Qu’est-ce qu’un programme informatique ? Comment peut-on dire à un ordinateur de dire bonjour, de compter jusqu’à cent, de jongler, d’envoyer des fusées dans l’espace ?
Il suffit de lui demander… Et c’est le rôle du développeur !
En suivant ce cours, vous allez apprendre les bases d’un des langages de programmation les plus populaires : le Java !
En commençant par les bases, et en pratiquant avec des exercices, vous allez découvrir comment développer des programmes répondant à des besoins réels.
Nous irons ensuite ensemble dans l’univers de la programmation orientée objet, là où Java montre toute sa puissance.
Pour finir, nous verrons des éléments pour aller plus loin, mieux contrôler vos programmes, les bonnes pratiques…
Ne perdons pas plus de temps, allons découvrir les possibilités qu’offre la programmation en Java ! Rejoignez-moi dans le premier chapitre !
Gérez les variables de votre programme en Java
Tirez le maximum de ce cours

Bonjour et bienvenue dans ce cours !
Connaissez-vous le principe d’un cours en ligne sur OpenClassrooms ?
Ce cours suit une progression logique que l’on a séquencée en 3 parties. Chaque partie contient plusieurs chapitres, qu’il est préférable de suivre dans l’ordre.
Dans ces chapitres, vous retrouverez régulièrement :
des screencasts tutoriels. Ce sont des vidéos de démonstration qui permettent de suivre étape par étape la réalisation d’un point du cours directement sur l’ordinateur de l’expert-formateur ;
des exercices dans les sections "À vous de jouer". C’est l’occasion de mettre en pratique ; ils sont précieux pour accélérer votre apprentissage !
Et à la fin de chaque partie du cours, vous trouverez :
un quiz pour vous permettre de valider ce que vous avez appris
Mettez en pratique avec des exercices interactifs
Dans ce cours, vous mettrez ce que vous avez appris en pratique dans des exercices de code interactifs sur Replit. Pour accéder aux exercices, suivez les instructions ci-dessous :
créez un compte ou connectez-vous à votre compte Replit (c’est gratuit),
cliquez sur le lien suivant pour accéder aux exercices de ce cours : Apprenez à programmer en Java,
utilisez les liens dans les sections “À vous de jouer” pour retrouver l’exercice de chaque chapitre. Attention, vous repasserez par la page d'accueil et devrez choisir le bon exercice en fonction du cours et chapitre sur lequel vous êtes positionné.
Si vous voulez retrouvez ces exercices plus tard sur Replit, vous pouvez aller dans vos équipes (“Teams” dans le menu à gauche), puis cliquez sur le nom de ce cours sous la section “Education”.
Profitez de chaque occasion de pratiquer en faisant une pause dans le cours pour vous entraîner de votre côté, et reproduire pas à pas ce que vous voyez dans les vidéos de mise en pratique : c’est la clé de la réussite !
Êtes-vous prêt à découvrir le monde de Java ? Allez, c’est parti !
Rencontrez votre professeur

Raphaël Bertin a mis à jour le cours ! Il vous accompagnera tout au long de votre apprentissage au travers des vidéos de démonstration.
Raphaël est développeur Android et mentor OpenClassrooms. Sa passion : la création d'applications mobiles et d’interfaces utilisateurs soignées. Il est toujours en quête des meilleures pratiques de programmation.
Téléchargez la fiche résumé du cours
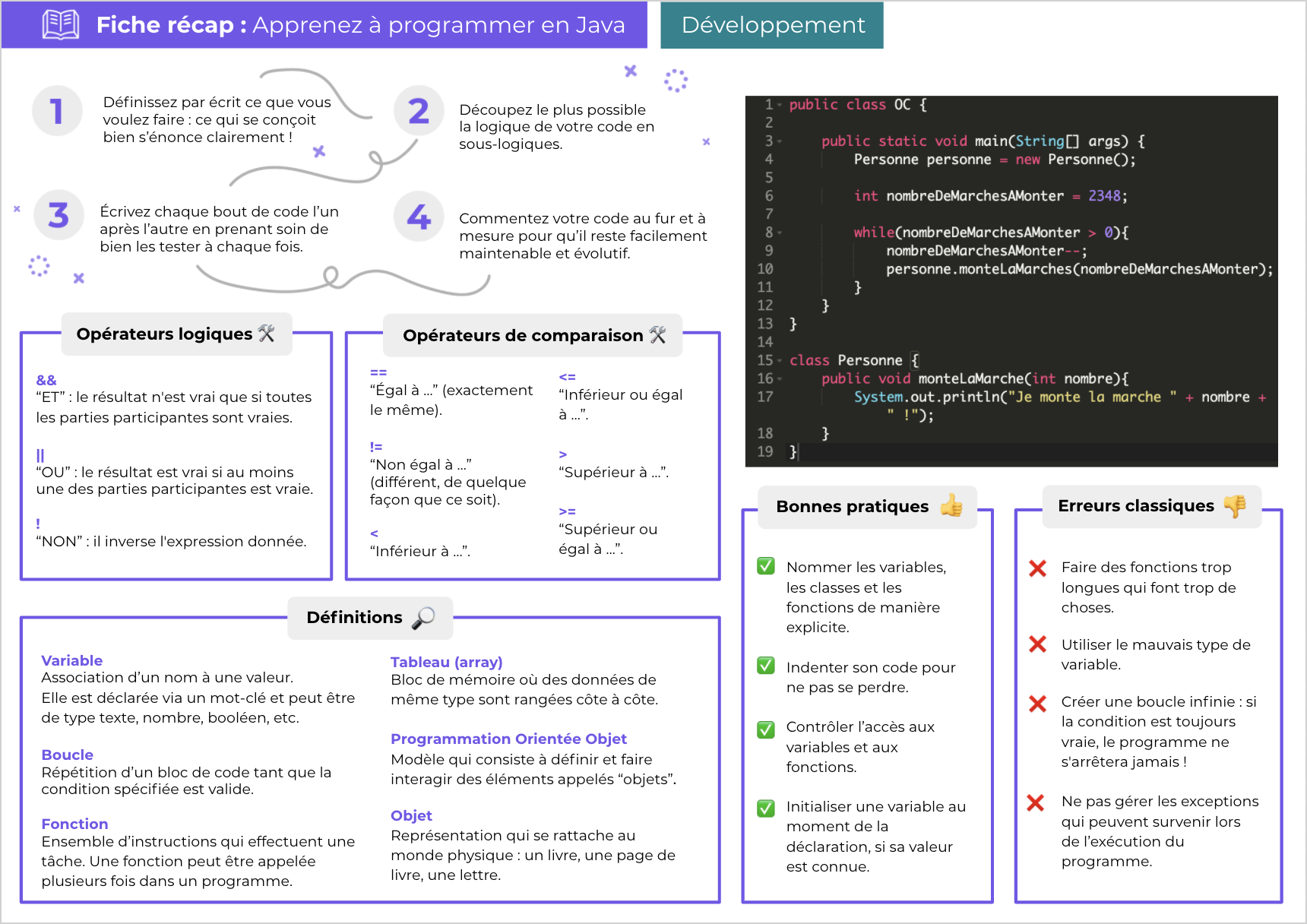
Déclarez des variables

Nous y voilà, vous allez enfin découvrir comment programmer une voiture autonome, à moins que vous ne vouliez concevoir un robot pour faire la cuisine ?
Bon, il va tout de même falloir commencer par les bases. Cela tombe bien, nous y sommes. Et nous allons tout de suite voir les notions indispensables ! Commençons par les variables !
Qu’est-ce qu’une variable ?
En quoi est-ce si important ?
Eh bien, concrètement, un programme est constamment en train de manipuler des variables, certaines qu’on lui donne, d’autres qu’il crée de lui-même.
On peut comparer une variable à une boîte dans laquelle est rangée une information. Cette boîte est stockée sur une étagère dans un entrepôt gigantesque. L'emplacement de chaque boîte de cet entrepôt est soigneusement enregistré, et géré par l’ordinateur.
Pour savoir à quoi sert chaque boîte, vous devez l’étiqueter. Avec la programmation, c'est la même chose : vous attribuez un nom à votre variable.
Nommez une variable
Voici quelques recommandations générales pour la création de noms :
Utilisez des noms descriptifs tout au long de votre code
Ça risque d'être un peu long ! Cependant, les noms descriptifs sont bien pratiques à long terme pour vous et pour votre équipe, car ils offrent une meilleure lisibilité et facilitent la compréhension du code pour les autres développeurs. Par exemple, si vous voulez stocker des cookies sans sucre, l'utilisation d'un nom descriptif comme cookiesSansSucre est bien plus précis que, disons, cookies ou cookiesSains.
Soyez complet
Évitez si possible d'abréger ou de raccourcir les mots, même si une version plus courte semble évidente. Par exemple, chiffreDAffairesAnnuel est préférable à chifAfAnn .
Suivez une convention d'appellation commune
L'une des conventions d'appellation les plus populaires est le Camel Case : une phrase composée de plusieurs mots sans espaces ni ponctuation. Le premier mot est écrit en minuscules et tous les autres mots commencent par une majuscule. Par exemple, monBudget.
Déclarez une variable
Pour utiliser une variable dans votre code, vous devez la créer, ou, en langage de développeur, la déclarer. On annonce qu’elle existe.
En Java, les variables qui contiennent des nombres entiers sont déclarées en utilisant un mot clé tel que int suivi du nom d'une variable. On dit que ce sont des ints.
Ensuite, il faut ranger une valeur dans cette variable. Par exemple :
int incomes = 500;int savings = 1000;Mais qu’est-ce que ce “;” ?
Ici, nous avons déclaré deux variables : incomes et savings . Ces variables stockent respectivement les valeurs de 500 et 1 000.
Modifiez la valeur d'une variable avec les opérateurs
Une variable peut varier, c'est-à-dire changer de valeur. Elle porte bien son nom, n'est-ce pas ?
Pour la faire varier, vous pouvez effectuer plusieurs opérations.
Reprenons les variables incomes et savings de l'exemple précédent. Vous pouvez :
ajouter de l'argent au montant épargné ;
soustraire de l'argent aux dépenses en cours ;
découvrir combien de temps il vous faudra pour atteindre 5 000 euros si vous épargnez 500 euros par mois ;
découvrir le montant de vos dépenses si vous continuez à ajouter 30 euros par jour pendant une semaine ;
découvrir le montant de vos dépenses si vous dépensez 10 euros par jour pendant une semaine.
Des problèmes du monde réel avec des solutions de programmation !
Eh oui, chaque opération fonctionne grâce à des opérateurs arithmétiques :
+ addition ;
- soustraction ;
* multiplication ;
/ division.
Tout comme en mathématiques, vous pouvez utiliser des parenthèses pour décider de ce qui se passe, et quand.
Voyons comment vous pouvez atteindre votre objectif en Java :
Regardez ce joli bloc de code :
public class ManipulationVariables {
public static void main(String[] args) {
int epargne = 500;
int revenus = 2000;
//Ajoutez 100 à votre épargne (Yeah!)
epargne = epargne + 100;
//Enlevez 50 à votre indemnité (Snif)
revenus = revenus - 50;
//Faites une mise à jour sur votre délai d'épargne
int nombreDeJoursEpargne = (5000 - revenus) / 500;
//Mettez à jour à nouveau votre indemnité (encore)
revenus = revenus + (30 - 10) * 7;
}
}Vous remarquerez que :
toutes les lignes ne se ressemblent pas ;
les lignes commencent par // : ce sont des commentaires qui permettent aux autres personnes de mieux comprendre le code. Le programme sait qu’il ne doit pas prendre en compte cette conversation entre développeurs !
Ici, chaque affectation assigne une valeur à une variable.
Est-ce qu'on peut résumer ?
Oui ! Pour affecter une valeur à une variable, vous écrivez une affectation. Cette affectation se compose du nom de la variable, suivie de l'opérateur d'affectation, et enfin de l'expression qui produit une valeur correspondant au type de la variable.
Écrivez un code plus court avec des opérateurs d'affectation raccourcis
Chaque affectation attribue une valeur à une variable. Vous pouvez directement assigner une valeur à droite de l'opérateur d'affectation. Voici un exemple :
//remplacez la variable épargne par le nouveau montant
epargne = 10000;D'ailleurs, lorsque vous avez besoin de changer la valeur d'une variable avec des opérateurs de base et de l'affecter à cette variable, vous pouvez utiliser une version raccourcie ! Voici un exemple. Au lieu d'utiliser epargne + 100 et l'opérateur d'affectation = , vous pouvez utiliser un opérateur d'affectation joint à l'opérateur arithmétique += :
// Version d'affectation normale
epargne = epargne + 100;// Version raccourcie d'affectation
epargne += 100;Les autres variantes courtes sont :
+=addition ;-=soustraction ;*=multiplication ;/=division.
Manipulez d’autres données que des nombres
Dans l'exemple que nous avons utilisé, toutes les variables stockent des montants d'argent, qui sont des nombres entiers.
Quels autres types de valeurs pouvons-nous affecter aux variables ?
Vous avez vu qu’une variable était définie par un nom et une valeur. Pour pouvoir stocker différents contenus dans les boîtes (ou bocaux), vous devez définir le type de la variable.
Supposons que vous soyez en train de travailler sur une application d'écriture, et que vous ayez besoin d'analyser du texte et de calculer ce qui suit :
le nombre de voyelles présentes dans le texte ;
le pourcentage de voyelles.
Vous pouvez décomposer le processus comme suit :
Demandez du texte à l'utilisateur.
Parcourez le texte fourni par l'utilisateur caractère par caractère.
Augmentez votre total à chaque fois que vous trouvez une voyelle.
Divisez le nombre final de voyelles par le nombre total de caractères de la chaîne pour obtenir le pourcentage.
Multipliez ce résultat par 100 pour le pourcentage final.
De combien de variables auriez-vous besoin pour y parvenir ? Pensez au nombre d'informations individuelles que vous devez stocker :
La séquence initiale de caractères que vous demandez à l'utilisateur (une chaîne de caractères).
Le nombre de voyelles présentes dans la chaîne.
Le pourcentage de voyelles.
On dirait que vous avez besoin de trois variables ! Pour définir chacune d'entre elles, vous avez besoin des composants suivants :
Un type, qui définit le type de variable que vous avez : chaîne (texte), entier (nombre entier), ou décimal (virgule flottante).
Une valeur initiale, qui vous donnera un point de départ.
Vous en saurez bientôt plus sur les types de variables !
String= texte ;int= nombre entier ;double= nombre en virgule flottante.
En Java, vous pouvez déclarer vos trois variables comme ceci :
String text = "A wonderful string that consists of multiple characters";int numberOfVowels = 0;double percentageOfVowels = 0.0;Découvrez des variables qui ne changent jamais
Jusqu'à présent, la plupart des valeurs changeaient en fonction des circonstances (ajouter de l'argent aux économies, augmenter le nombre de voyelles). Certaines valeurs, cependant, n'ont pas besoin d'être modifiées. Elles restent exactement telles qu'elles ont été définies au départ.
L'utilisation de constantes est utile pour deux raisons :
Elles permettent aux programmes d'être plus rapides. L'ordinateur sait combien d'espace une constante prend. Cela signifie que lorsqu'il effectue des opérations, il n'a pas besoin de vérifier les valeurs alternatives.
S’assurer que certaines valeurs ne changent pas, que ce soit intentionnellement ou par accident. Par exemple, vous ne voudriez pas modifier les jours de la semaine ou le nombre de jours dans une année.
Déclarons quelques constantes et voyons comment elles fonctionnent.
Pour déclarer une constante en Java, vous devez utiliser le mot clé final :
final int NUMBEROFWEEKDAYS = 7;final String MYFAVOURITEFOOD = "Icecream";int numberOfPets = 1;String currentSeason = "Winter";Il y a des variables et des constantes dans l'exemple ci-dessus. Si vous essayez de modifier les valeurs de toutes ces variables, seules les variables passeront, et les constantes généreront des erreurs :
NUMBEROFWEEKDAYS = UMBEROFWEEKDAYS + 1; // ErrorMYFAVOURITEFOOD = "Cake"; // ErrornumberOfPets = 3; // OkcurrentSeason = "Summer"; // OkSi vous regardez le fonctionnement des variables dans différents langages de programmation, vous allez probablement remarquer quelques différences. Il est important de les connaître lorsque vous commencez à programmer dans un environnement spécifique. Cependant, vous observerez aussi beaucoup de similitudes. Bien que les variables puissent sembler différentes d'un langage à l'autre, les concepts restent les mêmes. Ne l'oubliez pas si vous décidez de commencer à programmer dans un autre langage.
À vous de jouer !

Prêt à coder ? Pour accéder à l’exercice, suivez ce lien.
En résumé
Une déclaration de variable est composée de trois éléments : type, nom, et valeur.
Les valeurs des variables peuvent être modifiées.
Les variables à valeurs constantes sont appelées constantes.
Le nom des variables doit respecter les conventions de dénomination courantes.
Dans le chapitre suivant, nous allons nous intéresser aux types de variables.
Choisissez le bon type de variable
Spécifiez le type de variable
La seule façon de déclarer une variable en Java est de spécifier directement son type : on parle de typage fort.
