Extract and Transform Data With Web Scraping
What Is Web Scraping?
Web scraping is the automated process of retrieving (or scraping) data from a website. Instead of manually collecting data, you can write Python scripts (a fancy way of saying a code process) that can collect the data from a website and save it to a .txt or .csv file.
Let’s say you’re a digital marketer, and you’re planning a campaign for a new type of blazer. It would be helpful to collect information like the price and description for similar blazers. Instead of manually searching and copy/pasting that information into a spreadsheet, you can write Python code to automatically collect data from the internet and save it to a CSV file.
Throughout these next two chapters, I’ll be taking you step by step through a web scraping exercise. You’ll learn some cool new things and get to practice some of the tools you’ve used already, like functions and variables. Make sure to follow along in your text editor. You’ll get much more out of this if you carry out the steps on your end along the way!
We’re going to extract data about news and communications from the UK government’s services and information website, transform the data into our desired format, and load the data to a CSV file for a web scraping exercise.
ETL: Extract, Transform, Load
ETL (extract, transform, load) is the “general procedure of copying data from one or more sources into a destination system which represents the data differently from the source” (Wikipedia). That’s just a fancy way to say that ETL is the process of taking data from one place, massaging it a little, and saving it in another place.
Web scraping is one form of ETL: you extract data from a website, transform it to fit the format you want, and load it into a CSV file.
To extract data from the web, you need to know a few basics about HTML, the backbone of each web page you see on the internet. If you haven't worked with HTML yet, don't worry; we'll go over what you need to know for web scraping below.
The Basics of Reading HTML Tags
HTML is the language used for all the web pages you see on the internet. If you right-click on any website (including this one) and press View Page Source, you’ll be able to see the HTML that is used to display what you are seeing.
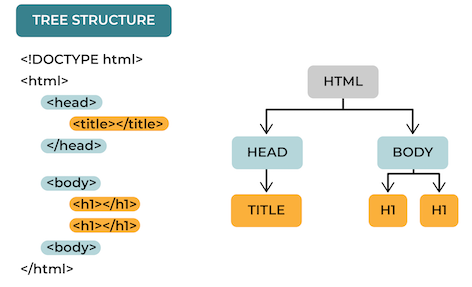
HTML is built in a tree-like structure called the Document Object Model, or DOM. The DOM is made up of a bunch of different tags that can be nested into each other. Different tags can represent each part of an HTML page, and most elements have an opening and closing one.
An opening tag looks like: <element_name> and a closing tag usually has the same element_name just with a / in the front, e.g., </element_name> . For example, every web page has the html opening tag, <html> , and the closing tag, </html>. All the information you want in that element needs to be between the opening and closing tags.
There are many different types of tags, each representing different elements that you can put into your web page. Here are some common ones:
<p>for a paragraph element.<b>for a bold element.<a>for a hyperlink.<div>a new section or division.
The HTML tag represents the top level of the tree in the DOM and the rest of the tags are like children of the corresponding parent tags.
A couple of important things to know about HTML tags are class and id attributes, which are ways to give different HTML elements identifiers. For example, if you want to identify all the items of clothing with a single identifier, you can write the following:
<p class="clothing">shirt</p>
<p class="clothing">socks</p>This way, you know that all the items with the “clothing” class will have a clothing item contained within. You can use this “clothing” class later to get all the items marked with the same class.
Similarly, to get all the titles and descriptions from the UK services and information site, we can find the class or ID that each of those items has. We can use the “View Page Source” button to see the HTML of the page and look for the identifier we need.
If you scroll down on the source page or use ctrl+f to find the first news title, you can see that the title and description are straight in the HTML!
Here is a sample of some of the HTML that we need to extract from the web page:
<li class="gem-c-document-list__item ">
<a data-ecommerce-path="/government/news/restart-of-the-uk-in-japan-campaign--2" data-ecommerce-row="1" data-ecommerce-index="1" data-track-category="navFinderLinkClicked" data-track-action="News and communications.1" data-track-label="/government/news/restart-of-the-uk-in-japan-campaign--2" data-track-options='{"dimension28":20,"dimension29":"Restart of the UK in JAPAN campaign"}' class="gem-c-document-list__item-title gem-c-document-list__item-link" href="/government/news/restart-of-the-uk-in-japan-campaign--2">Restart of the UK in JAPAN campaign</a>
<p class="gem-c-document-list__item-description">The British Embassy, British Consulate-General and the British Council, in partnership with principal partners Jaguar Land Rover and Standard Chartered Bank are proud to announce the resumption of our ambitious UK in JAPAN c…</p>Don’t get overwhelmed by all this code! You just have to look for the title and description class element. Don’t worry if you don’t find it right away, we’ll go into more detail on this later. 😉
Since this information is available on the web, we can write a Python script to extract the data we want straight from the page. We’ll be using the requests and Beautiful Soup libraries to help!
