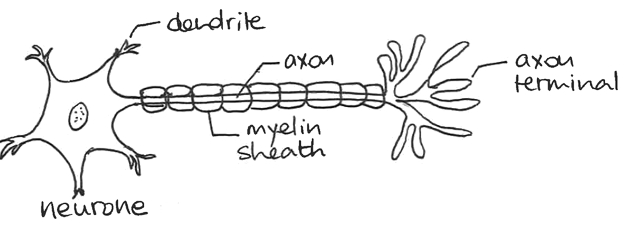
Neurones biologiques ou artificiels ?
Les réseaux de neurones, voilà un domaine du machine learning dont on entend beaucoup parler en ce moment... De la reconnaissance vocale à la recherche d'images, en passant par les voitures autonomes et AlphaGo, les récents succès de l'intelligence artificielle sont nombreux à se baser sur les réseaux de neurones profonds, plus connus sous le nom mystérieux de deep learning.
Mais l'histoire des réseaux de neurones artificiels remonte aux années 1950 et aux efforts de psychologues comme Franck Rosenblatt pour comprendre le cerveau humain. Initialement, ils ont été conçus dans le but de modéliser mathématiquement le traitement de l'information par les réseaux de neurones biologiques qui se trouvent dans le cortex des mammifères. De nos jours, leur réalisme biologique importe peu et c'est leur efficacité à modéliser des relations complexes et non linéaires qui fait leur succès.
Dans leur principe, les réseaux de neurones ne sont rien d'autre qu'une façon de construire des modèles paramétriques, c'est-à-dire pour lesquels la fonction de décision est explicite. Contrairement à d'autres algorithmes paramétriques comme la régression linéaire, ils permettent de construire facilement des modèles très complexes et non linéaires.
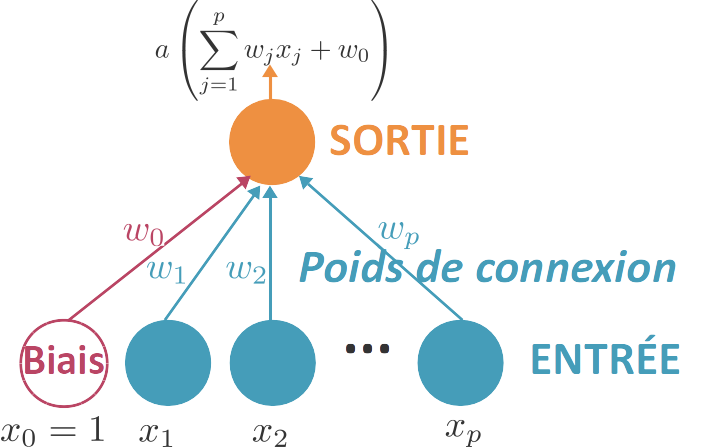
Architecture d'un perceptron
Commençons cependant par le commencement et le perceptron, ce réseau de neurone à une seule couche inventé par Rosenblatt dont je parlais plus haut.
Le perceptron est formée d'une première couche d'unités (ou neurones) qui permettent de « lire » les données : chaque unité correspond à une des variables d'entrée. On peut rajouter une unité de biais qui est toujours activée (elle transmet 1 quelles que soient les données). Ces unités sont reliées à une seule et unique unité de sortie, qui reçoit la somme des unités qui lui sont reliées, pondérée par des poids de connexion. Pour p variables , la sortie reçoit donc . L'unité de sortie applique alors une fonction d'activation a à cette sortie.
Un perceptron prédit donc grâce à une fonction de décision f définie par . Cette fonction a une forme explicite, il s'agit bien d'un modèle paramétrique.
Quelle fonction d'activation utiliser ?
Dans le cas d'un problème de régression, il n'est pas nécessaire de transformer la somme pondérée reçue en entrée. La fonction d'activation est la fonction identité, elle retourne ce qu'elle a reçu en entier.