Regardons la déclaration suivante de la variable count :
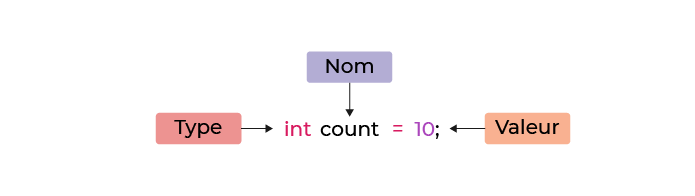
Par exemple, si vous voulez compter des mots dans une phrase, mais que vous ne savez pas encore de quelle phrase il s'agit, indiquez le type, et déclarez la variable pour une utilisation future.
int nombreDeMotsDansLaPhrase;Si je ne peux pas utiliser une variable sans valeur, pourquoi donc j'ai besoin de spécifier le type ? Pourquoi pas uniquement la valeur ?
Pendant l'exécution d'un programme, votre processeur (unité centrale de traitement) a besoin de savoir combien d'espace il va devoir réserver à votre variable. Utiliser un type pour déclarer une variable permet à votre processeur de lui allouer un espace mémoire adapté.
Parmi les types de données, il existe les types primitifs. Ce sont des types qui existent par eux-mêmes, comme des atomes. Nous en avons déjà vu certains : int et double.
Les types les plus simples servent de base à toutes les opérations informatiques.
Parmi les types primitifs, vous serez souvent amené à utiliser les types numériques et les chaînes. Parlons-en un peu !
Découvrez les types numériques
Les types numériques sont :
les nombres entiers, comme les nombres que vous utilisez pour compter (1, 2, 3) ;
les nombres décimaux, que vous pouvez utiliser pour stocker les valeurs monétaires (2,50 ou 5,99, par exemple).
Les nombres entiers
Commençons par un type que vous connaissez déjà bien : les entiers ! Les entiers sont déclarés comme n'importe quelle autre variable, avec un type, puis un nom, puis, si vous l'avez, une valeur :
int count = 10;Vous reconnaissez le mot clé int du dernier chapitre ?
C'est parce que vous déclarez des entiers avec le mot clé type int . Votre variable count a un type entier. Et sa valeur est de 10, qui est... un nombre entier !
Les nombres décimaux
Pour les nombres décimaux, Java utilise deux types différents :
float;double.
Ces deux types ont le même but. La différence est que double est deux fois plus précis que float , ce qui signifie qu'il propose plus de décimales après la virgule.
Si vous avez besoin de stocker quelque chose de grand, comme un numéro à 12 chiffres : 1876.79797657 , vous devrez utiliser double . En effet, float ne pourra stocker que la moitié de ce chiffre... Le reste serait tronqué et perdu à tout jamais !
Ces types sont déclarés et initialisés de la façon suivante :
float length = 1876.79;double width = 1876.79797657;Mais que se passe-t-il si je fournis des valeurs supérieures ?
Par exemple :
float a = 1876.79797657765609870978709780987;double b = 1876.79797657765609870978709780987;Eh bien, elles vont perdre toutes les deux un peu de précision, mais pas au même degré :
// a -> 1876.79// b -> 1876.797976Avec des valeurs plus petites, cela ne fait aucune différence :
float length = 10.0;double width = 10.0;Dans l'exemple ci-dessus, les deux variables contiennent de petites valeurs. Sur la deuxième ligne, nous utilisons simplement double au lieu de float . Comme cela ne fait aucune différence fonctionnelle, je vous encourage à utiliser la plus petite dans cet exemple, puisque l'utilisation d'une plus grande boîte pour stocker les petites valeurs gaspille de la mémoire !
Mélangez des types numériques
Dans vos programmes, vous pouvez être amené à faire des opérations mathématiques. Cependant, les variables utilisées ne seront pas forcément de même type (tant qu'elles restent des valeurs numériques). C'est pourquoi il est important de garder à l'esprit la façon dont les types se mélangent, et les conséquences que cela peut avoir. Par exemple, si vous divisez deux nombres : 5/2 , on pourrait s’attendre logiquement à un résultat de 2,5 . Mais pour l'ordinateur, ce n'est pas si évident que ça, et vous pourriez obtenir 2 de façon assez inattendue !
Voyons ça en vidéo :
Découvrez les booléens
En langage Java, pour valider une condition, vous utilisez un type de données spécifique appelé boolean . Une variable de type booléen ne peut contenir que deux valeurs : true ou false. Un boolean est le type de données le plus simple.
Voici comment déclarer un boolean en Java :
boolean isCodingInJava = false;Comme pour les types numériques que vous venez de voir, nous pouvons changer la valeur de notre variable :
isCodingInJava = true; // Nous changeons la valeur à trueLorsque vous utilisez des booléens, il est très probable que vous ayez besoin de simplement inverser sa valeur, peu importe sa valeur actuelle. En Java, vous pouvez utiliser le NON logique :
boolean isCodingInJava = true;isCodingInJava = !isCodingInJava; // Inversion de la valeur, donc falseisCodingInJava = !isCodingInJava; // Inversion de la valeur, donc trueUtilisez le type String pour les chaînes de caractères
Passons maintenant à un type plus complexe : String .
En vérité, le String est un objet ! N’ayez pas peur, c’est le sujet de la deuxième partie de ce cours. Vous avez pour l’instant tout ce qu’il vous faut pour comprendre la suite.
Voici comment déclarer une variable String dans Java :
String city = "New York";String movie = "Best ever";String pet;String emptyString = "";Vous pouvez fusionner une ou plusieurs d'entre elles. Rassemblons quelques strings :
String firstFavoriteCity = "New York";
String secondFavoriteCity = "Buenos Aires";
String favorites = firstFavoriteCity + secondFavoriteCity; // -> "New YorkBuenos Aires"Mais, il n'y a pas d'espace entre les deux. C'est bizarre, non ?
Rendons ce code plus lisible en concaténant, c'est-à-dire en mettant bout à bout des chaînes de caractères et des variables :
String firstFavoriteCity = "New York"
String secondFavoriteCity = "Buenos Aires"
String favorites = "My favorite cities are " +firstFavoriteCity+ " and "+secondFavoriteCity; // -> "My favorite cities are New York and Buenos Aires"C'est beaucoup mieux maintenant ! Vous pouvez également concaténer d'autres types de données avec des chaînes de caractères, telles que des nombres.
Ah oui ? Mais comment je procède ?
String favoriteCity = "Buenos Aires";
int numberOfTrips = 5;
String story = "I've traveled to " +favoriteCity+ " " +numberOfTrips+ " times!"; // -> "I've traveled to Buenos Aires 5 times!"Juste avant, nous avons utilisé l'opérateur + pour ajouter deux nombres. Ici, avec des chaînes de caractères, l'opérateur + peut être utilisé pour concaténer des chaînes et des nombres entiers. La concaténation fait référence à l'assemblage de chaînes de caractères ou de nombres, et de chaînes de caractères.
En résumé
Dans ce chapitre, vous avez vu les particularités de quelques types de données simples :
nombre entiers (mot-clé
int) ;nombres décimaux (mots clés
floatetdouble) ;booléens (mot-clé
boolean).
Vous avez abordé un type complexe :
chaînes de caractères (mot clé
String).
Vous avez aussi appris à manipuler ces types :
vous pouvez effectuer des opérations numériques sur des nombres du même type ;
pour utiliser ensemble des nombres de types différents dans les opérations, utilisez
castpour qu'ils se comportent comme le type nécessaire ;les Strings peuvent être mis bout à bout. Cela s'appelle la concaténation.
Dans le chapitre suivant, nous aborderons la fonction main ; c'est le point d'entrée de votre programme.
Écrivez une fonction
Dites bonjour au monde entier
Pour aborder ce chapitre, je dois vous présenter la notion de classe.
Une fonction peut être considérée comme un bloc de code avec un nom, qui exécute un service. Quand il s'agit d'une fonction main , le service effectué est en fait le programme lui-même ! Plutôt cool, non ? En d’autres termes, lorsque vous lancez votre programme, c’est la fonction main qui se lance. Elle est aussi appelée le point d’entrée.
Lorsqu'une fonction est située à l'intérieur d'une classe, elle s'appelle une méthode. Puisque tout le code est situé à l'intérieur de classes, vous pouvez utiliser les deux termes (fonctions et méthodes) de manière interchangeable.
Maintenant que vous connaissez la fonction main et que vous savez comment lancer un programme, il est temps d'écrire votre premier programme ! Traditionnellement, lorsque l'on apprend un langage pour écrire son premier programme, on cherche à afficher la chaîne de caractères Hello World! (Bonjour tout le monde, en français).
Si vous vous en souvenez – mais ce n’est pas si loin ! – je vous ai accueilli dans ce cours avec ce programme.
Regardons à nouveau le code Java qui rend honneur à cette tradition :
package hello;
/** Ceci est une implémentation du message traditionnel "Hello world!"
* @author L'équipe Education d'OpenClassrooms
*/
public class HelloWorld {
/** Le programme commence ici */
public static void main(String[] args) {
System.out.println("Hello World!");
}
}Décryptons ce code :
La première instruction,
package hello;, est une déclaration de package. Ne tenez pas compte de cette ligne pour le moment.La déclaration
public class HelloWorlddéfinit le nom de la classe comme étant HelloWorld. En Java, l'ensemble du code doit se trouver à l'intérieur d'une classe.public static void main(String[] args). C'est le morceau de code que l'interpréteur Java recherche lorsque vous démarrez un programme.Une instruction avec une classe utilitaire nommée
System. Ce genre de classe n'a pas besoin d'être instancié pour être utilisé.
À l'intérieur de la méthode principale, vous trouverez l'instruction
System.out.println("Hello World !");qui affiche le message attendu.
Mais, à quoi servent les lignes dans les caractères /** et */ ?
Ce sont des commentaires de documentation, un code qui n’est pas utilisé lors de l'exécution du programme. C’est la version paragraphe de //. Cela vous permet de laisser des messages informatifs pour expliquer votre code (pour votre vous futur ou d’autres développeurs !)
En résumé, le code de démarrage d'un programme Java est contenu dans une fonction main (ou méthode). Cette fonction main est elle-même contenue dans une classe. Enfin, cette classe elle-même appartient à un package.
Maintenant que vous savez écrire du code, il est temps de l'exécuter !
Exécutez le programme à partir du terminal
En Java, il y a une correspondance directe entre :
les packages et les dossiers ;
les classes et les fichiers.
En effet, pour exécuter le programme sur votre ordinateur, vous devrez créer des dossiers qui correspondent à vos packages, et des fichiers qui correspondent à vos classes ! Pour le moment, nous avons écrit notre code Hello World! dans la méthode principale d'une classe HelloWorld. Cette méthode principale se trouve dans un package hello . Voyons maintenant ce que vous devez faire pour faire correspondre cela avec quelques fichiers et dossiers.
Voici les étapes principales :
Tout d'abord, vous devez créer un dossier dans lequel vous allez mettre tout votre code. C'est ce qu'on appelle généralement le dossier root (racine).
À l'intérieur de ce dossier racine, vous pouvez créer un dossier "hello" correspondant au nom de votre package.
Ensuite, créez un fichier HelloWorld.java dans le dossier Hello, correspondant au nom de votre classe.
Vous voyez comment tout cela s'organise ? Package vers dossier, classe vers fichier. ✅
Une fois le fichier HelloWorld.java créé, vous pouvez saisir votre code Java. Utilisons le code de la section précédente :
package hello;
/** Ceci est une implémentation du message traditionnel "Hello world!"
* @author L'équipe Education d'OpenClassrooms
*/
public class HelloWorld {
/** Le programme commence ici */
public static void main(String[] args) {
System.out.println("Hello World!");
}
}Lorsque tout le code est à l'intérieur du fichier, vous devez convertir ce code Java en code exécutable par une machine, que l'ordinateur peut comprendre.
Exécutable ? Mais qu'est-ce que ça veut dire ?
Quel que soit le langage de programmation que vous utilisez pour écrire votre code, il doit être traduit en un ensemble d'instructions qu'un ordinateur peut exécuter. C'est ce qu'on appelle le code machine.
Mais alors, pourquoi ne pas écrire des programmes directement en code machine ?
Même si le code machine est parfaitement lisible pour les ordinateurs, il serait très difficile à utiliser pour les êtres humains.
Pensez votre code comme une recette de cuisine. Vous pouvez utiliser un langage de tous les jours pour décrire les ingrédients et les étapes à suivre, ou vous pouvez utiliser leur composition chimique et un vocabulaire spécialisé pour décrire les différentes étapes. Cette dernière option pourrait être comprise par certains, mais la plupart d'entre nous ne pourraient pas cuisiner avec de telles instructions. Et même pour ceux qui comprennent, le processus serait très long !
Le langage dans lequel le code Java doit être transformé est appelé Bytecode. Pour transformer le code Java en Bytecode, il est nécessaire d'utiliser le compilateur javac.
Et c'est à ce moment-là que les dossiers commencent à être utiles ! En utilisant la console/le terminal, naviguez jusqu'au dossier racine root de votre programme, et exécutez la commande suivante :
$ javac hello∖HelloWorld.javaLa commande javac est en fait elle-même un programme. Si vous êtes sous Windows, elle sera nommée javac.exe.
Cette commande crée un fichier HelloWorld.class dans le dossier Hello. Ce fichier est un fichier binaire (vous ne pouvez pas l'ouvrir dans un éditeur de texte). Vous pouvez maintenant exécuter le programme avec la commande java (ou java.exe sous Windows) :
$ Java hello.HelloWorld Hello World!Concrètement, lorsque vous développez, vous utilisez un environnement de développement (IDE) pour vous simplifier la vie. L'exécution de votre programme en cours de conception peut très bien se faire avec cet outil magique. Il se chargera de vous dire où sont les bugs, d'interpréter et d'exécuter tout seul le programme.
Dans le reste de ce chapitre, nous allons nous concentrer sur la façon d'organiser votre code afin que votre fonction main reste aussi petite que possible.
Organisez votre code de manière optimale
Le but de votre fonction main est de démarrer votre programme.
Dans les bonnes pratiques, il est d’usage que la méthode main soit la plus courte possible, en appelant uniquement les méthodes nécessaires.
Comme nous l'avons dit au début de ce chapitre, il existe deux types de classes que vous pouvez écrire et utiliser.
Utilisez des classes en tant que modèles
Vous pouvez définir des types complexes qui regroupent différents attributs représentant un concept nommé. Ce sont des classes de modèles. Vous les écrivez souvent pour modéliser le domaine de votre application : ce pour quoi vous écrivez votre programme.
Exemple : la classe String que vous utilisez pour stocker et manipuler les chaînes de caractères dans votre programme. Cette classe est disponible dans le package java.lang , qui est disponible depuis n'importe quelle partie de votre code.
Comment se fait-il que String soit une classe et non un type primitif tel que int ou double ?
String est une classe non seulement parce que son nom commence par une lettre majuscule, mais aussi parce qu'il définit un état et un comportement :
Son état est la chaîne de caractères que vous stockez. La valeur réelle est définie pour chaque objet lorsque vous l'instanciez.
Son comportement est l'ensemble des méthodes que la classe
Stringdéfinit, et qui vous permettent d'opérer sur la chaîne que vous stockez.
Voyons cela en action :
Comment savoir quels comportements sont réellement disponibles ?
Vous vous souvenez de la Javadoc ? Chaque fois que vous écrivez une classe, vous êtes censé la documenter dans les marqueurs /** et */ . Cela permet de générer automatiquement une page de documentation HTML. Les développeurs Java ont fait cette page pour vous, et l'ont rendue disponible sur le site officiel. Cette documentation va vous permettre de trouver les fonctionnalités disponibles rapidement ! Pratique, non ?
Jetez un coup d'œil à la Page Javadoc sur les String . Pouvez-vous trouver les méthodes toUpperCase() et contains() ?
Entraînez-vous à trouver des méthodes dans la page Javadoc, et faites en sorte que l'utilisation du site web Javadoc devienne un réflexe pour vous ! Cela vous permettra de gagner du temps par la suite.
Voyons maintenant le deuxième type de classes que vous allez définir et utiliser : les classes utilitaires.
Nettoyez votre fonction main
Dans certains cas, vous n'aurez même pas accès à la fonction main ! Cela peut se produire si vous utilisez des frameworks, comme le kit de développement d'Android pour le développement mobile, ou le Spring Framework pour le développement web. Les frameworks sont des outils qui fournissent aux développeurs les fonctionnalités de base sur lesquelles ils peuvent s'appuyer, généralement sous la forme d'un ensemble de classes.
Penchons-nous maintenant sur votre fonction main et prenons-en le contrôle. Nous allons la rendre aussi propre et nette que possible. Voici une implémentation « propre et nette » de notre programme HelloWorld :
package cleanHello;
/** Ceci est une implémentation du message traditionnel "Hello world!"
* @author L'équipe Education d'OpenClassrooms
*/
public class CleanWorld {
/** Le programme commence ici */
public static void main(String[] args) {
sayHelloTo("world");
}
/** affiche le message "hello" au destinataire fourni
*
* @param recipient
*/
private static void sayHelloTo(String recipient) {
System.out.println("Hello " + recipient);
}
}Comme vous pouvez le voir, la classe CleanWorld définit deux méthodes :
mainest le point d’entrée du programme. Son seul job, c'est de transmettre le travail à la méthode sayHello avec l'argument dont elle a besoin. Dans notre cas, c'est le destinataire prédéfini de notre hello : the world !La méthode
sayHelloimprime la chaîne « Hello » et ajoute la valeur fournie à la variable destinatairerecipientlorsqu'elle est appelée par la méthodemain.
