépôt est appelé un Data Lake.
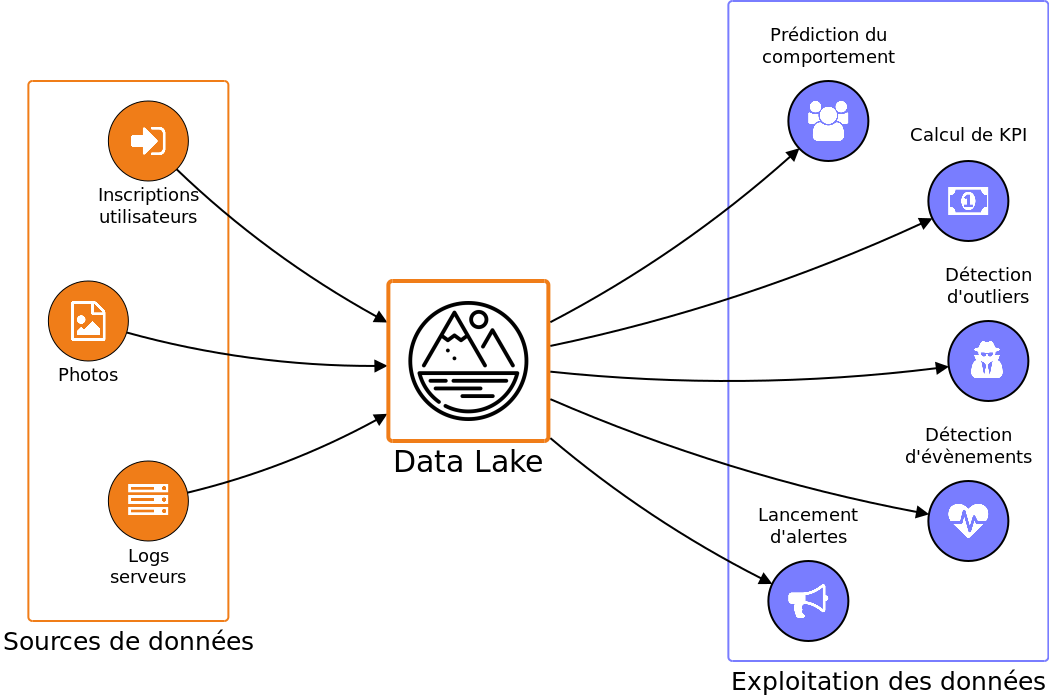
Ce lac de données va contenir des données de natures très variées : des fichiers de logs, des images, des fichiers binaires, etc. Il est difficile de prédire exactement ce qui va rentrer dans un data lake au moment de sa création. Ce qui est sûr, c'est que les données seront lues par un grand nombre d'applications variées. Pour ces applications, les données constitueront l'unique source de vérité. En effet, comme ces données seront volumineuses, il ne sera pas question de les dupliquer. Les données contenues dans le data lake sont donc précieuses. Pour cette raison, les données ne devront jamais être modifiées ni supprimées. Le data lake contiendra des jeux de données qui serviront de point de référence : c'est ce qu'on appelle le master dataset.
De l'autre côté, comment se comporteront les applications qui utilisent le master dataset ? On peut imaginer qu'elles vont lire les données au fur et à mesure qu'elles leurs parviennent, sans chercher à revenir en arrière aléatoirement. Autrement dit : les applications vont réaliser des opérations de lecture séquentielles. Par exemple, pour calculer le nombre moyen d'inscriptions par jour, une application va lire toutes les données d'une même journée dans l'ordre. Elle ne va pas avoir besoin de faire des opérations de lecture en accès aléatoire dans le master dataset.
On peut déduire de ces observations nos premiers besoins concernant le master dataset :
Les données ne seront écrites une seule fois (Write once)
Le master dataset ne subira que des ajouts (Append-only)
Le master dataset sera lu de nombreuses fois (Read many times)
Les opérations de lecture seront séquentielles (Sequential reads)
Ces besoins dessinent les contours d'une ébauche de solution pour ce qui est du stockage des donnés. Rajoutons une contrainte forte : comme le master dataset est voué à croître strictement avec le temps, il faut que la solution de stockage soit peu coûteuse. Par ailleurs, il faut que la solution retenue passe à l'échelle : il faut donc que le stockage se fasse de manière distribuée sur plusieurs machines. Mais de quelle augmentation de donnés parle-t-on au juste ? Prenons l'exemple de trois applications plus ou moins populaires qui génèrent entre 1 et 100 Go de données chaque jour :
1 Go/jour | 11.5 ko/s | 365 Go/an |
10 Go/jour | 115 ko/s | 3.65 To/an |
100 Go/jour | 1.15 Mo/s | 36.5 To/an |
L'augmentation annuelle de données peut être relativement conséquente (36.5 To/an) ; par contre, le débit moyen ramené à l'échelle de la seconde est assez faible (1.15 Mo/s). Cela signifie que la solution de stockage que nous allons choisir ne devra pas nécessairement offrir une vitesse d'écriture élevée. C'est pas mal, ça nous facilite la tâche.