Dans le cas d'un problème de classification binaire, on peut utiliser une fonction de seuil :
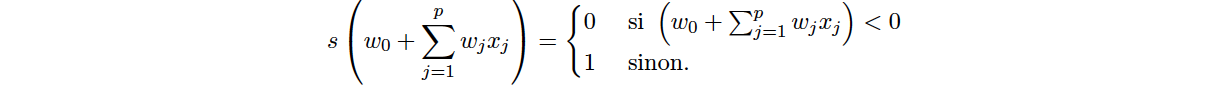
Comme dans le cas de la régression logistique, on peut aussi utiliser une fonction sigmoïde pour prédire la probabilité d'appartenir à la classe positive : .
Dans le cas d'un problème de classification multi-classe, nous allons modifier l'architecture du perceptron. Au lieu d'utiliser une seule unité de sortie, il va en utiliser autant que de classes. Chacune de ces unités sera connectée à toutes les unités d'entrée. On aura donc ainsi K.(p+1) poids de connexion, où K est le nombre de classes.
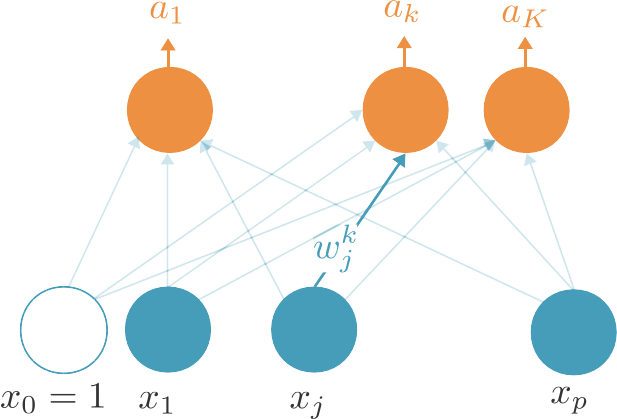
On peut alors utiliser comme fonction d'activation la fonction softmax. Il s'agit d'une généralisation de la sigmoïde, qui peut aussi s'écrire : nous allons utiliser . Si la sortie pour la classe k est suffisamment plus grande que celles des autres classes, son activation sera proche de 1 tandis que l'activation des autres sera proche de 0. On peut donc aussi considérer qu'il s'agit d'une version différentiable du maximum, ce qui nous aidera grandement pour l'apprentissage.
Apprentissage d'un perceptron
D'accord, mais comment apprendre les poids de connexion ?
Pour entraîner un perceptron, c'est-à-dire apprendre les poids de connexion, nous allons chercher à minimiser l'erreur de prédiction sur le jeu d'entraînement. Nous pourrions faire ça de manière explicite, comme dans le cas de la méthode des moindres carrés pour la régression linéaire ; cependant ce n'est vraisemblablement pas comme ça qu'un réseau de neurones biologiques fonctionne.
De plus, les réseaux de neurones biologiques sont supposés êtres plastiques, c'est-à-dire qu'ils s'adaptent constamment, en fonction des signaux qu'ils reçoivent. Ainsi, nous allons supposer que nos n observations ne sont pas observées simultanément mais séquentiellement, l'une après l'autre.
L'entraînement d'un perceptron est donc un processus itératif. Après chaque observation, nous allons ajuster les poids de connexion de sorte à réduire l'erreur de prédiction faite par le perceptron dans son état actuel. Pour cela, nous allons utiliser l'algorithme du gradient : le gradient nous donnant la direction de plus grande variation d'une fonction (dans notre cas, la fonction d'erreur), pour trouver le minimum de cette fonction il faut se déplacer dans la direction opposée au gradient. (Lorsque la fonction est minimisée localement, son gradient est égal à 0.)