En termes de fonctionnalité, rien n'a changé. Cependant, vous pouvez maintenant ajouter plus de logique au message que vous allez afficher, en changeant la méthode sayHello et en personnalisant le nom du destinataire.
Nous allons ajouter des fonctionnalités dans les chapitres suivants ! Pour cela, vous devez ajouter plus de logique à votre boîte à outils de programmation Java. Le chapitre suivant traite de ce premier outil : les conditions !
En résumé
Les programmes Java sont structurés en packages et en classes.
Aucun code n'est écrit en dehors d'une classe, ce qui signifie que toutes les fonctions sont des méthodes en Java.
Les packages sont mappés dans des dossiers et les classes dans des fichiers.
La commande
javacconvertit le code Java en Bytecode.La commande
javaexécute le programme actuel en exécutant la fonctionmaindans la classe fournie.Il existe deux types de classes :
Les classes modèles qui sont utilisées comme modèles pour l'instanciation des objets.
Les classes utilitaires qui contiennent des méthodes statiques qui peuvent être appelées directement sur la classe.
Vous pouvez accompagner vos classes et méthodes avec des commentaires de documentation, écrits entre
/**et*/, pour générer une page HTML avec toute la documentation de la classe, appelée un Javadoc. La méthodemainpeut vous être masquée si vous utilisez un framework.Les principes du code propre exigent qu'aucune logique ne soit écrite à l'intérieur de la méthode
main. Tout le travail doit être délégué à des fonctions bien nommées.
Dans le prochain chapitre, nous aborderons la portée des variables en Java. Certaines peuvent être localisées dans une méthode ou une section de code, alors que d'autres ont une portée plus globale.
Saisissez la portée des variables

Dans ce chapitre, nous allons nous rendre compte que chaque variable déclarée en Java a une portée, c'est-à-dire un champ d’accessibilité dans lequel elle peut être utilisée.
Comprenez le principe de portée d'une variable
Chaque variable n'est disponible (et accessible) que dans le contexte dans lequel elle a été déclarée. Pour déterminer le contexte, reportez-vous aux marques d'ouverture et de fermeture les plus proches qui entourent la déclaration. La plupart des langages de programmation utilisent des accolades ouvrantes et fermantes ( { } ) pour marquer le début et la fin d'un bloc de code.
Jetez un œil à cet exemple :

Il n'est pas nécessaire de comprendre chaque morceau de code ici. Il vous suffit de vous concentrer sur les accolades ouvrante et fermante. Quand nous parlons de la disponibilité d'une variable dans un contexte, nous faisons référence à la portée (scope). Ici, vous pouvez voir que la variable root a été déclarée entre les deux accolades (ouvrante et fermante) entourées en violet. La portée de cette variable est tout ce qui se trouve entre ces deux accolades. Autrement dit, la classe MyScopeExample connaît root, mais ce qui est à l'extérieur ignore son existence.
La portée d'une variable peut être locale ou globale, en fonction de l'endroit où la variable est déclarée. Une variable globale peut être disponible pour toutes les classes et méthodes d'un programme, alors qu'une variable locale ne peut être disponible que dans la méthode dans laquelle elle est déclarée :
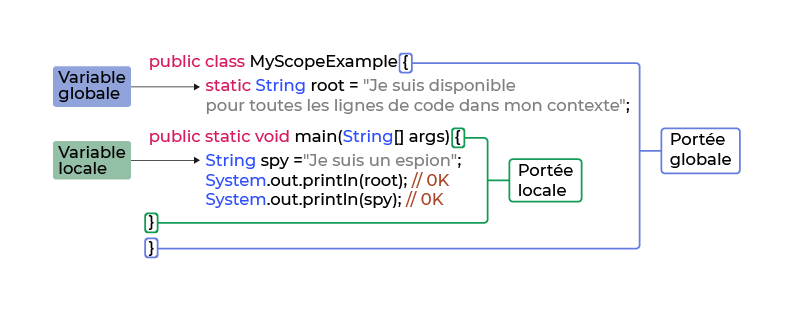
Ici, nous avons un peu élargi le code et étendu notre premier bloc de code pour en inclure un autre ! Si vous tracez les lignes violettes, vous pouvez voir que les parenthèses du premier bloc englobent tout le code du second. Ensuite, vous pouvez voir qu'une nouvelle variable, spy , a été déclarée dans le cadre local vert.
Puisque la variable root a été déclarée dans la portée globale, cela signifie qu'elle est accessible à tout ce qui est entre parenthèses violettes, y compris tout ce qui est déclaré dans la portée locale. Dans le deuxième bloc de code, vous pouvez voir une ligne juste en dessous de la déclaration de la variable « spy » qui utilise root . Cela est autorisé !
Cependant, tout ce qui est dans la portée locale n'est pas disponible pour la portée globale, ni aucun autre bloc de code local. Prenons un autre exemple :
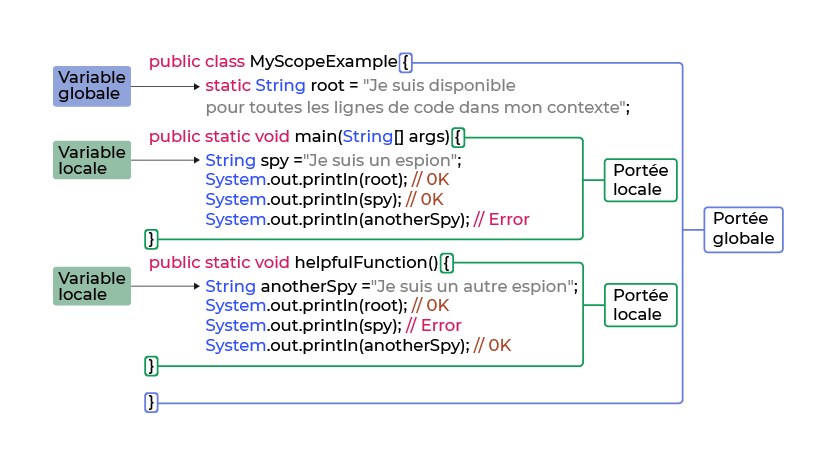
Ici nous avons ajouté un autre bloc de code, qui a sa propre portée locale et sa propre variable, anotherSpy . Maintenant, regardez la dernière ligne de notre bloc variable « spy » :
System.out.println(anotherSpy); // ErreurOn dirait qu'il y a une erreur ! C'est parce qu'elle essaie d'utiliser la variable anotherSpy . Mais ce n'est pas possible car anotherSpy n'est ni dans la portée globale ni dans la même portée locale. Cela signifie que ce bloc de code ne peut pas y accéder. anotherSpy est disponible uniquement dans le bloc de code dans lequel il a été déclaré.
L'inverse est également vrai. Vous voyez que la dernière ligne de notre dernier bloc de code présente elle aussi une erreur :
System.out.println(spy); // ErreurIci, le code essaie d'utiliser la variable spy d'un autre bloc de code. Mais ce n'est pas possible car spy n'est pas dans la même portée que le bloc de code qui essaie de l'utiliser.
Déterminez la portée de la variable dans les classes
Lorsque vous déclarez une classe, les mêmes règles générales concernant la portée s'appliquent : chaque variable n'est accessible qu'au sein de son bloc de déclaration. Expérimentons avec une classe Unicorn :
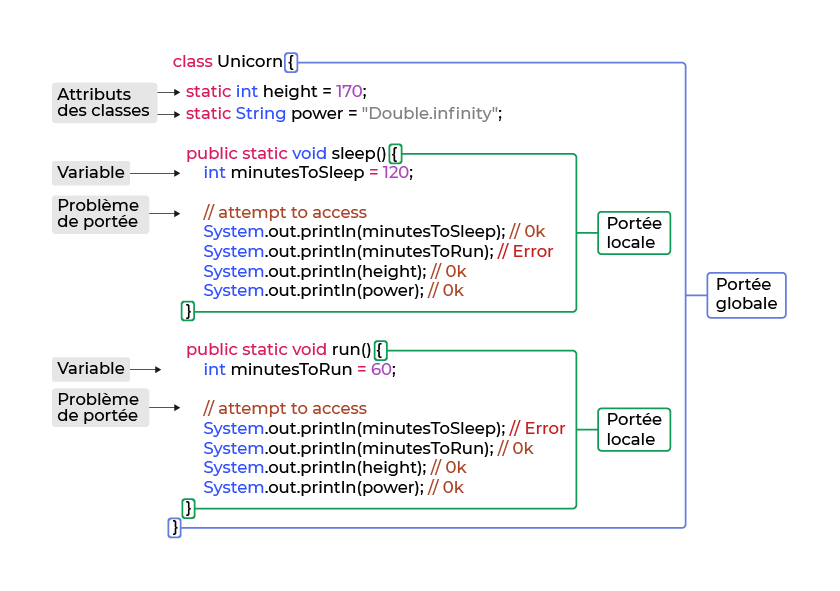
Tout comme dans notre premier exemple, il y a des variables de classe globale ainsi que des variables locales. Revoyons cela plus en détail :
les variables
heightetpowersont des champs de la classe et sont accessibles partout dans la classe ;la variable
minutesToSleepn'est accessible que dans le cadre local du bloc de code dans lequel elle est déclarée ;la variable
minutesToRunn'est accessible que dans le cadre local du bloc de code dans lequel elle est déclarée.
La portée d'une variable limite (par définition) son accessibilité. Cependant, les champs de classe sont accessibles en dehors de la classe et peuvent être utilisés par tout autre bloc de code.
Dans notre exemple, ce sont les champs height et power . Si nous déclarons une variable Unicorn (licorne), nous pouvons lire ou modifier ces valeurs :
Unicorn unicorn = new Unicorn();
System.out.println("I know it's height: "+unicorn.height);
// et peut changer son pouvoir !
unicorn.power = 0; // pas drôle!Le fait d'être capable de jouer avec les variables de classe peut avoir des conséquences graves. La bonne nouvelle, c'est que vous pouvez le contrôler ! Avant de vérifier comment, assurez-vous de vous exercer à déterminer la portée des variables.
Implémentez un contrôle d'accès
Nous allons utiliser cette idée de contrôle d'accès en implémentant un accès restreint à une variable, une classe, un module ou un fichier. Vous savez déjà ce que sont une classe et un fichier !
D'ailleurs, un fichier de code est aussi appelé un fichier source.
Chaque environnement de développement fournit un certain nombre de frameworks. Le fait est que la mise en œuvre de ces frameworks dépasse de loin ce que les développeurs qui les utilisent peuvent voir et utiliser. Cela se fait en limitant l'accès aux détails de l'implémentation, également connue sous le nom d'implémentation du contrôle d'accès.
Désignez un niveau de contrôle
En Java, vous devez utiliser un des mots clés suivants pour désigner un niveau de contrôle :
public : visible pour tous et par conséquent le moins restrictif ;
protected (protégé) : visible pour le package et l'ensemble de ses sous-classes ;
package-protected (protégé par paquet) : généralement visible uniquement par le package dans lequel il se trouve (paramètres par défaut). Ne pas mettre de mot clé déclenche ce niveau de contrôle ;
private (privé) : accessible uniquement dans le contexte dans lequel les variables sont définies (à l'intérieur de la classe dans laquelle il est situé).
La mise en place de ces restrictions distinctes facilite grandement le développement. Vous n'avez pas à vous soucier de la visibilité non désirée de votre implémentation, ni, plus encore, des modifications non désirées.
En plus de la sécurité, la spécification de niveaux de contrôle pour les membres du groupe permet une meilleure lisibilité. Si un développeur prépare un fichier source, les éléments pouvant être utilisés en externe seront ainsi toujours visibles.
Déterminez une hiérarchie de contrôle
Un élément peut avoir le même niveau de contrôle, ou un niveau de contrôle plus restrictif que son élément contenant :
public class PublicClass {
public boolean publicProperty = true;
int internalProperty = 0; //par défaut pour package-private
private String fileprivateProperty = "Hello!"
private static void privateMethod() {
}
}Dans l'exemple ci-dessus, la classe est déclarée public . Puisque la classe est l'élément contenant, cela signifie que tous les éléments de cette classe peuvent être du même niveau d'exposition d'un niveau inférieur. Dans ce cas, cela comprend tous les niveaux.
Si vous déclarez une classe comme private , ses éléments ne peuvent être que package-private ou private :
class PrivateClass {
int internalProperty = 0; // assigne automatiquement package-private par défaut
protected defaultProperty = true; // assigne automatiquement package-private
public boolean publicProperty = true; // convertit automatiquement en package-private
private String fileprivateProperty = "Hello!"; //disponible seulement pour la classe
private static void privateMethod() {
}
} Dans l'exemple ci-dessus, nous avons ajouté un attribut sans mot clé de contrôle d'accès explicite. Dans ce scénario, il prend par défaut le niveau de l'élément contenant. Dans ce cas, c'est notre classe, donc il prend le niveau de PrivateClass .
Une classe de premier niveau ne peut pas être marquée comme private (personne ne pourrait la voir, et donc elle ne pourrait pas être utilisée), mais la définir comme « par défaut » la placera dans le niveau package-protected. Lors de la déclaration d'une variable d'une classe, si le niveau de contrôle du contexte de déclaration est supérieur à celui de la classe, la variable doit également avoir un niveau de contrôle explicite.
Déclarons une variable PrivateClass :
PrivateClass a = new PrivateClass(); // Erreur
private PrivateClass b = new PrivateClass(); // Ok
private PrivateClass c = new PrivateClass(); // OkComme vous pouvez le voir, si le niveau d'accès par défaut du contexte d'une variable est supérieur à une classe que vous lui affectez, vous devez explicitement spécifier le niveau de la variable comme étant identique ou inférieur à celui de la classe.
En résumé
La portée (scope) d'une variable est la zone de code où elle a été déclarée.
La portée variable générale s'applique à tous les blocs de code, y compris les classes.
Un autre moyen nécessaire pour contrôler l'accès aux variables et aux fonctions est d'utiliser des niveaux de contrôle : public, protected, package-protected et private.
Nous verrons dans le prochain chapitre l'écriture des boucles de traitement en Java.
Écrivez une boucle dans vos fonctions
Imaginez que vous ayez un bloc de code que vous devez répéter plusieurs fois. Pourquoi pas pour afficher un message dans la console, par exemple un bonjour, répété cinq fois ? Vous pouvez écrire cinq fois la commande pour le faire. Mais subitement, vous ne souhaitez plus dire “bonjour”, mais “bonjour à tous !”. Il faudrait alors modifier cinq fois le bloc dans votre code. Comme tout développeur vous le dira, nous détestons les répétitions (et sommes un peu fainéants !).
Et c’est pour cela que les boucles existent !
Utilisez des boucles énumérées pour un nombre connu d'itérations
Les boucles énumérées sont des boucles qui sont utilisées si vous savez à l'avance combien de fois vous voulez faire une boucle. En Java, cela s'appelle des boucles for.
Avec elles, vous pouvez indiquer le nombre d'itérations à effectuer :
En tant que valeur entière.
Comme résultat d'une expression qui génère une valeur entière.
Découvrez les boucles for avec une valeur entière
Voici un exemple d'une boucle for qui répète une instruction cinq fois :
for (int i=0; i<5;i++) {
System.out.println("Clap your hands!");
}Dans cet ensemble d'instructions, nous avons une variable de dénombrement i qui est responsable du nombre d'exécutions. Le code équivalent sans utiliser une boucle serait :
System.out.println("Clap your hands!");
System.out.println("Clap your hands!");
System.out.println("Clap your hands!");
System.out.println("Clap your hands!");
System.out.println("Clap your hands!");La syntaxe générale de l'instruction for est la suivante :
for (initialisation; terminaison; increment) {
// code à répéter
}L'initialisation est une expression qui s’initialise au début de la boucle. Elle déclare et assigne généralement un itérateur. Dans notre exemple, nous déclarons un itérateur nommé
ide typeintavec une valeur de0.La terminaison est l’expression qui est évaluée avant chaque exécution de boucle. Si elle est évaluée sur « false », la boucle s'arrête. Dans notre exemple, l'expression de terminaison est
i<5, ce qui signifie que la boucle s'arrête lorsqueiatteint la valeur cinq.L’incrément est une expression qui est évaluée chaque fois qu'une itération de la boucle est effectuée. Dans notre exemple, l'incrément est
i++. Cela signifie que nous ajoutons 1 à la valeur de i à chaque fois que nous passons par notre boucle.La liste des instructions est située entre
{et}. C'est le code qui est exécuté chaque fois que la boucle est exécutée.
Le booléen peut prendre deux valeurs : true ou false. Dans notre boucle for, tant que la condition de terminaison est true, la boucle tourne. Dès que la condition n’est plus vérifiée, elle est donc false, et on sort de la boucle !
