Mettez à jour et sauvegardez les éléments de votre infrastructure
L’email envoyé par l’équipe de veille est particulièrement anxiogène. Il vous informe de mettre à jour vos systèmes le plus rapidement possible. Méthodique, vous commencez à lister les services qui pourraient être concernés, comme RDS ou EC2.
Découvrez les mises à jour dans Amazon RDS
Amazon effectue lui-même les mises à jour des systèmes d’exploitation des machines qui portent votre base de données, ainsi que les mises à jour de sécurité du moteur de base de données.
Vous n’avez donc rien à faire, à part vous assurer que le créneau de maintenance est configuré à un intervalle où vous n’avez pas de trafic sur votre base, afin de ne pas avoir de ralentissement ni de coupure de service.
Mettez à jour les machines dans un groupe de mise à l’échelle
Créez une nouvelle image disque
Contrairement à RDS, Amazon ne gère pas le système d’exploitation des machines EC2. Sa seule activité est de gérer la virtualisation du système sous-jacent. Vous devez par conséquent mettre à jour vous-même le système d’exploitation et l’application à l’intérieur.
La problématique est de faire en sorte de mettre à jour vos éléments qui se trouvent dans un groupe de mise à l’échelle, sans pour autant engendrer une coupure de service. Pour cela, plusieurs étapes sont nécessaires ; c’est ce que nous allons voir.
En premier lieu, il est nécessaire de créer une nouvelle image disque “à jour”. Pour cela, nous allons prendre l’image disque actuelle, la déployer dans une machine, faire la mise à jour, puis créer une nouvelle image.
Dans le service EC2, cliquez sur Instances puis Launch instances. Dans l’onglet My AMIs, sélectionnez l’image actuelle de vos machines, puis suivez les étapes de création de la machine EC2 telles que vous les avez abordées dans la partie 3, pour vous connecter à l’instance.
Une fois sur l’instance, lancez vos commandes de mise à jour ; par exemple :
sudo yum update
Laissez les mises à jour s’installer, puis arrêtez la machine avec Actions > Instance state > Stop. Nous allons à présent, comme tout à l’heure, créer une nouvelle image disque qui contient ces mises à jour. Dans la description de l’instance, cliquez sur /dev/sda1 devant le mot Root device, puis sur votre volume vol-xxxx devant EBS ID.
Comme précédemment, créez un snapshot avec Actions puis Create Snapshot. Dans le panneau de gestion des instantanés, cliquez sur votre snapshot, puis sélectionnez Actions et Create image. Choisissez un nom, puis cliquez sur Create.
Nous avons à présent une nouvelle image à côté de l’ancienne :
Il est temps de mettre à jour nos machines ! Pour cela, il faut modifier le groupe de lancement.
Afin de ne pas provoquer de coupure, AWS n’arrête pas les machines “obsolètes” après la mise à jour du groupe de lancement ; il faudra alors demander au groupe de mise à l’échelle de démarrer des machines à jour, puis de détruire les anciennes pour revenir à une capacité normale.
Mettez à jour les machines
Vous vous souvenez, il n’est pas possible de mettre à jour un groupe de lancement. Heureusement, nous avons tout automatisé avec CloudFormation, et il suffit de mettre à jour l’identifiant de l’image dans notre stack, pour que tout soit modifié !
Dans le panneau de gestion de CloudFormation, cliquez sur votre stack, puis faites Action > Update stack. Nous n’avons pas modifié le contenu de notre stack, mais nous allons en modifier un paramètre. Par conséquent, cliquez sur Use current template et dans le panneau suivant, remplacez AmiIdentifier par votre nouveau numéro d’AMI. Enfin cliquez Next, Next et Update Stack ; vous avez l’habitude :).
CloudFormation vous affiche au passage les changement qu’il va effectuer :
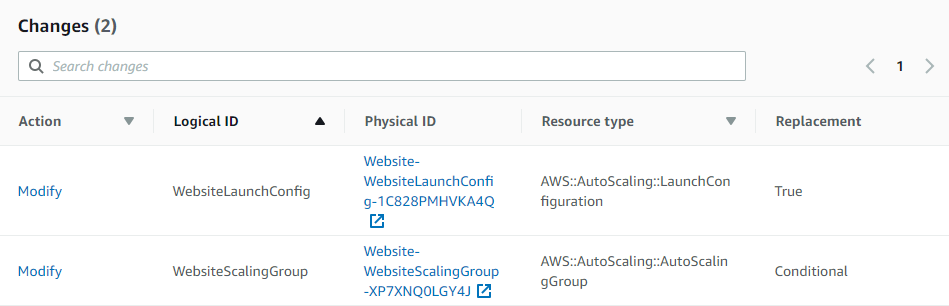
CloudFormation effectue plusieurs choses en notre nom :
Création d’un nouveau groupe de lancement avec la nouvelle image.