Pour ce qui est de la présentation des données : comme on l'a déjà mentionné, on a besoin qu'elles soient exploitables par un grand nombre d'applications différentes, éventuellement rédigée dans des langages de programmation différents. Par ailleurs, l'organisation des données risque d'évoluer avec le temps et les besoins. Comme on ne permet pas que les données de notre master dataset soient modifiées, il faut que la solution utilisée pour structurer les données dispose d'une organisation évolutive de manière native.
Vous êtes le maillon faible au revoir
Au vu de cette énumération de besoins, on peut commencer par éliminer quelques usual suspects qu'on aurait pu initialement envisager. Tout d'abord, il n'est pas question de stocker notre master dataset dans une base de données relationnelle (RDBMS), type MySQL ou PostgreSQL. Ces bases de données sont coûteuses, supportent mal l'évolution du format des données et sont trop contraignantes pour stocker des données dans un format arbitraire. En fait, ce qui fait tout l'intérêt et la complexité des RDBMS, c'est ce dont on n'a pas besoin : les RDBMS sont particulièrement adaptées pour les accès aléatoires aux données ainsi que pour la modification de données existantes. Donc merci et au revoir.
D'un autre côté, on pourrait être tentés de stocker les données simplement sous la forme de fichiers textes semi-structurés, comme JSON ou XML. Ces formats de données sont simples et relativement peu coûteux, à condition de compresser les fichiers. Par contre, il ne permettent pas l'évolution du schéma des données, et ça c'est un problème majeur. Par exemple, prenons un document JSON simple qui représente un utilisateur nouvellement inscrit :
{
"username": "alice"
}Au bout de quelques jours, on se décide à ajouter la date de naissance des utilisateurs dans les documents de notre master dataset :
{
"username": "ada",
"year_birth": 1815
}Le master dataset contient désormais des documents avec ou sans date de naissance. Les nombreuses applications qui exploitent le master dataset vont toutes devoir mettre en place une certaine logique pour assurer que les documents sont correctement lus, qu'ils soient récents ou anciens. Bref, c'est la panade, et ça serait tout de même beaucoup plus sympathique si les données pouvaient se charger elles-même de cette rétro-compatibilité.
Ébauche de solution
Je ne vais pas faire durer le suspens plus longtemps. En fait, il existe des solutions qui répondent parfaitement aux besoin qu'on a définis. Et heureusement, sinon on n'aurait pas pu créer ce cours.
Pour ce qui est du stockage des données, la solution qui correspond le mieux est celle d'un système de fichiers distribué. Un système de fichiers est par exemple NTFS, ext4 ou ZFS. Un système de fichiers distribué stocke ses données de manière... distribuée (bravo). C'est-à-dire que ses données sont stockées sur plusieurs machines, ce qui lui permet théoriquement de passer à l'échelle. Par ailleurs, un système de fichiers stocke ses données sur des disques durs qui sont des supports très peu coûteux. Ces disques sont particulièrement adaptées pour l'écriture et la lecture séquentielles de données, aux vitesses qu'on a envisagées. Enfin, cerise sur le strudel, les systèmes de fichiers embarquent un système de permissions qui permettent d'empêcher facilement n'importe qui de modifier ou de supprimer des données.
Il existe plusieurs systèmes de fichiers distribués : nous avons choisi de présenter HDFS (Hadoop Distributed File System). En particulier, nous verrons qu'il existe une grande variété de librairies permettant d'utiliser HDFS dans différents langages de programmation.
Pour ce qui est de l'organisation des données dans notre master dataset, nous avons choisi de sérialiser les données avec Apache Avro. Sans vous gâcher la surprise, nous allons voir qu'Avro est un outil qui permet de stocker les données de manière compacte tout en embarquant le schéma des données. Cela nous garantit à tout moment la rétrocompatibilité des données. Pour cette raison, dans le reste de ce cours, nous allons parler de données sérialisées de manière semi-structurée.
Ce premier chapitre a été assez théorique, vous avez bien mérité un petit café.
C'était bon ? Allez, on embraye sur HDFS.