Découvrez les boucles for avec les collections
Vous pouvez utiliser les boucles d'énumération si vous avez besoin d'effectuer une itération sur un tableau ou une collection. Voici un exemple pour les tableaux :
int[] myArray = new int[]{7,2,4};
for (int i=0; i<myArray.length; i++) {
System.out.println(myArray[i]);
}Appeler la propriété length d’un tableau retourne le nombre d'éléments de ce tableau. Dans cet exemple, il est utilisé comme condition de terminaison de la boucle "for".
for (int i=0; i<=0; i--) {
System.out.println(“i sera toujours inférieur à 0!”);
}Parfois, on ne veut pas spécifier explicitement combien de fois la boucle doit tourner, mais juste qu’elle doit couvrir tous les éléments d’un tableau. Dans ce cas, Java fournit une construction améliorée appelée for each , qui a la syntaxe générale suivante :
for (int number: myArray){
System.out.println(number);
}Avec la boucle for each , il vous suffit de définir une variable du type contenu par le tableau, ou de la collection que vous souhaitez mettre en boucle. Cette variable se verra attribuer la valeur de chaque élément du tableau ou de la collection, jusqu'à ce que vous ayez atteint la fin.
En français, cet exemple donne : Pour chaque int, qui sera à chaque tour de boucle du tableau myArray rangé dans une variable appelé number , affiche-moi en console la valeur de number .
Répétez la boucle jusqu'à atteindre une condition
Dans ce cas, la boucle doit continuer tant que la condition du while reste vraie. Le nombre de répétitions n'est pas défini par les limites inférieure et supérieure d'un énumérateur, mais par une condition telle que celle d'une instruction if.
Appréhendez la boucle while
Voici à quoi ressemble la syntaxe d'une boucle while :
while (logicalExpression) {
// liste de déclarations
}Elle peut être interprétée comme « tant que l'expression logique est vraie, répétez les instructions ».
Voilà comment cela fonctionne en détail :
Le programme vérifie que
logicalExpressionest vrai (true).Si l’expression est fausse (
false) : les instructions sont ignorées. Vous n'entrez même pas dans le corps de la boucle située entre{et}.Si c'est true : la liste des instructions à l'intérieur de
{et}sont exécutées.Une fois les instructions exécutées, vous revenez à la première étape.
Voyons un exemple concret :
int numberOfTrees = 0;
while (numberOfTrees < 10) {
numberOfTrees += 1;
System.out.println("I planted " + numberOfTrees + " trees");
}
System.out.println("I have a forest!");Cela donnera le résultat suivant :
I planted 1 trees
I planted 2 trees
I planted 3 trees
I planted 4 trees
I planted 5 trees
I planted 6 trees
I planted 7 trees
I planted 8 trees
I planted 9 trees
I planted 10 trees
I have a forest!À chaque tour de boucle, le nombre d'arbres numberOfTrees est incrémenté de 1. Lorsque la variable atteint la valeur 10 , le nombre d'arbres numberOfTrees <10 n'est plus vrai. Donc, la boucle se termine, et le reste du programme continue. Dans ce cas, le programme affiche " I have a forest! " (J'ai une forêt !).
boolean theSunIsUp = true;
while (theSunIsUp) {
print ("Stay awake...forever!");
// theSunIsUp ne change jamais
}
// nous n'atteignons jamais ceci
print ("Go to sleep!");C'est une erreur courante et facile à commettre. Alors, faites attention !
Comme vous pouvez le voir, la condition while est vérifiée AVANT que le bloc de code correspondant puisse être exécuté, même une seule fois ! Cela veut dire que si la condition n’est pas vérifiée, le bloc de code peut ne jamais être exécuté.
Découvrez la boucle do... while
La boucle do... while est très similaire à la première, mais la condition est placée à la fin du bloc de code correspondant. De cette façon, le bloc de code sera toujours exécuté au moins une fois.
Voici à quoi ressemble la syntaxe :
do {
// instructions
} while(logicalExpression);Prenons un exemple :
int pushUpGoal = 10;
do{
print ("Push up!");
pushUpGoal -= 1;
} while(pushUpGoal > 0);De cette façon, au moins une pompe (un « push-up ») est effectuée avant même que la condition soit vérifiée. Modifions cela un petit peu pour montrer la différence par rapport à la boucle while d'origine :
Prenons un exemple :
// Boucle "While"
int pushUpGoal = 0;
while(pushUpGoal > 0) {
System.out.println ("Push up!");
pushUpGoal -= 1;
}
// Boucle "do/while"
int pushUpGoal = 0;
do{
System.out.println ("Push up!");
pushUpGoal -= 1;
} while (pushUpGoal > 0);Vous pouvez voir que l'utilisation de la boucle while d'origine n'effectuera pas de « push-up ». La boucle do... while provoquera un push-up une seule fois.
Ignorez quelques instructions à l'intérieur d'une boucle
Dans chaque type de boucle, il peut y avoir des situations où vous souhaitez sauter certaines itérations, ou interrompre toute la boucle prématurément à une certaine condition.
Par exemple, vous pouvez vouloir répéter quelque chose 10 fois, mais ignorer (ou ignorer partiellement) si la valeur est égale à 2 ou 5 . En Java, pour ignorer une itération dans la boucle, utilisez une instruction continue :
for ( int i=0; i <10; i++) {
// déclarations exécutées à chaque itération
if(i == 2 ||i == 5) {
continue;
}
System.out.println(“Valeur de i : “ + i + “.”);
}Vous pouvez également interrompre complètement la séquence, par exemple si vous voulez trouver un élément dans un tableau, et arrêter de chercher une fois cet élément trouvé :
En Java, pour interrompre une séquence d'exécution, utilisez une instruction break :
int [] myArray = { 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 };
for (int i =0; i<myArray.length;i++) {
if (myArray[i] == "50") {
System.out.println ("J’ai trouvé mon " +basket[i]+ " !");
break;
}
System.out.println ("J’en suis à " +basket[i]+ " ...");
}Une fois que vous avez trouvé l’élément que vous recherchiez, arrêtez de parcourir le reste du tableau.
À vous de jouer !

Prêt à coder ? Pour accéder à l’exercice, suivez ce lien.
En résumé
Les boucles d'énumération exécutent un ensemble d'instructions un nombre de fois fixe, basé sur les valeurs limites inférieure et supérieure de l'énumérateur.
Les boucles conditionnelles exécutent un ensemble d'instructions jusqu'à ce qu'une condition définie soit remplie.
Une erreur courante à surveiller avec les boucles conditionnelles : les boucles infinies !
Les itérations dans une boucle peuvent ignorer certaines instructions à l'intérieur de la boucle en utilisant la commande
continue.Le cycle de boucle peut être interrompu et la boucle peut être interrompue prématurément à l'aide de la commande
break.
Dans le chapitre suivant, nous allons voir comment contrôler le déroulement d'un programme en appliquant des conditions qui vont gérer son comportement selon les situations. Vous me suivez ? On y va !
Contrôlez le déroulement d'un programme avec des conditions
Au fur et à mesure que vous allez écrire des programmes de plus en plus sophistiqués, l'écriture de lignes de code qui doivent s'exécuter l'une après l'autre selon une séquence prédéfinie ne sera plus suffisante. C’est là que vous aurez besoin des conditions !
Reprenons le programme Hello World sur lequel nous avions travaillé :
package hello;
/** Ceci est une implémentation du message traditionnel "Hello world!"
* @author L'équipe Education d'OpenClassrooms
*/
public class HelloWorld {
/** Le programme commence ici */
public static void main(String[] args) {
System.out.println("Hello World!");
}
}Nous avons dit bonjour au monde entier. Ne serait-il pas agréable d'être un peu plus précis, par exemple dire bonjour à une personne réelle ?
Affichez des informations précises si elles sont disponibles
Au démarrage du programme, il se peut que vous ne connaissiez pas le nom d'un utilisateur. Alors pourquoi ne pas utiliser quelque chose comme :
if (si) nous connaissons le nom de la personne, l'afficher ;
else (sinon), continuer à dire bonjour au monde entier.
Voilà à quoi servent les conditions.
Comment pouvons-nous donc connaître le nom de cette personne ?
Revenons à la toute première déclaration qu'un programme exécute, la signature de la fonction main :
public static void main(String[] args) {Avez-vous remarqué String[] args à l'intérieur des parenthèses () ? Nous avons une variable args définie avec le type String[] , qui est un tableau de chaînes de caractères (nous y reviendrons dans la prochaine partie). Cela signifie que la fonction main est capable de recevoir des arguments que nous pouvons utiliser lorsque le programme est lancé.
Vous vous souvenez de la commande qui démarre un programme Java depuis le terminal ? Si on reprend notre exemple Hello World, nous avions suivi les étapes suivantes :
Compiler le programme avec la commande javac.
Exécuter le programme avec la commande java.
La magie qui consiste à envoyer les arguments à votre programme se déroule durant la deuxième phase. Au lieu de simplement fournir le nom de la classe contenant la méthode main, vous pouvez ajouter des arguments, séparés par un espace. Voici ce que vous pouvez faire :
$ java hello.HelloWorld EstherAprès le nom de la classe, nous avons ajouté Esther , une String . Au démarrage du programme, cette chaîne est contenue dans le tableau args qui fait partie de la signature de la fonction principale. Cependant, notre code original ne s'en sert pas. Nous devons le changer pour :
Vérifier si le tableau
argscontient une valeur (la propriétélengthfournie par les tableaux peut nous aider ici).Si c'est le cas, appeler la méthode
sayhelloToavec la valeur qu'elle contient.Sinon, continuer à appeler la méthode avec la chaîne
world.
Voilà ce que ça donne :
package conditions;
/**Ce programme affiche
* - un message Hello personnalisé si un argument a été envoyé lors de l'exécution du programme
* - le message traditionnel "Hello World!" si ce n'est pas le cas
* @author L'équipe Éducation d'OpenClassrooms
*/
public class ConditionalHello {
/** Le programme commence ici
* @param args arguments envoyé avec la ligne de commande
*/
public static void main(String[] args) {
if (args.length==1) {
sayHelloTo(args[0]);
}
else {
sayHelloTo("world");
}
}
/** affiche le message hello au destinataire fourni
* @param recipient
*/
private static void sayHelloTo(String recipient) {
System.out.println("Hello " + recipient + "!");
}
}Maintenant :
Compilez le programme avec la commande javac.
$ javac conditions/ConditionalHello.javaExécutez le programme sans argument.
$ java conditions/ConditionalHello Hello world!Exécutez le programme en ajoutant "Esther" après le nom de la classe.
$java conditions/ConditionalHello Esther Hello Esther!
Ça marche ! Voyons plus en détail comment fonctionne réellement cette affectation conditionnelle If/Else.
Testez vos conditions avec des booléens
En langage Java, pour valider une condition, vous utilisez les booléens.
Vous vous souvenez des booléens ?
boolean isLearningJavaWithOpenclassrooms = true;Ce qui importe vraiment, c'est que la condition du if soit résolue par un booléen. Cette condition peut être exprimée de la façon suivante :
Une valeur true ou false. Par exemple,
if(true).Une variable de type boolean . Par exemple,
if(myVar)oùmyVarest de type boolean .Une expression qui se résout en une valeur booléenne. Cette expression peut être aussi simple que le résultat d'un appel de méthode.
Par exemple :
String weatherToday="The weather is good";
String weatherTomorrow="The weather is good";
weatherToday.equals(weatherTomorrow); // -> trueequals est une méthode de la classe String qui permet de comparer deux chaînes.
En effet, on ne compare pas deux objets via == . == vérifie si deux objets ne font qu’un (la même adresse en mémoire), et non s’ils ont le même contenu. La méthode equals, par opposition, compare le contenu. Elle peut donc être utilisée comme une condition.
Pour produire un booléen, vous pouvez également utiliser des opérateurs de comparaison.
Utilisez les opérateurs de comparaison
Comme leur nom l'indique, les opérateurs de comparaison sont utilisés pour comparer deux valeurs. Ils sont au nombre de six :
==égal à (exactement le même) ;!=non égal à (différent, de quelque façon que ce soit) ;<inférieur à ;<=inférieur ou égal à ;>supérieur à ;>=supérieur ou égal à.
Voici quelques exemples de comparaisons numériques :
2 == 2 // -> true
2 == 3 // -> false
4 != 4 // -> false
4 != 5 // -> true
1 < 2 // -> true
1 < 1 // -> false
1 <= 1 // -> true
3 > 4 // -> false
5 > 4 // -> true
5 >= 4 // -> trueEnfin, vous voudrez peut-être avoir des conditions plus compliquées, où la décision dépend du résultat d'une combinaison d'expressions différentes. C'est ici que vous utiliserez les opérateurs logiques.
Utilisez les opérateurs logiques
Ces opérateurs vous permettent de combiner des valeurs booléennes : soit des valeurs booléennes spécifiques, soit des résultats d'expressions. Ils sont au nombre de trois :
&&ET logique.
Le résultat n'est vrai que si toutes les parties participantes sont vraies.
Exemple : le résultat deexpression1 && expression2n'est vrai que siexpression1est vraie ETexpression2est également vraie.||OU logique.
Le résultat est vrai si au moins une des parties participantes est vraie.
Exemple : le résultat deexpression1 || expression2est vrai siexpression1est vraie OUexpression2est vraie. Il en sera de même si les deux expressions sont vraies !!NON logique.
Il inverse simplement l'expression donnée.
Le résultat de!expression1est vrai siexpression1est fausse ; le résultat est faux siexpression1est vraie.
Voici quelques exemples :
true && true // -> true
true && false // -> false
false && false // -> false
true || false // -> true
true || true // -> true
false || false // -> false
!true // -> false
!false // -> trueLes mêmes règles s'appliquent si plus de deux expressions sont enchaînées les unes après les autres :
true && true && true // -> true
true && true && false // -> false
true || false || false// -> true
false || false || false// -> falseComme pour les opérateurs numériques, les opérateurs logiques respectent la priorité des opérations : l'opérateur d'inversion ! vient en premier, puis l'opérateur ET && et enfin, l'opérateur OU || . Par exemple :
false || true && true // -> true
!false && true || false // -> trueComme pour les opérateurs numériques, utilisez les parenthèses ( () ) pour changer l'ordre :
(true && false) || true // -> true
!(true && false || !true) // -> truePour vous entraîner, pouvez-vous calculer le résultat des expressions suivantes ?
!true && false!(true && false)4 < 3 || 4 >= 4(!(1 == 2) || 3 != 3) && 35 > 34Dans notre exemple Hello World, nous avons défini une alternative.
Et si on veut prendre des décisions plus complexes, basées sur plusieurs valeurs possibles ?
Gérez une chaîne de conditions
Nous avons personnalisé notre message de bienvenue, mais que faire si nous voulons plaire aux personnes ayant plus d'un prénom ?
Une première possibilité consiste à créer une chaîne de conditions. Voici la forme générale :
if(condition1) {
// instructions
}
else if(condition2) {
// instructions
}
else {
// instructions
}Dans notre exemple Hello World, nous pourrions envoyer deux chaînes de caractères après le nom de la classe lors de l'exécution du programme. Cela signifierait que le tableau args contient deux éléments. Nous pourrions alors envoyer une chaîne contenant la concaténation de ces deux chaînes à notre fonction sayHelloTo :
public static void main(String[] args) {
if (args.length==1) {
sayHelloTo(args[0]);
} else if (args.length==2) {
sayHelloTo(args[0] + "-" + args[1]);
} else if (args.length==3) {
sayHelloTo(args[0] + "-" + args[1] + "-" + args[2]);
} else {
sayHelloTo("world");
}
}Dans cet exemple, notre code évalue les différentes valeurs d'une condition particulière (la taille du tableau args ). Dans ce cas, Java fournit une construction spécifique qui ne fait l'évaluation qu'une seule fois : l'instruction switch.
Utilisez l'instruction switch
Parfois, il y a des circonstances où vous avez un ensemble plus long de conditions à remplir, et où l'une d'elles peut être true dans la séquence.
Réécrivons notre exemple if, else if et else en utilisant l’instruction switch :
public static void main(String[] args) {
switch(args.length) {
case 0: // aucun argument n'a été envoyé
sayHelloTo("world");
break;
case 1: // l'utilisateur a fourni un argument dans le terminal
sayHelloTo(args[0]);
break;
case 2: // l'utilisateur a fourni 2 arguments
sayHelloTo(args[0] + "-" + args[1]);
break;
default: // l'utilisateur a fourni plus d'arguments qu'on peut en gérer !
System.out.println("Sorry, I don't know how to manage more than 2 names!");
}
}Avec l'instruction switch :
l'expression conditionnelle
args.lengthn'est évaluée qu'une seule fois ;chaque cas compare le résultat de l'expression à une valeur spécifique ;
par défaut, une fois qu'un cas est évalué true, tous les cas ci-dessous sont également validés en cascade. Pour éviter cela, terminez chaque cas par une instruction
break;;la clause Default à la fin est validée si aucun des autres cas n’est validé.
L'instruction switch rend votre intention plus claire qu'une chaîne de if/else, et vous permet d'évaluer l'état une seule fois. C'est cool. 😎 Mais ce n'est pas fini ! Encore un autre type de données : les énumérations.
Utilisez le type énumération
Les énumérations sont des listes de cas prédéfinis destinés à vous aider pendant le développement. Elles améliorent la lisibilité du code et diminuent les risques d'erreurs, en bloquant par exemple les valeurs que peut prendre une variable.
Prenons un exemple où nous définissons toutes les directions possibles (nord, est, sud, ouest) dans une énumération, et utilisons-les dans un switch .
Voici dans cet exemple l’énumération :
enum Direction {
north, east, south, west;
}Comme le switch doit couvrir tous les cas possibles, nous pouvons utiliser deux approches.