Changement de la référence du groupe de mise à l’échelle pour pointer sur notre nouveau groupe de lancement.
Suppression de l’ancien groupe de lancement.
Une fois les étapes effectuées, vous avez un groupe de lancement capable de lancer des machines avec la nouvelle image. Il va falloir demander à AWS de lancer des machines “à jour”, et de progressivement détruire les anciennes. Pour cela, suivez les étapes suivantes :
dans la configuration de votre groupe de mise à l’échelle, augmentez le champ Desired capacity.
Attendez quelques minutes que AWS démarre votre nouvelle machine ;n'oubliez pas de noter le numéro de l’ancienne et de la nouvelle instance ;
allez dans la configuration de votre Target Group ; vous devriez voir deux machines, l’ancienne et la nouvelle.
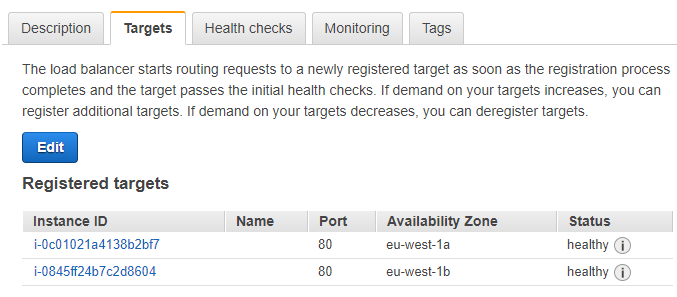
Pour ne pas déconnecter un utilisateur actif au milieu d’une requête, il faut dire au Load Balancer d’arrêter d’envoyer du trafic à l’ancienne instance, afin de pouvoir la supprimer. Pour cela, cliquez sur Edit puis sélectionnez votre ancienne instance et cliquez Remove, puis Save.
L’instance passe au statut draining, c’est-à-dire que le Target Group attend que les requêtes se terminent, avant de cesser de la considérer comme saine.

Attendez quelques minutes, et rendez-vous dans Instances pour terminer cette machine qui est désormais déconnectée de l’extérieur, en sélectionnant Action > Instance State > Terminate. En terminant l’instance, le groupe de mise à l’échelle réagit et relance une nouvelle machine pour la remplacer ; mais comme le groupe de lancement a changé, la nouvelle machine possédera la nouvelle image.
Nous avons désormais deux machines à jour ; nous pouvons réduire le groupe de mise à l’échelle si nous n’avons pas besoin des deux instances, et l’une des deux sera détruite. Pendant toute la procédure, nous avons toujours eu au moins une machine saine capable de recevoir du trafic réseau, permettant de continuer d’assurer le service tout en changeant le système de la machine.
Et soudain, le crash !
C’est vendredi soir et c’est l’heure des mauvaises nouvelles, c’est-à-dire approximativement 17 h 55. C’est l’heure où, en général, vos utilisateurs viennent vous voir parce qu’ils ont merdé, et qu’il faut les sortir du sable avant le week-end, parce que sinon une catastrophe nucléaire s’abattra sur la Terre et du coup ça sera pas ouf la forme le lundi suivant. Justement, voici FX, de la compta, qui s’approche à pas de velours de votre bureau. Il est un peu embêté, car c’est la clôture mensuelle et il a par erreur effacé plusieurs lignes de comptabilité de la base de données, notamment votre ligne de salaire.
FX est un fin stratège. Il a probablement réellement effacé par erreur des lignes, mais pour s’assurer que vous l’aidiez un vendredi soir à 17 h 55, il prend l’excuse du blocage de votre salaire. À vrai dire, vous n’avez jamais su si le prénom de FX était François-Xavier, Frédéric-Xander ou une autre combinaison de prénom en F ou en X, parce que tout le monde l’appelle FX ; mais vous y réfléchirez plus tard. Il est temps de le sortir du sable.
