Dans le monde actuel, où la quantité de texte non structuré, augmente drastiquement (commentaires, articles de blog, etc.), il serait vraiment utile d’avoir des outils qui permettent de structurer automatiquement l’information, de manière à pouvoir rapidement accéder à ce qui nous intéresse, filtrer le bruit mais aussi détecter l’apparition de nouveau sujet d’intérêts.
On peut retrouver cette nécessité à plusieurs niveau dans les applications :
Détecter les fameux “trending topics” de Twitter
Trouver les nouveaux sujet d’informations abordés par les médias
Détecter un nouveau stock intéressant d’après un groupement de textes d’experts
Organiser un corpus de textes scientifiques autour des thématiques abordées
Trouver les différentes aspects d’un produit abordés par des commentaires afin de pouvoir plus facilement l’améliorer à partir de feedback utilisateur
C’est dans ce cadre qu’intervient la modélisation de sujets (topic modeling en anglais) qui représente le spectre des différentes approches permettant cette détection.
Dans ce chapitre, on va étudier les plus populaires, afin d’avoir une intuition de cette famille d’algorithmes. Il faut savoir, en revanche, qu’il reste difficile d’appliquer directement ces algorithmes à toute les situation et qu’il existe un grand nombre de variantes spécifiques à des problématiques plus précises qui correspondront à ce que vous recherchez.
Il faut donc se documenter et comprendre les différents critères différenciants (e.g. modélisation dynamique des sujets dans le temps, longueur du document, nombre de sujets abordés, etc.) qui vous permettront d’effectuer un choix informé.
C’est aussi une famille de méthode utilisé essentiellement en exploration voire semi-supervisée, c’est à dire qui permet de détecter si effectivement il y a de grandes catégories abordées, et ensuite les affiner lors du passage en production, et supervision des nouveaux documents entrants.
Pour résumer, la modélisation automatique de sujet permet de détecter les sujets latents abordés dans un corpus de documents, assigner les sujets détectés à ces différents documents. On peut ensuite utiliser ces sujets pour effectuer des recherches plus rapide, organiser les documents ou les résumer automatiquement.
Première intuition : Latent Dirichlet Allocation (LDA)
La première méthode vraiment efficace est nommé LDA (Latent Dirichlet Allocation). C’est une méthode non-supervisée générative qui se base sur les hypothèses suivantes :
Chaque document du corpus est un ensemble de mots sans ordre (bag-of-words) ;
Chaque document aborde un certain nombre de thèmes dans différentes proportions qui lui sont propres ;
Chaque mot possède une distribution associée à chaque thème . On peut ainsi représenter chaque thème par une probabilité sur chaque mot.
représente le thème du mot
Puisque l'on a accès uniquement aux documents, on doit déterminer quels sont les thèmes, les distributions de chaque mot sur les thèmes, la fréquence d’apparition de chaque thème sur le corpus.
Une représentation formelle sous forme de modèle probabiliste graphique est la suivante :
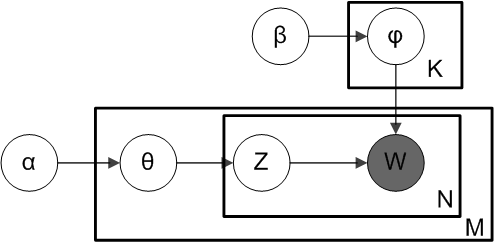
Pour rappel, un modèle génératif définit une probabilité de distribution jointe sur les différentes variables identifiées, à la fois observées et latentes. Une fois ces variables identifiées, ainsi que les différentes probabilités de distribution associées, l’objectif est de retrouver par exemple les distributions latentes par rapport aux variables observées.
Dans notre cas, nous souhaitons retrouver les distributions de mots sur les différents thèmes, les différentes proportions de thèmes pour chaque document, les proportions d’apparition d’un thème sur le corpus. Tout cela à partir des différents documents. Ce qui nous permet par la suite de déterminer le thème d’un document, les mots les plus associés à certains thèmes, etc.

Comme nous l'avons dit en introduction, ce modèle représente une version de base assez générale de la modélisation d’un corpus de documents. Il est possible d’ajouter des hypothèses supplémentaires sur la structure des données afin de capturer une plus grande partie de l’organisation de l’information. A titre d’exemple, voici une liste des hypothèses supplémentaires qui mènent à une modélisation plus riche :
La distribution des mots sur les thèmes évoluent avec le temps. Ce qui signifie qu’il faut créer une séquence de distribution pour chaque thème qui permet de modéliser l’évolution du thème dans le temps.