Approche n°1 : lister tous les cas d'énumération en switch
public class myDirection {
/** listez toutes les directions possibles */
enum Direction {
north, east, south, west;
}
/** trouvez le nord */
public static void main(String[] args) {
Direction direction = Direction.north;
switch (direction) {
case north:
System.out.println("You are heading north");
break;
case east:
System.out.println("You are heading east");
break;
case south:
System.out.println("You are heading south");
break;
case west:
System.out.println("You are heading west");
break;
}
}
}Dans ce cas, nous couvrons toutes les directions, nous n'avons théoriquement pas besoin de la clause default .
Approche n°2 : définir un cas d'utilisation en particulier
Définissons le cas d'utilisation où nous ne devrons nous diriger que vers le nord :
public static void main(String[] args) {
Direction direction = Direction.north;
switch (direction) {
case north:
System.out.println("You are heading north");
break;
default:
System.out.println("You are lost!");
}
}À vous de jouer !

Prêt à coder ? Pour accéder à l’exercice, suivez ce lien.
En résumé
Les conditions vous permettent d'exécuter un bloc de code uniquement si une valeur
boolean, une variable ou une expression est évaluée commetrue.Un moyen de fournir des valeurs à un programme est d'envoyer des arguments sur la ligne de commande. Ces arguments sont mis à la disposition de la fonction main dans le tableau
args.Les expressions conditionnelles utilisent l'arithmétique booléenne, notamment les opérateurs de comparaison et les opérateurs logiques.
Vous pouvez évaluer plusieurs conditions en créant des chaînes d'instructions if/else if/else.
L'instruction switch est une façon plus propre d'exécuter en fonction des différentes valeurs possibles d'une condition particulière.
Les énumérations vous permettent de définir un ensemble de valeurs possibles pour rendre votre code encore plus propre.
Programmez en orienté objet avec Java
Définissez les objets et leurs attributs avec des classes
Dans la partie précédente, vous avez appris les bases de la programmation avec le langage Java. Dans cette partie, nous allons plus loin avec la programmation orientée objet (dite POO) avec Java.
Découvrez la Programmation Orientée Objet
Vous avez peut-être déjà entendu le terme "objet" dans un contexte de programmation. Mais qu'est-ce que cela veut dire exactement ? Commençons par regarder des objets du monde réel, comme des stylos, des livres, des Smartphones, des ordinateurs, etc.
Chaque type d’objet se présente sous différentes formes, mais vous pouvez les ranger dans des catégories. Si vous voulez acheter une chaise, vous vous rendez dans un magasin de meubles, au rayon correspondant, et vous avez le choix entre plusieurs modèles. Elles seront parfois très différentes les unes des autres, mais elles n’en seront pas moins des chaises.
Vous reconnaissez ces différents objets comme faisant partie du même groupe ou type. Vous remarquez des points communs entre eux, recueillez les informations et créez une représentation mentale de cette catégorie d'objets donnée.
Un autre exemple : il existe différents types de livres, mais ils ont tous tendance à avoir un titre, un auteur, une couverture, des pages, etc. En d'autres termes, les objets livres ont tous des attributs similaires qui vous permettent de les classer dans votre esprit comme faisant partie de la catégorie « livre ».
Cette liste d'attributs que nous venons de décrire pour un livre agit comme une sorte de plan pour l'objet "livre". En programmation, cela s'appelle une classe. Pour créer un livre, vous vous basez sur le plan correspondant. Bien sûr, le livre créé a un titre… Cela ne vous rappellerait pas les variables ? Après tout, en développement, tout doit avoir un nom pour pouvoir être utilisé.
Comment définir des noms de classes ?
Comme pour les variables de nommage, les noms de classes doivent être descriptifs. La principale différence, c'est qu'au lieu d'utiliser un camelCase standard, la première lettre devra également être en majuscule ; par exemple, CreationMerveilleuse et non creationMerveilleuse.
Concevez des classes
Pour savoir comment concevoir une classe, continuons avec l'exemple du livre. Nous avons déjà identifié un échantillon d'informations qui peuvent décrire un livre donné :
titre ;
auteur ;
nombre de pages ;
éditeur.
Ce sont les attributs de tout livre dans la vie réelle. Dans le contexte des classes, ces attributs sont appelés attributs de classe en langage Java. Il s’agit simplement d’un nom un peu plus pompeux pour quelque chose que vous connaissez déjà : les variables !
Maintenant que vous avez compris la théorie, passons à la pratique et mettons cela par écrit !
Pour déclarer une classe en Java, utilisez le mot-clé class suivi d'un nom personnalisé. Ensuite, terminez avec des accolades ouvrante et fermante ({}) pour l'ensemble du contenu. Ceci inclut la liste complète de ses attributs :
class Book {
// propriétés d'une classe
}Maintenant, ajoutons les champs définis précédemment :
class Book {
String title;
String author;
int numberOfPages;
String publisher="OC";
}Avez-vous remarqué que les trois premiers n'ont pas de valeurs, mais que le dernier en a une ?
L'exemple précédent peut s'appliquer si vous êtes un éditeur et que vous voulez cataloguer vos livres. Comme ce sont vos propres stocks, vous savez que la valeur de l'éditeur sera toujours la même, peu importe le livre. Les titres des livres, les auteurs et les numéros de page, cependant, changeront en fonction du livre en question.
Cependant, si vous revenez à l'exemple original d'une librairie en ligne, la classe ressemblerait davantage à ceci :
class Book {
String title;
String author;
int numberOfPages;
String publisher;
}Comme vous aurez des livres de plusieurs éditeurs différents, vous ne pouvez pas mettre pour chacun d'entre eux une valeur par défaut. Vous définissez donc ici le champ, et vous ajouterez une valeur personnalisée ultérieurement !
Utilisez des classes
Vous avez un tout nouveau type – Book 📖 – mis en œuvre !
Que pouvez-vous en faire ?
Les classes représentent le concept, ou type, de nos objets, ici Book.
Mais lorsque vous effectuez une recherche, pour un livre par exemple, vous ne tapez pas seulement « livre », n'est-ce pas ? Ce n'est pas vraiment utile ! Vous avez besoin d'une instance spécifique d'un livre, par exemple Alice au pays des merveilles. Vous cherchez un objet réel que vous pouvez feuilleter et lire. C'est la même chose en programmation informatique.
Pour utiliser une classe, vous devez créer un objet concret de cette classe. En d'autres termes, vous avez besoin d'un objet spécifique, comme un livre en particulier (Alice au pays des merveilles). Ce livre spécifique est une instance de classe ! Comme son nom l'indique, le processus est appelé instanciation ou initialisation d'un objet. Pour cela, vous créez un objet du type de la classe.
Créez des instances de classe
En Java, chaque champ de l'objet créé doit avoir une valeur. Ces valeurs peuvent être fournies de plusieurs façons. Vous l'avez vu avec l'exemple de l'éditeur : nous avions déclaré la valeur OC dans la définition de la classe.
Une autre manière de procéder consiste à fournir une valeur dans l'affectation qui crée la classe, c’est le constructeur. Il permet à la fois de créer une instance de la classe et de spécifier la valeur des attributs de notre nouvel objet, pratique, non ?
Ajoutons maintenant un constructeur à notre classe Book :
class Book {
String title;
String author;
int numberOfPages;
String publisher;
//Constructeur de la classe Book
Book(String title, String author, int numberOfPages, String publisher) {
//Initialise l’attribut title avec la valeur de l’argument title
this.title = title;
this.author = author;
this.numberOfPages = numberOfPages;
this.publisher = publisher;
}
}En Java, le constructeur est une fonction spéciale du même nom que la classe avec les arguments passés en paramètres. À l’intérieur de la fonction, nous utilisons les paramètres pour initialiser les attributs de notre objet avec le mot clé this.
Il est également possible de déclarer plusieurs constructeurs différents pour la même classe. Ceux-ci peuvent même s’appeler entre eux ! Voyons cela ensemble avec notre classe Book :
class Book {
String title;
String author;
int numberOfPages;
String publisher;
//Constructeur secondaire de la classe Book
Book(String title, String author, int numberOfPages) {
//Utilise le constructeur principal avec des valeur prédéfinies
this(title, author, numberOfPages, "OC");
}
//Constructeur principal de la classe Book
Book(String title, String author, int numberOfPages, String publisher) {
this.title = title;
this.author = author;
this.numberOfPages = numberOfPages;
this.publisher = publisher;
}
}Maintenant que notre classe Book possède au moins un constructeur, voici un exemple de code pour créer un livre :
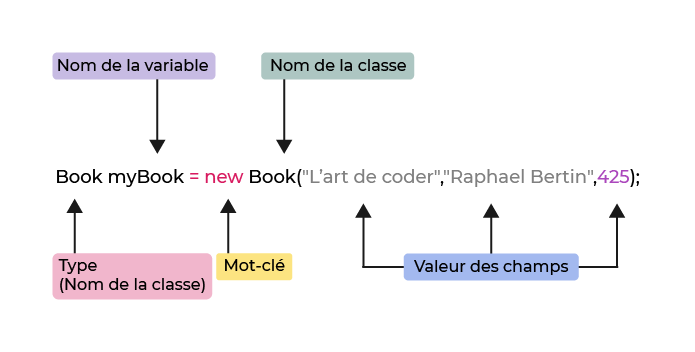
Comme vous pouvez le voir, il y a quelques éléments différents. Tout d'abord, nous faisons une déclaration classique d'une variable, avec son nom myBook et son type Book . En d’autres termes, nous disons à notre programme de créer un objet appelé myBook qui est de type Book.
Vous vous souvenez, quand on disait qu'une classe est un type complexe avec un nom ? Eh bien, en voilà la preuve ! Au lieu de int , double ou String , le type ici est la classe que nous avons créée !
Maintenant, voici le plus cool. Cette variable est déclarée et initialisée avec l'expression de création de l'objet new Book("Coding is art","Becky James",425); . Cette expression est composée du mot clé new , suivi du constructeur ( Book ), et de valeurs à l'intérieur des parenthèses. Comme vous pouvez le voir, les parenthèses contiennent une valeur spécifiée pour chacun des champs originaux : title , author et numberOfPages .
Eh bien, voilà beaucoup de concepts et de vocabulaire nouveaux à assimiler ! Avant de continuer, récapitulons avec un schéma rapide :
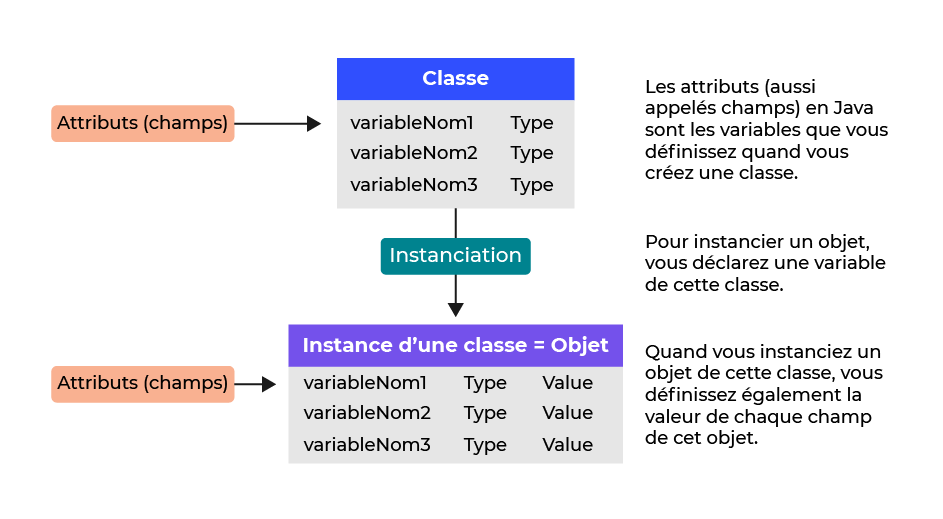
C'est mieux comme ça ? Souvenez-vous :
utilisez une classe comme modèle pour vos futurs objets. Dans une classe, définissez le nom et le type de certaines variables. En Java, ceux-ci sont généralement appelés attributs et champs ;
pour utiliser le plan vraiment cool que vous avez créé, vous devez créer un objet en utilisant le processus d'instanciation. Cela signifie déclarer une variable avec votre classe comme type, puis utiliser l'expression de création d'objet que vous avez vue ci-dessus ;
un objet s'appelle une instance de classe.
Maintenant, vous avez tout ce dont vous avez besoin ! Vous avez votre objet "livre", mais imaginons que vous changiez d'avis sur la valeur de vos variables. Comment accéder aux champs associés à votre nouvel objet flambant neuf ?
Une façon courante d'accéder aux champs dans de nombreux langages de programmation consiste à utiliser le point( . ). Cela signifie que vous devez écrire le nom d'une instance ou d'un objet suivi d'un nom d'attribut d'intérêt, séparés par un point : instanceVariableName.attributeName .
Exemple : Je cible l’attribut titre de cet objet book :
myBook.title = "Coding is Art"
myBook.author = "Becky James";
myBook.numberOfPages = myBook.numberOfPages + 10;Vous pouvez maintenant modifier la valeur des champs à l'intérieur de votre objet ! Imaginez que vous vouliez ajouter dix pages parce que vous avez oublié de prendre en compte l'index du livre. Vous pouvez soit taper le nouveau numéro directement, soit ajouter dix pages à la valeur existante comme dans la troisième ligne. C'est très pratique pour faire de petits changements. 🙂
En résumé
Une classe est le plan d'un objet.
Une classe vous permet de créer des types complexes en regroupant ses attributs, en définissant des champs.
Pour créer un objet, vous devez déclarer une variable d'une classe et l'instancier. Utiliser le point (.) donne accès aux champs.
Passons au chapitre suivant pour aborder deux notions très puissantes en programmation orientée objet : l'héritage et le polymorphisme.
Spécialisez vos classes avec l’héritage et le polymorphisme
Dans le chapitre précédent, nous nous sommes intéressés à la notion de type complexe, et vous avez écrit et instancié votre première classe ! Dans ce chapitre, nous aborderons des concepts très importants de la programmation orientée objet en spécialisant nos classes.
Spécialisez une classe grâce à l’héritage
Reprenons notre exemple d’un livre défini par un titre et un auteur. Quand on y pense, un CD musical n’a-t-il pas également un titre et un auteur ? Ce socle commun peut être mis dans une classe média, en généralisant. Bien sûr, un livre possède des éléments particuliers (nombre de pages, par exemple), et un CD également (durée).
Dans l’exemple ci-dessous, nous avons une classe mère FigureGeometrique que nous allons spécialiser en Carre . Le mot clé est extends. On peut dire que la classe Carre étend la classe FigureGeometrique .
Commençons par définir la classe mère FigureGeometrique :
public class FigureGeometrique {
private int x;
private int y;
public void moveTo(int newX, int newY) {
this.x = newX;
this.y = newY;
}
}Ensuite, nous créons une classe fille Carre :
public class Carre extends FigureGeometrique {
private long cote;
public long getCote() {
return cote;
}
public long getPerimetre(){
return 4*cote;
}
}Avec la classe Carre, nous récupérons automatiquement tous les attributs de la classe de mère FigureGeometrique . Et nous lui avons ajouté un nouvel attribut de classe et 2 nouvelles méthodes participant ainsi à la spécialisation.
Notons également que lorsqu’on fait de l’héritage, tous les champs sont hérités. Ils peuvent être manipulés si leur accessibilité le permet (nous avons abordé ce concept dans le chapitre 5 de la première partie).
Dans notre exemple, nous pourrions créer une classe intermédiaire nommée FigureGeometriqueAvec4Cotes et définir notre héritage de cette manière :
FigureGeometrique → FigureGeometriqueAvec4Cotes → Carre ;
FigureGeometrique → FigureGeometriqueAvec4Cotes → Rectangle ;
FigureGeometrique → FigureGeometriqueAvec4Cotes → Losange ;
…
À quoi correspondent les objets de la classe dérivée ?
Tout objet d'une classe dérivée est considéré comme étant avant tout un objet de la classe de base :
un
Carreest avant tout uneFigureGeometrique;tout objet d'une classe dérivée cumule les champs dérivés dans la classe de base avec ceux définis dans sa propre classe :
public class Test {
public static void main(String[] args) {
FigureGeo figure = new FigureGeometrique();
figure.moveTo(1, 1);
Carre carre = new Carre();
carre.moveTo(2, 2);
}
}Initialisez les attributs hérités
L’initialisation des attributs d’une instance de classe se fait dans le constructeur de la classe, vous vous souvenez ? Lorsque des attributs sont hérités d’une classe mère, il est tout à fait possible de les initialiser dans le constructeur de la classe fille en appelant le constructeur de la classe parent. On voit ça ensemble ?
Commençons par créer un constructeur dans la classe mère FigureGeometrique :
class FigureGeometrique {
private int x;
private int y;
FigureGeometrique(int x, int y) {
this.x = x;
this.y = y;
}
}Ensuite, utilisons celui-ci dans notre classe fille Carre :
class Carre extends FigureGeometrique {
long cote;
Carre(long cote, int x, int y){
//Appel du constructeur de la classe mère FigureGeometrique
super(x, y);
this.cote = cote;
}
}En Java, pour appeler le constructeur de la classe mère depuis le constructeur de notre classe fille, nous utilisons la méthode super. Celle-ci fait directement référence à la méthode écrite dans la classe parent, ici le constructeur, mais nous verrons ça plus en détail avec le polymorphisme !