Restaurez des sauvegardes RDS
Vous aviez configuré les sauvegardes automatiques dans Amazon RDS ; il est l’heure de s’en servir. Restaurer des sauvegardes de base de données est très facile dans AWS. Il vous suffit de vous rendre dans le service RDS et de cliquer sur Snapshots. Vous allez voir la liste de vos sauvegardes :
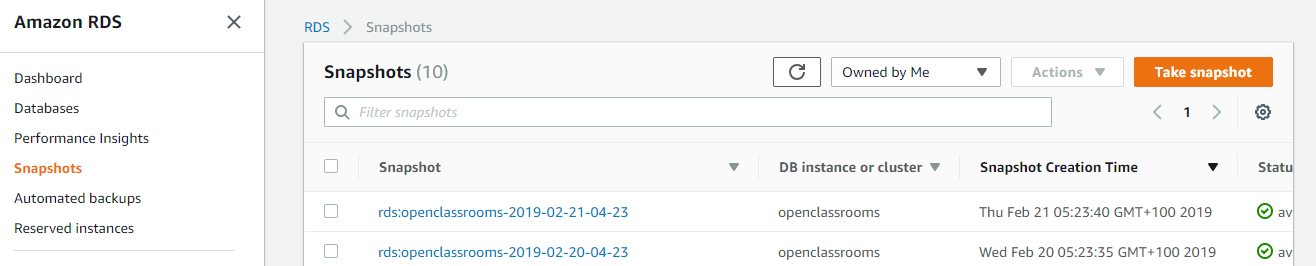
Cliquez sur le snapshot à réintégrer, et dans Action cliquez sur Restore Snapshot. Vous voyez le panneau de création de bases de données. Sélectionnez la taille de base de données comme t2.micro, laissez les autres paramètres par défaut et cliquez sur Restore DB Instance.
AWS lance à présent une base de données à partir du backup. À partir de là, vous avez deux possibilités :
Brancher votre application sur la nouvelle base de données.
Renommer la nouvelle base de données pour qu’elle remplace l’ancienne.
Dans notre cas, FX possède une application de gestion très lourde et compliquée à démarrer. Nous allons donc inverser les points d’entrée depuis la sauvegarde saine vers la base de données actuelle :
cliquez sur l’ancienne base de données, cliquez sur Modify et changez-en le nom (rajoutez le préfix “old”, par exemple) ;
choisissez Apply immediately, afin que les modifications soient immédiates, et non dans la fenêtre de maintenance ;
vous verrez un avertissement Potential unexpected downtime ; en effet, lors du renommage d’une base de données, le nouveau point de terminaison met environ 10 minutes à être créé. Ici, nous allons le faire quand même parce que dans tous les cas, la base de données a été cassée par FX et n’est plus utilisable ;
Cliquez sur Modify DB Instance.
La base de données passe à l’état “Renaming” :

Nous allons à présent prendre la base saine, et lui donner le nom de l’ancienne base :
cliquez sur la base de données saine et cliquez sur Modify ;
changez le nom, pour le nom de l’ancienne base de données ;
comme tout à l’heure, choisissez Apply Immediately ;
cliquez sur Modify DB Instance.
Après quelques minutes de coupure, la base de données saine est à présent à la place de l’ancienne, et FX peut se remettre à traiter votre paie. Vous avez bien mérité votre week-end.
En résumé
vous n’avez pas besoin de vous occuper des mises à jour système dans Amazon RDS : ce service est géré pour vous ;
pour mettre à jour vos machines dans un groupe de mise à l’échelle, vous devez tout d’abord créer une nouvelle image Amazon ou AMI ; ensuite, vous pourrez modifier la Launch Configuration et procéder au basculement de vos machines ;
pour restaurer des sauvegardes RDS, vous pouvez vous appuyer sur les Snapshot automatiques ou manuels créés précédemment ;
vous pouvez vous appuyer sur le changement de nom de base de données, afin d’opérer une bascule entre deux bases ;
procéder à la bascule de bases de données en les renommant entraînera une coupure de service.
C'est la fin de ce cours !
Dans ce cours, vous avez appris à construire un réseau dans le cloud, à déployer vos systèmes et à maintenir en condition votre infrastructure. Tout au long du cours, vous avez appris à automatiser la création de vos ressources dans le cloud.
Vous savez désormais :
identifier les enjeux et la philosophie des systèmes et réseaux dans le cloud ;
construire et automatiser un réseau cloud, notamment déployer un réseau VPC dans le cloud AWS, via l’interface web et avec CloudFormation ;
créer et automatiser un réseau de machines cloud ; en particulier, déployer un groupe de machines dans votre réseau et déployer un équilibreur de charge géré par AWS en frontal de vos machines ;
maintenir en condition opérationnelle son réseau cloud, notamment mettre à jour vos systèmes, consulter les métriques de vos machines via un dashboard, créer une alarme sur une métrique dans le cloud AWS et restaurer un backup de base de données.