The Requests Library
To extract data from the website, we need to use the requests library. Remember that it provides functionality for making HTTP requests. We can use it since we’re trying to get data from a website that uses the HTTP protocol (e.g., http://google.com).
The requests library contains a .get() function that we can use to get the HTML from the site.
To apply this to the web scraping exercise, we’ll use the requests library to get the HTML of the UK news and communications page into our Python code. In the code below, we import the library, save the URL we want to web scrape in a url variable, and then use the .get() method to retrieve the HTML data. If you run the code below, you'll see the HTML source printed out in the console.
import requests
url = "https://www.gov.uk/search/news-and-communications"
page = requests.get(url)
#See html source
print(page.content)Even though we have all the HTML saved in our code, it still looks like a whole lot of mumbo jumbo. We have to figure out how to parse out the exact elements that we want - and we can use Beautiful Soup to do just that!
The Beautiful Soup Library
Now that we have the HTML source, we need to parse it. The way to parse the HTML is through the HTML attributes of class and id mentioned earlier.
We can use Beautiful Soup to help find the elements that can be identified with the class or the ID that we want to find. Similar to any library, we’ll use pip to install Beautiful Soup.
pip install beautifulsoup4Next, we’ll import Beautiful Soup and create a “soup object” out of the HTML we got using requests:
import requests
from bs4 import BeautifulSoup
url = "https://www.gov.uk/search/news-and-communications"
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')The soup variable we made using Beautiful Soup has all these extra features that make it easier to get data from the HTML. Before we get data from the UK news and communications page, we’ll go through some of the awesome functionality of Beautiful Soup using the sample HTML snippet below.
<html><head><title>The Cutest Dogs Around</title></head>
<body>
<p class="title"><b>Best dog breeds</b></p>
<p class="dogs">There are many awesome dog breeds, the best ones are:
<a href="http://example.com/goldendoodle" class="breed" id="link1">GoldenDoodle</a>,
<a href="http://example.com/retriever" class="breed" id="link2">Golden Retriever</a> and
<a href="http://example.com/pug" class="breed" id="link3">Pug</a>;
</p>
</body>
</html>Once we create a “soup object” out of this HTML, we can access all the elements of the page really easily!
#Get HTML page title
>> soup.title
<title>The Cutest Dogs Around</title>
#Get string of HTML title
>> soup.title.string
"The Cutest Dogs Around"
#Find all elements with <a> tag
>>soup.find_all('a')
[ <a href="http://example.com/goldendoodle" class="breed" id="link1">GoldenDoodle</a>,
<a href="http://example.com/retriever" class="breed" id="link2">Golden Retriever</a>
<a href="http://example.com/pug" class="breed" id="link3">Pug</a>]
# Find element with id of “link1”
>> soup.find(id="link1")
<a href="http://example.com/goldendoodle" class="breed" id="link1">GoldenDoodle</a>,
#Find all p elements with class “title”
>> soup.find_all("p", class_="title")
"Best Dog Breeds"This is just a taste of how Beautiful Soup helps you easily get the specific elements that you need from an HTML page. You can get items by tag, ID, or class.
Let’s apply this to the UK government services and information exercise. We already made the web page into a soup object using this line soup = BeautifulSoup(page.content, 'html.parser') .
Now let’s see what data we can get from the news and communications page. First, let’s get the titles of all the stories. After inspecting the HTML page, we can see that the titles of all the news stories are in link elements denoted by <a> tags and have the same class: gem-c-document-list__item-title.