Redéfinissez une méthode de classe grâce au polymorphisme
Lorsque vous construisez une classe héritant d'une autre classe, vous avez la possibilité de redéfinir certaines méthodes de la classe mère. Il s'agit de remplacer le comportement de la fonction qui a été définie par la classe mère.
C’est le concept de polymorphisme. L’idée étant de pouvoir utiliser le même nom de méthode sur des objets différents. Et bien sûr, cela n’a de sens que si le comportement des méthodes est différent.
Redéfinissez une méthode de la classe parente
Considérons le code ci-dessous, considérons la méthode deplacer() dans la classe mère Animal :
class Animal {
void deplacer() {
System.out.println("Je me déplace");
}Appliquons le principe de polymorphisme pour cette méthode dans les différentes classes filles Chien , Oiseau et Pigeon :
class Chien extends Animal {
void deplacer() {
System.out.println("Je marche");
}
}class Oiseau extends Animal {
void deplacer(){
System.out.println("Je vole");
}
}class Pigeon extends Oiseau {
void deplacer() {
System.out.println("Je vole surtout en ville");
}
}Sur toutes ces classes, vous pouvez donc appeler deplacer() . Le polymorphisme permet alors d'appeler la méthode adéquate selon le type d'objet :
public class Test {
public static void main(String[] args) {
Animal a1 = new Animal();
Animal a2 = new Chien();
Animal a3 = new Pigeon();
a1.deplacer();
a2.deplacer();
a3.deplacer();
}
}Même si le type de nos 3 variables sont les mêmes (Animal), les instances sont différentes et donc leurs comportements aussi. Dans notre exemple, l'exécution donne comme résultat :
Je me déplace Je marche Je vole surtout en ville
Appelez une méthode de la classe parente
La redéfinition des méthodes dans la classe fille remplace tout le code de la méthode mère. Parfois ce fonctionnement est idéal, parfois nous souhaitons quand même appeler le code de la classe mère tout en ajoutant autre chose dans la classe fille.
Dans notre exemple, imaginons que le chien aboie lorsqu’il se déplace.
Nous pouvons accéder à l’implémentation parente grâce au mot clé super, et appeler la méthode déplacer avant d’ajouter l’aboiement du chien :
class Chien extends Animal {
void deplacer() {
super.deplacer();
System.out.println("ouaf ouaf");
}Attention, dans le cas d’un héritage multiple, il est seulement possible d'accéder à l’implémentation de la classe parente, pas plus ! Dans notre exemple, si nous créons une nouvelle classe fille Caniche qui étend de Chien, nous n’accéderons dans celle-ci avec super qu’à l’implémentation de la classe Chien et non de la classe Animal.
Utilisez les annotations
Il existe en Java des types spéciaux commençant par@, appelés annotations. Ils servent à préciser le comportement d’une classe, d’une méthode, d’un attribut ou même d’une variable. Les annotations donnent des informations au compilateur pour l'exécution du code de notre programme.
En Java, l'une des annotations les plus connues et utilisées est @Override. Elle est utilisée en complément du polymorphisme pour indiquer que la méthode annotée est une redéfinition d’une méthode de la classe mère. Si l’annotation est présente sur une méthode, le compilateur va vérifier que la signature de la méthode est bien identique à celle de la méthode dans la classe mère.
Reprenons une nouvelle fois notre exemple et voyons comment utiliser l'annotation @Override :
class Animal {
void deplacer() {
System.out.println("Je me déplace");
}
class Chien extends Animal {
@Override
void deplacer() {
System.out.println("Je marche");
}
}En résumé
L’héritage est un concept fondamental en Java qui permet de réutiliser du code de la classe mère.
Le polymorphisme permet de "surcharger" les méthodes de la classe mère pour redéfinir leurs comportements sans changer leur signature.
Dans le prochain chapitre, nous verrons comment stocker et manipuler beaucoup de données avec les collections. Nous verrons qu’il existe beaucoup de types de collections différents pour classer les éléments.
Gérez les piles de données avec la bonne collection
Imaginez que vous êtes le responsable de la communication d'un théâtre à la mode. Votre responsabilité principale consiste à gérer les premiers rangs, "Front Rows", c'est-à-dire à veiller à ce que les parents et amis invités ("Guests") par les artistes, ainsi que les autres VIP, obtiennent les meilleures places pour le spectacle.
Si tout ce que vous aviez à faire consistait à gérer deux invitations pour l'artiste principal, vous pourriez imaginer utiliser seulement deux variables de type String contenant le nom de l'invité. Le code Java ressemblerait à cela :
// Déclarez une variable pour chaque invité de la première rangée
String frontRowGuest1;
String frontRowGuest2;Ensuite, lorsque l'artiste vous fournirait les informations, vous n'auriez qu'à attribuer un nom à chaque variable. Par exemple :
// Attribuez le nom des invités
frontRowGuest1="Mary Poppins";
frontRowGuest2="Jane Banks"Si le premier rang compte 30 sièges, cela obligera à avoir 30 variables déclarées une par une. Ne serait-il pas plus facile d'utiliser une seule variable qui contiendrait toutes ces informations ?
Vous avez de la chance ! Java offre une structure de données capable de contenir un nombre fixe de valeurs d'un même type. Cette structure s'appelle un tableau (ou Array, en anglais). Voyons quand et comment en utiliser un.
Utilisez un tableau pour stocker un nombre fixe d'éléments
Un tableau est une liste ordonnée et numérotée d'éléments du même type (par exemple, un tableau de int ne contiendra que des int !). Chaque élément est associé à un numéro appelé index. L'indexation commence par 0 (pas 1 !), ce qui signifie que le premier élément est associé à un index 0, le deuxième à 1, etc.
Déclarer un tableau utilise la même syntaxe que pour n'importe quelle variable. Par exemple, pour stocker le nombre de tasses de café que vous buvez chaque jour de la semaine, vous pouvez déclarer un tableau d'entiers avec la syntaxe suivante :
// Déclarez la variable
int[] cupsOfCoffeePerDayOfTheWeek;Vous fournissez :
Le type des éléments que le tableau contiendra, suivi de
[].Le nom de la variable qui doit expliciter clairement l'intention du tableau.
Instanciez ensuite le tableau avec sept emplacements (les sept jours de la semaine) :
// Créez le tableau et assignez-le à la variable
cupsOfCoffeePerDayOfTheWeek=new int[7];Lorsque le tableau est créé, chaque élément est initialisé avec la valeur par défaut du type du tableau. Dans le cas d'un tableau de int , cela signifie 0.
Vous pouvez aussi déclarer et créer un tableau en une seule ligne. Voici ce que vous feriez pour déclarer une variable et l'initialiser directement avec un nouveau tableau de trois int :
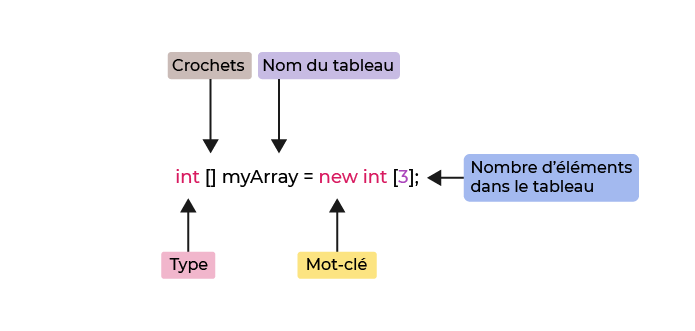
Pour en revenir à notre gestion hebdomadaire du café : maintenant que le tableau est créé, vous pouvez y effectuer deux opérations :
Accéder à une valeur à un index donné.
Définir une nouvelle valeur à un index donné.
Dans les deux cas, vous utilisez le nom de la variable suivi de [ , la valeur de l'index, et ] .
Par exemple, si vous buvez trois cafés le cinquième jour de la semaine, vous pouvez écrire :
// Attribuez la valeur 3 au cinquième jour de la semaine
// C'est l'index 4, puisque le premier index est 0
cupsOfCoffeePerDayOfTheWeek[4]=3;Pour afficher le nombre de cafés que vous buvez le premier jour de la semaine, vous pouvez écrire l'instruction suivante :
//Afficher le nombre de cafés le premier jour de la semaine
System.out.println(cupsOfCoffeePerDayOfTheWeek[0]);Enfin, si vous souhaitez définir toutes les valeurs en même temps, vous pouvez également :
soit définir toutes les valeurs au moment de la création du tableau ;
soit utiliser une boucle qui définit chaque valeur, une par une.
Pour l'instant, créons un nouveau tableau et assignons-le à la variable cupsOfCoffeePerDayOfTheWeek :
//Créez un nouveau tableau avec toutes les valeurs et assignez-le à notre variable
cupsOfCoffeePerDayOfTheWeek=new int[]{6,2,3,7,3,4,1};À vous de jouer !

Et le premier rang de notre salle de théâtre ? Eh bien, vous n'avez qu'à créer un tableau de chaînes avec le nombre de sièges que contient votre premier rang. Vous pouvez soit ajouter tous vos invités au moment de la création, soit les ajouter individuellement en utilisant la syntaxe [] .
Essayez les tableaux avec l'exercice interactif suivant :
Pour accéder à l’exercice, suivez ce lien.
Si vous voulez aller plus loin et gérer tous les rangs de votre salle de spectacle, vous pouvez utiliser des tableaux multidimensionnels. Imaginons que votre théâtre contienne 30 rangs de 12 places. Voici comment créer un tableau et attribuer une valeur au sixième siège du dixième rang :
// Créez un tableau multidimensionnel pour gérer tous les rangs d'un théâtre
String[][] myTheatreSeats=new String[30][12];
// Rang 10, siège 6. N'oubliez pas que l'index commence à 0!
myTheatreSeats[9][5]="James Logan";Les tableaux sont efficaces et parfaits pour gérer un nombre fixe d'éléments. Dans la pratique, vous devez souvent gérer un nombre variable d'éléments. Java facilite le traitement de ces cas avec les collections.
Commençons par la collection la plus populaire d'entre toutes, la liste.
Utilisez des listes si le nombre d'éléments n'est pas fixe
Les tableaux sont bien pratiques, mais ils ont leurs limites :
ils ont une taille fixe ;
vous ne pouvez modifier que les valeurs existantes.
Imaginons que vous vouliez classer des animaux du plus mignon au moins mignon, et que vous commenciez par un petit tableau composé de quatre éléments : renard, hibou, koala et loutre. Disons que vous voulez ajouter un écureuil et le mettre entre le renard et le hibou.
Avec un tableau, vous ne pouvez pas insérer un élément supplémentaire, vous pouvez seulement remplacer des éléments. Vous ne pouvez pas non plus ajouter votre écureuil à la fin de la liste (en programmation, on appelle cela : append). Pour cela, il faudrait créer un tout nouveau tableau de cinq cases au lieu de quatre. Puis, vous devrez à nouveau ajouter tous vos éléments à la main. Ça a l'air plutôt long et ennuyeux, non ?
C'est là qu'une liste ordonnée entre en jeu ! Comme elles sont modifiables, vous pouvez modifier le contenu et le nombre d'éléments d'une collection. Après les restrictions des tableaux, cela peut sembler magique !
Un petit exemple pour voir ce dont on parle :
List<String> myList = new ArrayList<String>();Entre autres choses, avec les listes, vous pouvez :
accéder à chaque élément via son index ;
ajouter (append) un nouvel élément à la fin ;
insérer un nouvel élément à un index spécifique ;
supprimer un nouvel élément à un index spécifique.
Répétons-le, il s'agit de changer la valeur, pas le type. Le type ne peut pas être changé, même avec la puissance impressionnante d'une ArrayList !
Très utile ! En Java, il existe plusieurs classes qui utilisent des listes, la plus utilisée étant l’ArrayList. Vous pouvez même créer la vôtre ! L'important est que la classe que vous sélectionnez utilise l'interface List .
Une interface est un contrat qui définit toutes les opérations qu'une classe doit fournir. Dans le cas de l'interface List , vous pouvez vérifier toutes les opérations prises en charge et la manière d'utiliser les classes sur le site web officiel des tutoriels Java (ressource en anglais).
Dans la suite de ce chapitre, nous utiliserons la classe ArrayList . Voyons comment cela fonctionne en pratique !
Créez une liste et ajoutez des éléments
Pour créer une liste, vous devez :
Déclarer une variable dont le type est l'interface
List. Cela signifie que vous pouvez assigner n'importe quel objet à la variable qui met en place l'interfaceList,y compris la classeArrayList.Initialiser la variable avec une expression commençant par le mot clé
newqui crée une instance de la classeArrayList.
Ceci peut être fait en une seule ligne avec la syntaxe suivante :
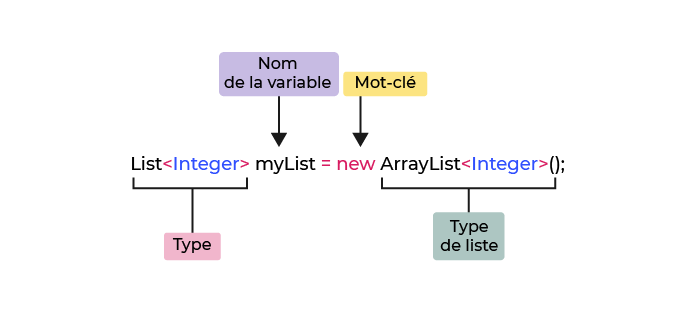
La déclaration a lieu avant l'opérateur d'affectation
=. Tout d'abord, vous avez le type, qui estList. Ceci est directement suivi de<Integer>, qui est le paramètre de type pour la liste. Un paramètre de type limite le type d'objets qui peuvent être stockés dans la liste. Dans cet exemple, vous ne pourrez enregistrer que des nombres entiers.La création en tant que telle a lieu avec l'expression new
ArrayList<Integer>(). L'objet initialisé est assigné à la variablemyList.
Vous avez peut-être remarqué que le mot Integer est écrit en toutes lettres et avec une majuscule. La raison à cela : une liste ne peut stocker que des objets, pas des types primitifs. De la même manière, vous devrez utiliser :
Doubleau lieu dedoublesi vous voulez stocker les décimales ;Booleanau lieu debooleansi vous voulez enregistrer des valeurs vraies/fausses ;Floatau lieu defloatsi vous insistez vraiment pour les utiliser.
La version objet des types primitifs est très utile car équipée de méthodes. N’hésitez pas à consulter la documentation officielle (notamment pour les integer : https://docs.oracle.com/javase/7/docs/api/java/lang/Integer.html).
Mais qu'en est-il des choses que nous voulons mettre dans notre liste ?
Très bonne question ! Vous ne pouvez créer qu'une liste vide en Java. Pour y mettre des éléments, vous devez les ajouter un par un, comme ceci :
List<Integer> myList = new ArrayList<Integer>();
myList.add(7);
myList.add(5); //-> [7,5]La première affectation crée une liste vide appelée
myList.Vous ajoutez ensuite un premier élément avec l'affectation
mylist.add(7). Java place automatiquement la valeur dans un objetIntegeret l'ajoute à la liste à l'index 0.Enfin, l'affectation
myList.add(5)crée une instance de la classeIntegeravec une valeur de 5 et l'ajoute à la liste à l'index 1.
Maintenant, qu'est-ce qui se passe avec ce .add() ? En Java, ajouter, modifier ou supprimer des éléments nécessite l'utilisation d'une méthode, et vous l'avez deviné, .add() en est une ! À ce stade, tout ce que vous avez besoin de savoir sur les méthodes, c'est qu'elles vous permettent de faire des choses. 😎
Pour l'interface List , il y a trois méthodes implémentées par la classe ArrayList qui sont très pratiques :
add– pour ajouter un nouvel élément à la fin d'un tableau. Ici, vous devez fournir un nouvel élément. Vous pouvez également insérer un nouvel élément à une position donnée en spécifiant l'index avant la valeur. Par exemple,myList.add(1,12)insère un entier avec la valeur 12 sur la position 1, et déplace la valeur existante sur la position 2, et ainsi de suite ;set– pour remplacer un nouvel élément sur un index spécifique. Ici, vous devez fournir un nouvel élément et l'index sur lequel vous voulez qu'une nouvelle valeur soit positionnée ;remove– pour supprimer un élément existant sur un index spécifique. Ici, vous devez fournir l'index de l'élément que vous souhaitez supprimer. Si vous n'avez plus besoin du premier élément, vous pouvez le retirer de la position 0. Cela déplacera le deuxième élément original de la position 1 à la position 0, le troisième de la position 2 à la position 1, et ainsi de suite.
Maintenant, à quoi est-ce que cela ressemble ? Voici la syntaxe Java pour ce qui précède :
List<Integer> myList = new ArrayList<Integer>(); // -> []
myList.add(7); // -> [7]
myList.add(5); //-> [7, 5]
myList.add(1,12) //-> [7, 12, 5]
myList.set(0,4); // -> [4, 12, 5]
myList.remove(1); // removed 12 -> [4, 5]Décomposons cela un petit peu, d'accord ?
Vous pouvez voir la même opération que précédemment : ajouter 7 puis 5 à la liste.
