Understand How Recurrent Neural Networks Work
Understand When To Use Recurrent Neural Networks
Recurrent neural networks (RNNs) have evolved from the need to address data, which can be seen as a series - i.e., time series of share prices of a company, sensor data, or text. You might be wondering how this data is different from other types of data, and the answer is simple: previous data points influence the value of later data points. These datasets are different from the pizza types; for example, all the data points of pizza types were independent of each other.
To better understand this concept, let's play a game: I am thinking of a word that starts with the letter "t." Can you guess what word it is? :zorro:
You will probably not think of words that begin with "tz," or "tt." Why not? Because you rarely see those words (low probability), maybe you thought about words that start with "ta" like tale or "te" like tent because you usually use and hear those words (high probability).
The character the word started with has a considerable influence on the next character - previous data points influence future data points. And this will happen across all the characters in the word, not just the first one.
Recurrent neural networks are built with extra capacity that allows them to use previous data points for every new prediction they make. In its simplest form, a neuron that is fed its previous prediction with the next data point creates a recurrent neural network:
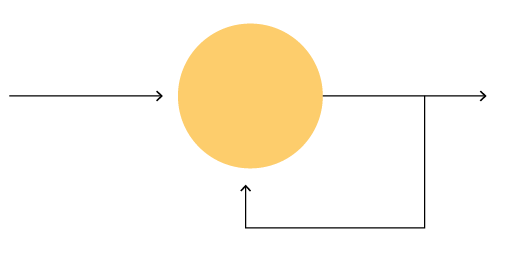
The above works, but it only uses one previous data point as input information. That is not always enough. If you see the letter “i,” you might think that many characters are likely to come after it, such as “m” to create image or “n” for integer. However, if I told you that a whole sequence, such as “rai,” was the input information, you might think that the next character is “n” to create rain.
Several types of neurons that can retain more information about past data points were created. Examples of these include gated recurrent units (GRU) and long short-term memory (LSTM).
Understand Long Short-Term Memory (LSTM)
What Is It?
Let's talk about LSTM neurons. They were first proposed by Hochreiter and Schmidhuber in 1997 and have had many improvements ever since. LSTMs have two output signals that are fed back in to:
The cell state.
The hidden state (which is also transformed into the output).
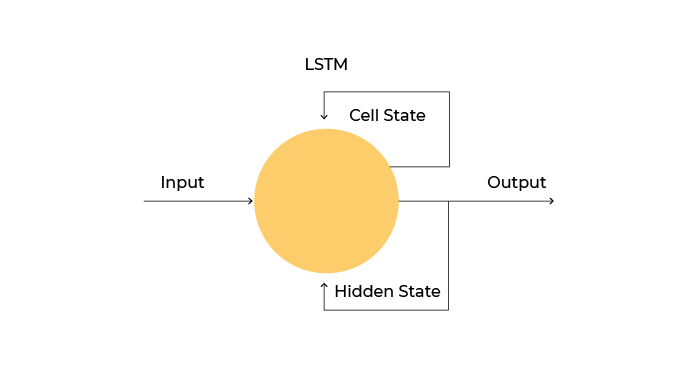
To better understand how LSTMs work, let's use the word "learning." The model is tasked with predicting what character follows after "learnin." When making its prediction, the LSTM will consider multiple pieces of information:
The cell state, which is its memory and holds information about the previously seen characters - “learni.”
The hidden state or information from the last output when it predicted “i.”
The input is being fed now or the current character it sees -”'n.”
How Does It Work?
To achieve this, LSTMs take a two-step approach:
Step 1: Update the cell state based on the new input and data from the last prediction This step updates the memory/trend based on the new data.
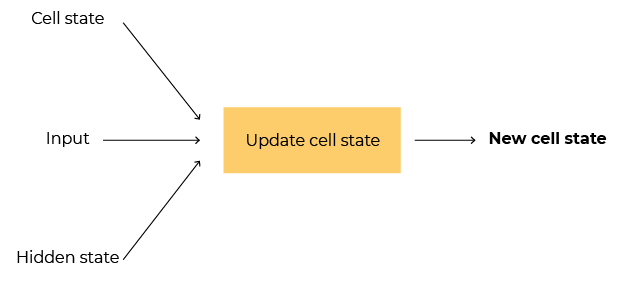
Step 2: Update the hidden cell state/output based on the new input, new cell state, and information from the previous time step. This step is the one that generates the output.
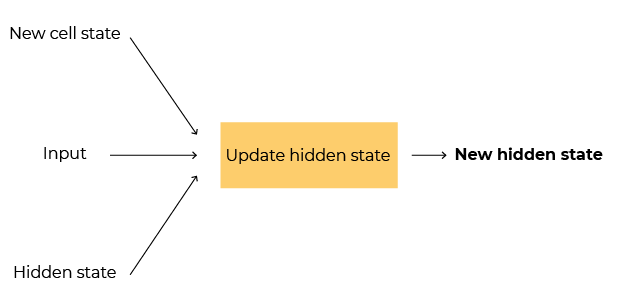
This structure decides both the neuron's output and changes to the cell state (memory) and the hidden state (latest information).
The hidden state and the cell state are both vectors (a row of numbers) with the same length. They get reset after a session of predictions i.e., if you were predicting pizza recipes, they would get reset after every recipe.
Let’s Recap!
Recurrent neural networks (RNNs) are built out of neurons that receive their previous output as an additional input when making predictions.
They are handy in situations where previous data points hold information about the current data point. Such examples include a time series of sensor data, trading data, text data.
Well-known neuron types are the gated recurrent unit (GRU) and the long short-term memory (LSTM).
LSTM neurons rely on two feedback inputs when making predictions - cell state and hidden state. They also operate in two steps: first, update the cell state; next, generate a new hidden state and an output.
Let’s build a network that contains an RNN!