Certains thèmes sont plus proches que d’autres. L’hypothèse d’utiliser la distribution de Dirichlet considère que les différents thèmes sont complètement indépendants alors qu’en réalité certains thèmes ont en général plus de chances d’apparaître ensemble.
Laissez la partie inférence aux librairies !
Effectuer l’inférence de ce modèle est relativement complexe techniquement. Il faut notamment passer par des approximations et des algorithmes qui simplifient le modèle afin de pouvoir le calculer (par exemple mean field ou gibbs sampling). Dans tous les cas on va utiliser des packages tout fait afin de travailler sur nos données.
Les plus connus sont déjà intégrés directement dans les librairies (scikit implémente une version de LDA) mais il faudra par la suite effectuer vos propres recherche afin de trouver des implémentations que vous pourrez utiliser dans des cas plus précis.
Utiliser LDA sur un cas pratique : Le newsgroup dataset
Afin d’illustrer le type de retours que l’on peut avoir avec ce genre de méthodes, on va appliquer l’algorithme du LDA sur un dataset classique déjà présent dans la librairie scikit : le newsgroup dataset qui regroupe un ensemble de 20,000 document articles d'actualité.
Prétraitement
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'))
documents = dataset.dataCréer le modèle LDA
from sklearn.decomposition import LatentDirichletAllocation
n_topics = 20
# Créer le modèle LDA
lda = LatentDirichletAllocation(
n_components=n_topics,
max_iter=5,
learning_method='online',
learning_offset=50.,
random_state=0)
# Fitter sur les données
lda.fit(tf)Evaluation
On affiche les mots les plus représentatifs des sujets modélisés, afin de nous donner une idée de leur signification et voir si effectivement on trouve des catégories claires pour les humains et représentatifs de notre corpus.
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic {}:".format(topic_idx))
print(" ".join([feature_names[i] for i in topic.argsort()[:-no_top_words - 1:-1]]))
no_top_words = 10
display_topics(lda, tf_feature_names, no_top_words)
Topic 0: government people mr law gun state president states public use Topic 1: drive card disk bit scsi use mac memory thanks pc Topic 2: said people armenian armenians turkish did saw went came women Topic 3: year good just time game car team years like think Topic 4: 10 00 15 25 12 11 20 14 17 16 Topic 5: windows window program version file dos use files available display Topic 6: edu file space com information mail data send available program Topic 7: ax max b8f g9v a86 pl 145 1d9 0t 34u Topic 8: god people jesus believe does say think israel christian true Topic 9: don know like just think ve want does use good
Comme on peut le voir, quelques sujets qui ont été modélisés sont effectivement interprétables : le sujet 4 représente simplement les nombres. Le sujet 5 représente globalement l'informatique. Le sujet 8 semble représenter la religion, etc etc.
Une alternative, NMF
Une autre type de modélisation de sujet automatique non supervisée est NMF (Negative Matrix Factorisation).
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import NMF
# NMF is able to use tf-idf
tfidf_vectorizer = TfidfVectorizer(max_df=0.95,
min_df=2,
max_features=no_features,
stop_words='english')
tfidf = tfidf_vectorizer.fit_transform(documents)
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
no_topics = 20
# Run NMF
nmf = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd')
nmf.fit(tfidf)
no_top_words = 10
display_topics(nmf, tfidf_feature_names, no_top_words)
Topic 0: people don think like know time right good did say Topic 1: windows file use dos files window using program problem card Topic 2: god jesus bible christ faith believe christian christians church sin Topic 3: drive scsi drives hard disk ide controller floppy cd mac Topic 4: game team year games season players play hockey win player Topic 5: key chip encryption clipper keys government escrow public use algorithm Topic 6: thanks does know mail advance hi anybody info looking help Topic 7: car new 00 sale price 10 offer condition shipping 20 Topic 8: just like don thought ll got oh tell mean fine Topic 9: edu soon cs university com email internet article ftp send
Conclusion
L'objectif de ce type de modélisation de sujets est de récupérer de potentielles catégories pour des traitements ultérieurs. Cette modélisation offre surtout une meilleure compréhension de la structuration du texte en vue de création de features manuelles (mettre l'accent sur certains mots, comprendre ce qui définit une catégorie, etc.)