Puis vous insérez 12 à l'index 1. La valeur existante de l'index 1 est déplacée vers l'index 2.
Ensuite, avec
.set(), le premier nombre fait référence à l'index, et le second donne la valeur que vous voulez y mettre. En d'autres termes, vous demandez à votreListde modifier la valeur de l'index 0. Ceci transformera la valeur d'origine, 7, en nouvelle valeur, 4.Pour finir, avec
.remove(), vous demandez à votre liste de supprimer toute valeur trouvée à l'index 1. Cela veut dire que vous lui demandez de supprimer 12.
Ceci vous laisse avec votre liste finale contenant deux entiers : 4 et 5. Imaginez faire cela avec des tableaux de taille fixe !
Assurez le suivi du nombre d'éléments dans votre liste
Il y a une méthode très importante à utiliser avec une liste, size() , qui vous permet d'obtenir le nombre d'éléments dans une liste :
List<Integer> myList = new ArrayList<Integer>();
myList.add(1); // ->[1]
myList.add(2); //-> [1,2]
System.out.println(myList.size()); // -> 2Ceci facilite grandement le suivi de l'emplacement des éléments de votre liste.
En bonus : vous pouvez aussi obtenir ces informations avec les tableaux ! Cependant, vous devrez utiliser la propriété myArray.length , au lieu de la méthode myList.size() que vous utilisez avec une liste.
La méthode size() est largement utilisée, notamment lorsque vous avez besoin de faire une boucle sur une liste (nous avons abordé les boucles dans le chapitre 6 de la partie 1).
Utilisez une collection non ordonnée – ensembles
Un ensemble (ou « set ») est une collection d'éléments uniques non ordonnés. Vous pouvez les utiliser si vous ne vous souciez pas de l’ordre de vos éléments – comme une liste d'ingrédients pour une recette par exemple.
Déclarez des ensembles
Comme pour les listes, Java a différentes classes pour gérer les ensembles. Nous allons nous concentrer sur l'ensemble le plus communément utilisé, le HashSet .
Regardons le code Java :
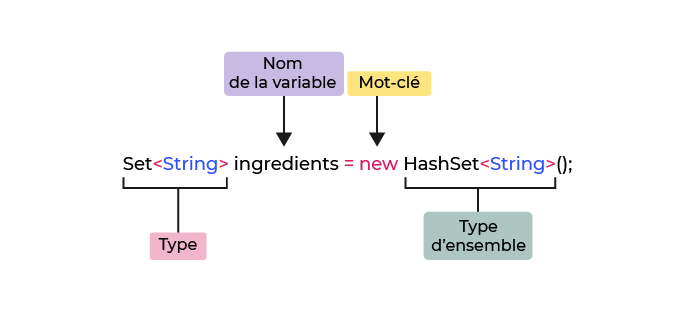
Comme vous pouvez le voir, c'est assez comparable avec le fonctionnement d'une ArrayList . Vous déclarez d'abord la variable avec l'interface Set , et vous l'initialisez avec une instance de la classe concrète HashSet .
Manipulez les éléments d'un ensemble
Voici les opérations fréquentes que vous pouvez utiliser avec les ensembles :
ajouter un nouvel élément avec une nouvelle clé ;
supprimer un élément pour une clé spécifique ;
compter le nombre d'éléments de l'ensemble.
Et l'accès à un élément ?
Comme les ensembles sont des collections non ordonnées, il n'y a pas de moyen simple de pointer des éléments particuliers – du moins pas comme ceux que vous avez vus jusqu'ici. Il y a des façons de le faire, mais vous en apprendrez davantage à ce sujet au fur et à mesure que vous approfondirez vos connaissances en programmation.
Pour ajouter un nouvel élément, utilisez add() :
Set<String> ingredients = new HashSet<String>();
ingredients.add("eggs");
ingredients.add("sugar");
ingredients.add("butter");
ingredients.add("salt");Comme les ensembles sont non ordonnés, il n'est pas nécessaire d'utiliser « append » ou d'insérer des éléments à un point spécifique. Il vous suffit d'utiliser add() !
Pour supprimer un élément, vous utilisez remove() :
Set<String> ingredients = new HashSet<>();
ingredients.add("salt"); //ajoutez du sel sur les ingrédients
ingredients.remove("salt"); //enlevez du sel des ingrédientsL'important, c'est de fournir l'élément exact à supprimer. Ici, vous vous débarrassez du « sel ».
Les ensembles, comme les listes, utilisent également la méthode size() pour obtenir le nombre d'éléments dans un ensemble :
System.out.println(ingredients.size());Consultez les dictionnaires ou "maps"
Par exemple, si vous voulez lister les noms de vos amis et leur âge respectif, les dictionnaires sont la bonne collection à utiliser :

Toutes les clés d'un dictionnaire doivent être uniques, tout comme un numéro de plaque d'immatriculation de voiture est unique.
Déclarez des dictionnaires
Pour cette section, nous utiliserons la classe la plus courante, HashMap . Voici le code pour déclarer et initialiser une instance de cette classe :
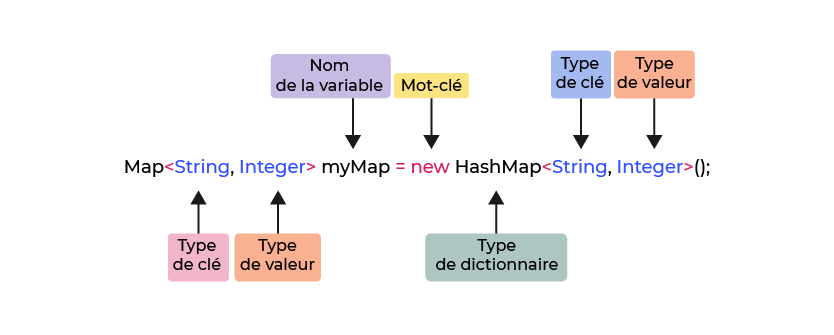
La différence principale, en comparaison avec les listes et les ensembles, réside dans le fait que vous paramétrez votre dictionnaire avec deux éléments, en utilisant la syntaxe <String, Integer> .
Stringest le type de la clé.Integerest le type de la valeur.
Pour ajouter des éléments à votre dictionnaire, utilisez la méthode myMap.put() . Entre parenthèses, indiquez d'abord la clé, puis la valeur :
// Les âges de mes amis
myMap.put("Jenny", 34);
myMap.put("Livia", 28);
myMap.put("Paul", 31);
System.out.println(myMap.get("Jenny")); // -> 34Dans la dernière ligne, nous avons demandé au programme d'afficher la valeur de la clé, Jenny. Dans ce code :
la méthode
System.out.println()affiche le résultat d'une expression fournie entre parenthèses ;l'expression réelle,
myMap.get("Jenny"), renvoie la valeur identifiée par la touche "Jenny", qui est stockée dans la variable myMap.
Lorsque vous utilisez des chaînes comme clés, n'oubliez pas que ces clés sont sensibles à la casse. Ainsi, "Jenny" et "jenny" sont (par exemple) deux clés différentes associées à deux éléments différents dans un dictionnaire. Par exemple :
myMap.put("Jenny", 34);
myMap.put("Livia", 28);
myMap.put("Paul", 31);
myMap.put("jenny", 21);
System.out.println(myMap.get("Jenny")); // -> 34
System.out.println(myMap.get("jenny")); // -> 21Pour éviter de telles situations, une astuce consiste à utiliser des constantes pour spécifier les clés une fois et les réutiliser ensuite dans tout le code :
// Définissez des clés en tant que constantes dans votre classe
private static final String KJENNY = "Jenny";
private static final String KLIVIA = "Livia";
private static final String KPAUL = "Paul";
// Utilisez des constantes en tant que keys
myMap.put(KJENNY, 34);
myMap.put(KLIVIA, 28);
myMap.put(KPAUL, 31);
// Accédez à un élément
System.out.println(myMap.get(KJENNY)); // -> 34Vous voyez que vous devez utiliser ici les mots clés private static final pour indiquer que vous avez besoin que vos chaînes soient des constantes et non des variables. Ceci est très utile, car cela vous garantit que vous garderez vos clés pour toujours, et que vous ne perdrez aucune donnée en changeant accidentellement les chaînes de clés !
Si le type le plus couramment utilisé est String , les clés en Java peuvent être de différents types, par exemple Integer :
Map<Integer, String> myMap = new HashMap<Integer, String>();
morning.put(1, "Wake up");Les dictionnaires ont en commun avec les types de variables et les tableaux simples, que leur type ne peut pas être modifié.
Toutes les clés doivent être du même type, et toutes les valeurs doivent être du même type.
myMap.put("Jenny", 34);
myMap.put("Livia", 28); // Ok
myMap.put("Paul", "Designer") // ErrorManipulez les éléments du dictionnaire
Voici les opérations fréquemment utilisées que vous pouvez effectuer avec les dictionnaires :
accéder à la valeur d'un élément par sa clé ;
ajouter un nouvel élément avec une nouvelle clé et une valeur ;
supprimer un élément pour une clé spécifique.
Imaginons un dictionnaire de noms de personnes et de leur profession, appelé « professions ».
Vous pouvez ajouter une valeur avec une méthode
put()et deux arguments : la clé et la valeur.Pour accéder à une valeur, utilisez simplement la méthode
get()avec la clé en argument.
Allons jeter un coup d'œil à cela :
professions.put("Jenny", "Business owner");
System.out.println(professions.get("Jenny")); // -> Business ownerVous pouvez également modifier un élément en réutilisant une clé existante avec la méthode
put() :
professions.put("Jenny", "Business owner");
System.out.println(professions.get("Jenny")); // -> Business owner
professions.put("Jenny", "Developer");
System.out.println(professions.get("Jenny")); // -> DeveloperEnfin, pour supprimer un élément, vous pouvez utiliser une méthode remove() avec la clé de l'élément que vous voulez supprimer :
professions.remove("Jenny");Comptez les éléments
Les dictionnaires, comme les listes et les ensembles, ont aussi la propriété size() qui permet d'obtenir le nombre d'éléments du dictionnaire :
System.out.println(professions.size());En résumé
Dans ce chapitre, vous avez appris les bases pour travailler avec des conteneurs qui stockent plusieurs éléments d'un type de données en particulier :
conteneurs de taille fixe : Arrays – les éléments d'un tableau sont indexés à partir de 0 et sont accessibles à l'aide de cet index. Le nombre d'éléments ne peut pas être modifié ;
listes ordonnées : Lists – les éléments d'une liste se comportent comme un tableau. Le nombre d'éléments peut évoluer en ajoutant et en supprimant des éléments ;
listes non ordonnées : Sets – les éléments d'un ensemble sont stockés sans ordre particulier. Vous pouvez y accéder en les énumérant ;
dictionnaires : Maps – les éléments d'un dictionnaire sont organisés par paires clé-valeur et sont accessibles à l'aide d'une clé ;
les actions les plus courantes effectuées avec les collections sont :
accéder à un élément,
ajouter un nouvel élément,
supprimer un élément,
modifier un élément,
compter tous les éléments,
parcourir tous les éléments.
La collection que vous choisissez dépend de la tâche à accomplir. Au fur et à mesure que vous progressez dans votre carrière, vous serez en mesure d'identifier le type le plus approprié à utiliser. Passons maintenant au passage de paramètres et des valeurs de retour. À tout de suite !
Gérez différents types de passage de paramètre
Depuis le début de ce cours, nous utilisons des fonctions (ou méthodes) comme System.out.println() . Dans ce chapitre, vous allez vous familiariser avec les différents composants d'une déclaration de méthode (paramètres et valeur de retour), et la différence entre un type valeur et un type référence.
Comprenez l'utilité de déclarer une méthode
Supposons que vous ayez un rectangle de 6 (de longueur) par 4 (de largeur), et que vous vouliez calculer son périmètre.
public static void displayPerimeter() {
int perimeter = 2*(4 + 6);
System.out.println(perimeter); // -> 20
}Cette méthode est correctement implémentée, mais avouons-le, tout à fait inutile car elle fournit toujours le même résultat… . De quoi limiter votre champ d’action ! Comment faire pour qu’elle calcule un périmètre avec d’autres données ?
Définissez des fonctions avec des paramètres
Pour remédier à cela, vous devez faire en sorte que votre fonction accepte des données extérieures. Pour cela, vous pouvez définir une fonction avec des paramètres.
En Java, le type du paramètre et son nom correspondant dans le cadre de la fonction font partie de la déclaration de fonction. Voilà à quoi cela ressemble :
public static void displayPerimeter(int length, int width) {
int perimeter = 2 * (length + width);
System.out.println(perimeter);
//La valeur affichée dépend de la longueur (length) et la largeur (width)
}Les paramètres sont des variables listées dans la déclaration de fonction et qui sont spécifiées à l'intérieur de parenthèses () avec le nom et le type. Vous pouvez maintenant appeler cette fonction et lui passer les valeurs que vous voulez :
displayPerimeter(10, 11); // -> 42
displayPerimeter(2, 2); // -> 8Chaque valeur est affectée à un paramètre dans l'ordre de leur définition.
Détaillons un peu cette nouvelle terminologie. Les paramètres sont les variables déclarées dans une fonction. Les valeurs passées sur cette fonction s'appellent des arguments.
Parfait, nous avons ajouté un but à notre fonction. Maintenant, que pouvons-nous faire avec le résultat ?
Souvent, le code qui a appelé la fonction a besoin d'une réponse pour effectuer son propre travail. Cette réponse peut être fournie par la valeur de retour de la fonction.
Définissez une valeur de retour
Pour définir une valeur de retour, vous devez :
Modifier la déclaration de la fonction pour indiquer qu'il est prévu qu'elle renvoie un résultat.
Terminer la fonction avec le mot clé
return.
Voici comment transformer le displayPerimeter en fonction calculatePerimeter . Ceci retournera le résultat du calcul pour qu'il puisse être utilisé par l'appelant :
public static int sum(int a, int b)
{
int calc = a + b;
return calc;
}Vous pouvez également renoncer à la variable somme, et renvoyer directement le résultat de l'expression de calcul :
public static int sum(int a, int b){
return a + b;
}Une fois votre fonction définie, vous pouvez l'utiliser autant de fois que vous le souhaitez. Voici quelques variantes :
int sumOfSmallNumbers = sum(3,7);
System.out.println(sumOfSmallNumbers); // -> 10
int sumOfLargerNumbers = sum(sumOfSmallNumbers,999);
System.out.println(sumOfLargerNumbers); // -> 1009Dans l'exemple ci-dessus, nous avons utilisé le résultat du premier calcul comme paramètre pour le suivant.
Un autre élément à comprendre et à assimiler : certaines variables stockent une valeur directement, tandis que d'autres stockent une référence. Cela a un impact sur la façon dont elles sont envoyées comme arguments à une fonction.
Différenciez les type valeur et les type référence
Vous avez appris qu'il existe des types de variables simples (comme les nombres ou les chaînes) ou plus complexes (comme les classes). Chacun de ces types est classé comme un type valeur ou un type référence.
Commençons par les types valeur.
Types valeur
Prenons par exemple les nombres entiers. Si vous créez un int et que vous lui donnez une valeur, puis que vous affectez cette variable à une seconde variable int , la valeur de la première sera copiée dans la seconde :
// Déclarez la variable "a" en tant que "int" et l'initialiser avec une valeur de 10
int a = 10;
// Déclarez la variable "b" en tant que "int" et l'initialiser avec une copie de la valeur de "a"
int b = a;Puisque int est un type valeur, une copie de la valeur de a est assignée à b . Les deux valeurs sont indépendantes. Cela signifie que si vous modifiez ultérieurement la valeur de a, la valeur de b ne sera pas modifiée.
System.out.println(a); // -> 10
System.out.println(b); // -> 10
a = 15;
System.out.println(a); // -> 15
System.out.println(b); // -> 10C'est assez simple. Viennent ensuite les types référence.
Types référence
Dans cette section, nous allons travailler avec des classes. Lorsque vous créez une variable et lui affectez une instance de classe, l'objet est créé, mais la variable elle-même contient une référence à cet objet : l'emplacement où il est stocké dans la mémoire. Ensuite, lorsque vous affectez la valeur de cette variable à une autre variable, l'objet lui-même ne sera pas copié, et la nouvelle variable contiendra une référence à cet objet : la même adresse.
En voici un exemple :
public class Car {
String color = "red";
}
Car car = new Car();
Car carToPaint = car;Si vous voulez peindre la voiture qui est accessible par la deuxième variable, la première variable sera également affectée car les deux pointent exactement vers la même instance de la classe « car » (voiture) :
public class Car {
String color = "red"
}
Car car = new Car();
Car carToPaint = car;
System.out.println(car.color); // -> red
System.out.println(carToPaint.color); // -> red
carToPaint.color = "yellow";
System.out.println(car.color); // -> yellow
System.out.println(carToPaint.color); // -> yellowVous voyez la différence ? ⚡️ C'est très utile, car cela permet d'économiser beaucoup de mémoire si vous devez faire passer le même objet sur tout votre programme. Cependant, cela peut également être dangereux, car changer un objet dans une partie d'un programme affecte toutes les autres parties du programme qui utilisent le même objet.
class Car {
String color = "red";
}
public void paint( Car car, String color) {
car.color = color;
}
Car car = new Car();
System.out.println(car.color); // -> red
paint(car, "green");
System.out.println(car.color); // -> greenMais les paramètres des fonctions ne seraient-ils pas des constantes en Java ?