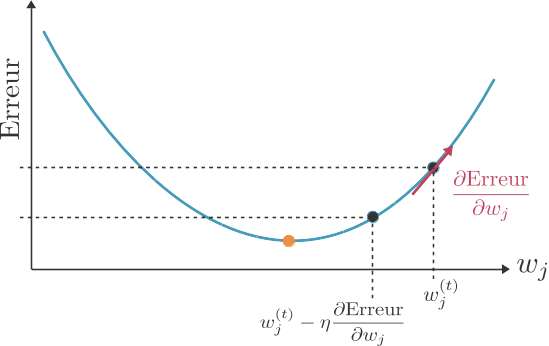
Ainsi, nous commençons par choisir aléatoirement des valeurs initiales pour nos poids de connexion. Ensuite, après chaque observation , nous allons appliquer à chacun des poids la règle de mise à jour suivante :
.
On peut itérer plusieurs fois sur l'intégralité du jeu de données. On itère généralement soit jusqu'à ce que l'algorithme converge (le gradient est suffisamment proche de 0) ou, plus fréquemment, pour un nombre fixé d'itérations.
est un hyperparamètre du réseau de neurones, appelé la vitesse d'apprentissage (ou learning rate en anglais).
Comment définir la fonction d'erreur ?
Dans le cas de la régression, nous allons choisir l'erreur quadratique (comme pour une régression linéaire) :
La règle de mise à jour est donc
Dans le cas de la classification, nous allons choisir l'entropie croisée. Dans le cas binaire l'entropie croisée est définie par
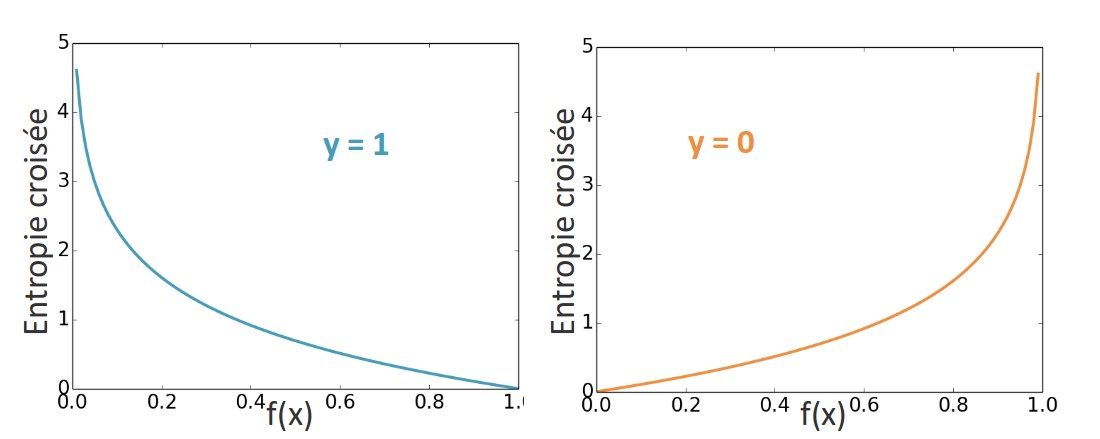
L'entropie croisée est un peu plus compliquée à différencier que l'erreur quadratique, mais il se trouve après quelques calculs que la règle de mise à jour des poids de connexion est encore une fois !
Et cela est aussi vrai pour la version multiclasse de l'entropie croisée : la règle de mise à jour est .
En résumé
Le perceptron permet d'apprendre des modèles paramétriques basés sur une combinaison linéaire des variables.
Le perceptron permet d'apprendre des modèles de régression (la fonction d'activation est l'identité), de classification binaire (la fonction d'activation est la fonction logistique) ou de classification multi-classes (la fonction d'activation est la fonction softmax).
Le perceptron est entraîné par des mises à jour itératives de ses poids grâce à l'algorithme du gradient. La même règle de mise à jour des poids s'applique dans le cas de la régression, de la classification binaire ou de la classification multi-classes.
Le perceptron est un modèle linéaire relativement simple. Dans la suite de ce cours, nous allons découvrir comment obtenir des modèles non linéaires et beaucoup plus complexes en empilant des perceptrons !