Here’s an example:
<a data-ecommerce-path="/government/news/restart-of-the-uk-in-japan-campaign--2" data-ecommerce-row="1" data-ecommerce-index="1" data-track-category="navFinderLinkClicked" data-track-action="News and communications.1" data-track-label="/government/news/restart-of-the-uk-in-japan-campaign--2" data-track-options='{"dimension28":20,"dimension29":"Restart of the UK in JAPAN campaign"}' class="gem-c-document-list__item-title gem-c-document-list__item-link" href="/government/news/restart-of-the-uk-in-japan-campaign--2">Restart of the UK in JAPAN campaign</a> We can use both of these together to get a list of all the title elements:
titles = soup.find_all("a", class_="gem-c-document-list__item-title")This gives us a list of all the elements with the gem-c-document-list__item-title class. To view just the string value within the element, we can loop through each item in the list and print out the string element.
>> for title in titles:
>> print(title.string)
"Restart of the UK in JAPAN campaign"
"Joint Statement on the use of violence and repression in Belarus"
"Foreign Secretary commits to more effective and accountable aid spending under new Foreign, Commonwealth and Development Office"
"UK military dog to receive PDSA Dickin Medal after tackling Al Qaeda insurgents."Check out the screencast below to walk through the steps of extracting the HTML from the web page, finding the right identifier for the titles, and printing out just the title strings for each title.
Now that you know how to get the page titles, try getting the page descriptions on your own! We’ll cover the rest of this below.
The descriptions are in a <p> tag and have the gem-c-document-list__item-description class, like below:
<p class="gem-c-document-list__item-description">Joint Statement by the Missions of the United States, the United Kingdom, Switzerland and the European Union on behalf of the EU Member States represented in Minsk on the use of violence and repression in Belarus</p> To get all the descriptions, type:
descriptions = soup.find_all("p", class_="gem-c-document-list__item-description")Now that we've gone through this step by step, it's your turn to look at the code. You can download it by clicking here. Go through it on your own and check that you understand all of it.
Now that we have extracted the web data, we need to transform it to fit the format we want to save.
Transform Data
You transform data when you convert it from one format into another. It can be as simple as converting a string to a list, or thousands of lists into dictionaries. Usually, it entails combining different data points. There are many ways to transform data, and ultimately the decisions depend on the type of data and the format you want it in.
Some examples of transforming data:
Converting a date field format from December 28, 2019 to 28/12/19.
Converting a money amount in dollars to euros.
Standardizing email or postal addresses.
For our UK news and communications example, we’ll save all the titles and descriptions from the HTML page into lists of strings. Instead of printing the string information to the console like earlier, we want to save the elements into a list:
bs_titles = soup.find_all("a", class_="gem-c-document-list__item-title")
titles = []
for title in bs_titles:
titles.append(title.string)Here we start with an empty list called titles. Then we loop through all the elements in the bs_titles list and append just the string version of the title into our titles list. Now the titles list will be a list of strings of all the titles on the HTML page.
To walk through this code line by line, check out the screencast below!
Follow the same approach to extract and save the page descriptions.
bs_descriptions = soup.find_all(“p”, class_=“gem-c-document-list__item-description”)
descriptions = []
for desc in bs_descriptions:
descriptions.append(desc.string)Level Up: Extract and Transform Data With Web Scraping

Context:
In this exercise, you will extract information from an HTML file using the Beautiful Soup package.
Instructions:
1. Use the beautifulsoup4 module to extract the following information and store it in variables:
The title of the page (<title> );
The text of the <h1> tag;
The names and prices of the products in the list (<ul> ) (store them in a list);
The descriptions of the products in the list (<ul> ) (store them in a list).
2. Display the extracted information in the console.
3. Convert the prices to dollars (consider that dollar = euro * 1.2 ).
4. Display the new list with the name and the new price in dollars.
Once you have completed the exercise, you can run the following command in the VS code terminal pytest tests.py
Let’s Recap!
Web scraping is the automated process of retrieving data from the internet.
ETL stands for extract, transform, load, and is a widely used industry acronym representing the process of taking data from one place, changing it up a little, and storing it in another place.
HTML is the backbone of any web page, and understanding its structure will help you figure out how to get the data you need.
Requests and Beautiful Soup are third-party Python libraries that can help you retrieve and parse data from the internet.
Parsing data means preparing it for transformation or storage.
Now that you've seen how to extract and transform web data, you’ll learn how to load web data!