En effet, en Java, les paramètres d'une fonction sont des constantes et ne peuvent pas être modifiés, ce qui signifie que vous ne pouvez pas affecter une nouvelle valeur à l'ensemble du nouvel objet (ou une référence à un objet). Mais vous pouvez tout à fait modifier les attributs de cet objet. C'est ce que nous avons fait dans l'exemple ci-dessus.
Lors des appels de méthode, les arguments sont toujours passés par valeur. Dans le cas des types primitifs (
int,char,byte, etc.), c'est la valeur de l'argument qui est recopiée dans le paramètre de la méthode.
int cote = 5;
agrandirCote(cote); // Cette méthode ajoute 2cm au côté qui lui a été passé en paramètreDans l’exemple ci-dessus, la variable cote aura toujours la valeur 5 en dehors de la fonction agrandirCote(int leCoteAagrandir) .
Dans le cas des types « objet », c'est la valeur de la variable (la référence à l'objet), qui est transmise à la méthode.
Integer cote = 5;
agrandirCote(cote); // Cette méthode ajoute 2cm au côté qui lui a été passé en paramètreCette fois-ci, une fois la méthode agrandirCote(Integer leCoteAagrandir) appelée avec la variable coté, cette variable aura pour valeur 7 en dehors de la méthode (une fois la méthode exécutée).
En résumé
Les fonctions peuvent avoir des paramètres et des valeurs de retour (return).
Une valeur de retour est le résultat de l'exécution de la fonction. Elle peut être renvoyée au bloc de code qui a appelé la fonction, et être utilisée si besoin est.
Les paramètres sont les entrées d'une fonction nécessaires à l'exécution et à l'obtention d'un résultat.
Les paramètres sont des variables définies par leur nom et par leur type. Ces paramètres sont spécifiés dans la déclaration de la fonction.
Lorsque vous appelez une fonction, vous passez des valeurs à ces variables. Ces valeurs sont appelées arguments.
Utilisez quelques principes de programmation avancés en Java
Entrez dans les détails grâce à la récursivité

Comprenez le principe de récursivité
Dans ce chapitre, vous allez apprendre l'un des concepts fondamentaux de la programmation : la récursivité.
Souvenez-vous des mathématiques factorielles
Commençons par regarder la récursivité dans le contexte des mathématiques factorielles. Vous vous souvenez de ce qu'est une factorielle ?
5! = 5 x 4 x 3 x 2 x 1
4! = 4 x 3 x 2 x 1
3! = 3 x 2 x 1
En fait, la façon dont fonctionne une factorielle nous donnera un bon exemple de la récursivité dans Java. Une autre façon plus abstraite de l'écrire serait :
N! = N x (N-1)!
En utilisant des chiffres, cela donne :
5! = 5 x (5-1)! , c'est-à-dire 5! = 5 x (4)! , et au final 5! = 5 x 4! .
Mais, suivant cette formule, nous pouvons également écrire 4! comme 4 x (4-1)! , ce qui nous donne 4 x 3! . Nous pouvons ainsi revenir à 5! = 5 x 4! pour obtenir : 5! = 5 x (4 x 3!) .
Une minute ! En regardant notre nouvelle version, 3! peut également utiliser cette formule ! Ce qui va finalement nous donner : 5! = 5 x 4 x (3 x 2!) . Nous pouvons recommencer avec 2! .
Même si vous n'êtes pas très doué en maths, vous pouvez voir ici que la formule factorielle est utilisée à plusieurs reprises.
Appliquez le principe en langage Java
Du point de vue du code, vous pouvez créer une fonction qui s'exécute de façon répétée, comme ici, jusqu'à ce que vous ayez une réponse complète.
Comment écrire une factorielle en langage Java en utilisant des opérateurs ?
Essayons :
// définissez des classes
class RecursionInJava {
public static int factorial(int n) {
n = n * factorial (n-1);
}
}Attention, le code ci-dessus ne fonctionne pas ! Vous pouvez tester pour voir. C'est un exemple qu'on va améliorer juste après !
Si vous regardez attentivement la ligne n = n * factorial(n-1) , vous constaterez que la méthode factorielle est appelée à l'intérieur d'elle-même. C'est ce qu'on appelle la récursivité, parce que la méthode fonctionne en continu en s'appelant elle-même.
Vous vous souvenez des instructions conditionnelles comme if/else ? Elles permettent à une instruction de s'appliquer à l'infini jusqu'à l'arrêt de la méthode pour une raison donnée. Pourquoi voudriez-vous arrêter cette méthode ? Lorsque vous effectuez une équation factorielle, elle se termine à 1. En transposant à la programmation, vous devez créer une instruction conditionnelle qui mettra fin à la récursion quand n sera égal à 1.
Ceci fera deux choses :
Cela arrêtera la méthode factorielle quand n sera égal à 1.
Si le numéro d'origine est 1, l'instruction renvoie simplement 1.
Voyons à quoi ça ressemble :
// Définissez des classes
class RecursionInJava {
// La méthode corrigée
public static int factorial(int n) {
if (n == 1) return 1;
else return n * factorial (n-1);
}
}Revenons maintenant à l'exemple du livre. Si vous voulez compter les livres dans chaque catégorie, chaque sous-catégorie, et ainsi de suite, vous devez vous assurer que vous prenez en compte toutes les différentes couches. Puis, une fois terminée, cette fonction s'appellera elle-même, mais cette fois en fonctionnant avec les sous-catégories de l'une des catégories d'origine. Cette itération ira plus loin et s'appellera elle-même à nouveau pour traiter des sous-catégories. Et ainsi de suite, jusqu'à ce qu'il n'y ait plus de sous-catégories. De cette façon, vous pouvez aller jusqu'au tout dernier sous-niveau de chaque catégorie d'origine. Et si une catégorie n'a pas de sous-catégories, votre fonction reviendra à votre point de départ.
Voici à quoi ressemble le code qui implémente cela en Java :
class BookStore {
public static Categories categories;
// Définissez une fonction récursive
public static int countBooks(Categories categories) {
int c = 0;
for (Category category : categories) {
c += category.numberOfBooks;
c += countBooks(category.subCategories);
}
return c;
}
public static void main(String[] args) {
// Appelez cette fonction récursive
Category c1 = new Category();
c1.numberOfBooks = 3;
Category c2 = new Category();
c2.numberOfBooks = 2;
Category c3 = new Category();
c3.numberOfBooks = 10;
Categories subc1 = new Categories();
subc1.add(c3);
c1.subCategories = subc1;
categories = new Categories();
categories.add(c1);
categories.add(c2);
int numberOfBooks = countBooks(BookStore.categories);
System.out.println("The bookstore has " + numberOfBooks + " books");
}
}
---------------
import java.util.ArrayList;
class Categories extends ArrayList<Category> {
}
---------------
public class Category {
public int numberOfBooks;
public Categories subCategories = new Categories();
}Très efficace, n'est-ce pas ?
En termes techniques, la récursion est une action qui s'initialise à l'intérieur d'elle-même. Elle continue de descendre couche après couche, jusqu'à ce qu'une condition soit remplie, puis remonte jusqu'à la première couche.
La récursivité est l'un des concepts fondamentaux de tout langage de programmation !
En résumé
La récursivité est une action qui s'initialise à l'intérieur d'elle-même.
Les méthodes récursives servent à passer des structures en couches.
Passons au chapitre suivant pour apprendre comment les erreurs et les exceptions permettent de gérer les comportements inattendus.
Gérez les comportements inattendus
Gérez les erreurs
Les erreurs sont des problèmes de code. Elles peuvent aller de fautes de frappe à l'utilisation incorrecte de variables ou de fonctions qui peuvent être repérées immédiatement, en passant par des erreurs qui surviennent pendant l'exécution du programme. Elles dépendent souvent de la séquence d'exécution et des résultats du code précédemment exécuté.
Examinons comment créer et utiliser une application. Vous l'écrivez dans un langage de programmation. Ce code est traduit en code machine, et il est ensuite exécuté au fur et à mesure que vous utilisez une application.
Voici les deux phases de ce processus :
compilation (ou interprétation dans certaines langues) – c'est là que le code est vérifié et traduit en code machine. Le résultat du processus de compilation est un fichier qui est prêt à être exécuté et appelé – exécutable ;
exécution – exécuter l'application – exécuter le fichier exécutable !
Chacune des phases peut avoir son propre ensemble d'erreurs.
Repérez et corrigez les erreurs de compilation
Des erreurs de compilation peuvent être détectées par le compilateur Java (javac), pendant le processus de traduction de votre code Java lisible par un être humain, en code byte lisible par une machine. Ces erreurs peuvent être syntaxiques (fautes d'orthographe) ou sémantiques, telles que l'utilisation de mots interdits, de code non interprétable, de types incorrects, etc.
Si vous utilisez un environnement de développement intégré (IDE) comme Eclipse ou IntelliJ IDE, vous serez averti des erreurs en direct lorsque vous taperez votre code. Les lignes de code qui correspondent à des erreurs de compilation sont surlignées en rouge. Ce sont des erreurs dites « faciles », car elles peuvent (et doivent) être corrigées sur place. L'application ne peut pas être compilée tant qu'il y a des erreurs de compilation. Mais elles sont faciles à réparer, et vous pouvez voir exactement ce qui ne va pas.
Les erreurs d'exécution, quant à elles, peuvent être difficiles à corriger.
Gérez les erreurs d'exécution
Les erreurs d'exécution surviennent pendant le processus d'exécution, après le lancement de l'application. Elles n'apparaissent que pendant le processus d'exécution, et il n'y a aucun moyen de les détecter pendant la compilation.
Ce type d'erreur est typiquement lié à la logique du code, comme l'accès à des données qui n'existent pas ou qui existent dans un format différent, ou à l'exécution d'une action non prise en charge, etc.
Par exemple, si vous essayez d'accéder à un élément d'une liste dont l'index est supérieur à la longueur de cette liste, il y a une erreur de logique : vous pensiez que la liste serait plus longue.
Un exemple d'erreur de logique métier pourrait être que dans une application financière, vous avez inversé la signification des termes crédit et débit (ce qui n’est pas du tout OK). Cependant, l'application parviendra quand même à fonctionner dans cette situation. Elle va simplement produire tout le contraire du résultat que vous attendez ! Alors, ne les mélangez pas !
En général, une erreur logique a pour principale conséquence un plantage de l'application.
Certaines de ces erreurs peuvent facilement être reproduites au fur et à mesure qu'elles surviennent. D'autres ne se produisent qu'occasionnellement. Elles sont plus difficiles à résoudre car elles sont généralement plus difficiles à reproduire. Les erreurs occasionnelles sont habituellement liées à des conditions particulières du code. Voici un exemple de ce genre d'erreur ninja dans la structure du code :
if(weekDay) {
//exécuter le code sans erreur
}
else {
//exécuter le code avec des erreurs
}Dans l'exemple ci-dessus, si vous travaillez sur votre projet uniquement du lundi au vendredi et que vous obtenez tous les plantages signalés pendant le week-end, il ne sera pas évident au début de savoir pourquoi votre application plante.
Alors, qu'est-ce que vous pouvez y faire ?
Dans certains cas, vous pouvez déboguer votre programme et détecter ces points faibles.
Vous pouvez généralement utiliser deux stratégies :
Recherche d'erreurs à l'aide de conditions.
Tirer parti du mécanisme des exceptions.
Revoyons chaque stratégie avec un exemple courant : la fameuse erreur de la division par zéro.
Recherchez les erreurs
Créez d'abord une classe utilitaire dans un package exceptions , appelé SimpleMaths , qui fournit une méthode calculateAverage qui calcule la moyenne d'une liste de valeurs entières.
Sinon, vous pourrez vous entraîner dans l'exercice interactif à la fin de ce chapitre.
package exceptions;
import java.util.List;
public class SimpleMaths {
/** calculez la valeur moyenne d'une liste d'entiers
*
* @param listOfIntegers une liste contenant des nombres entiers
* @return la moyenne de la liste
*/
public static int calculateAverage(List<Integer> listOfIntegers) {
int average=0;
for (int value: listOfIntegers) {
average+=value;
}
average/=listOfIntegers.size();
return average;
}
}Définissez ensuite un programme dans une classe nommée TemperatureAverage à l'intérieur du même paquet d'exceptions qui fait usage de cette fonctionnalité. Ce programme reçoit les valeurs de température comme arguments en ligne de commande. Il appelle la fonction calculateAverage et affiche le résultat.
package exceptions;
import java.util.ArrayList;
import java.util.List;
public class TemperatureAverage {
/** affiche la température moyenne à partir des valeurs fournies comme arguments en ligne de commande
*
* @param args liste de températures séparées par des espaces
*/
public static void main(String[] args) {
List<Integer> recordedTemperaturesInDegreesCelcius = new ArrayList<Integer>();
// remplissez la liste à partir des valeurs fournies comme arguments en ligne de commande
for (String stringRepresentationOfTemperature : args) {
int temperature = Integer.parseInt(stringRepresentationOfTemperature);
recordedTemperaturesInDegreesCelcius.add(temperature);
}
// calculez et affichez la température moyenne
Integer averageTemperature = SimpleMaths.calculateAverage(recordedTemperaturesInDegreesCelcius);
System.out.println("The average temperature is " + averageTemperature);
}
}Dans ce code, créez d'abord une liste vide, puis itérez sur le tableau args contenant les arguments de ligne de commande fournis. Puisque chaque argument est fourni sous la forme d'une String , convertissez-le en Integer à l'aide de Integer.parseInt avant de l'ajouter à la liste. Une fois la liste complétée, appelez la fonction calculateAverage de la classe SimpleMaths , affectez le résultat à la variable averageTempérature et imprimez sa valeur.
Compilons et exécutons ce code avec différents arguments :
$ javac exceptions/*.java $ java exceptions.TemperatureAverage 4 7 9 16 The average temperature is 9 $ java exceptions.TemperatureAverage 4 7 The average temperature is 5 $ java exceptions.TemperatureAverage Exception in thread "main" java.lang.ArithmeticException: / by zero at exceptions.SimpleMaths.calculateAverage(SimpleMaths.java:17) at exceptions.TemperatureAverage.main(TemperatureAverage.java:23)
Sans surprise, vous avez des problèmes si vous ne fournissez aucun argument sur la ligne de commande, puisque vous ne pouvez pas diviser par zéro. Pour éviter cette erreur, ajoutez un contrôle dans la méthode calculateAverage :
if (listOfIntegers.size()==0){
return 0;
}Toutefois, cette stratégie produirait un résultat très trompeur : 0 n'est pas un résultat valide. Nous n'avons même pas effectué la division ! Nous pouvons, cependant, régler la fonction main pour éviter d'appeler la fonction avec une liste vide :
package exceptions;
import java.util.ArrayList;
import java.util.List;
public class TemperatureAverageWithCheckForEmptyList {
/** affichez la température moyenne à partir des valeurs fournies comme arguments en ligne de commande
*
* @param args liste de températures séparées par des espaces
*/
public static void main(String[] args) {
List<Integer> recordedTemperaturesInDegreesCelcius = new ArrayList<Integer>();
// remplissez la liste à partir des valeurs fournies comme arguments en ligne de commande
for (String stringRepresentationOfTemperature : args) {
int temperature = Integer.parseInt(stringRepresentationOfTemperature);
recordedTemperaturesInDegreesCelcius.add(temperature);
}
// Protection contre la liste vide
if (recordedTemperaturesInDegreesCelcius.size() == 0) {
System.out.println("Cannot calculate average of empty list!");
} else {
// calculez et affichez la température moyenne
int averageTemperature =
SimpleMaths.calculateAverage(recordedTemperaturesInDegreesCelcius);
System.out.println("The average temperature is " + averageTemperature);
}
}
}Voyons cela en action :
$ javac exceptions/*.java $ java exceptions.TemperatureAverageWithCheckForEmptyList Cannot calculate average of empty list!
Génial ! Vérifions avec d'autres arguments :
$ java exceptions.TemperatureAverageWithCheckForEmptyList 8 6 9 The average temperature is 7
$ java exceptions.TemperatureAverageWithCheckForEmptyList 8 6 eight2 Exception in thread "main" java.lang.NumberFormatException: For input string: "eight" at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.j ava:65) at java.base/java.lang.Integer.parseInt(Integer.java:652) at java.base/java.lang.Integer.parseInt(Integer.java:770) at exceptions.TemperatureAverageWithCheckForEmptyList.main(TemperatureAverageWithCh eckForEmptyList.java:18)
Il semble qu'il y ait un autre problème : notre méthode parseInt n'accepte pas "eight" comme entrée, et lance une exception NumberFormatException qui fait planter le programme.
Intéressant ! Nous obtenons ce qu'on appelle un suivi de la pile : un message que Java imprime lorsqu'un programme plante. Il nous dit même ce qui s'est passé : java.lang.NumberFormatException: For input string: "eight." .
Donc, si Java est capable d'imprimer ce message, pourrait-il empêcher le crash en tant que tel ?
Bien sûr que oui ! C'est à cela que sert le mécanisme de gestion des exceptions. 🙂
Gérez les exceptions
Le mécanisme de gestion des exceptions est le mécanisme de gestion des erreurs inclus par défaut dans Java. Il a pour fonction de faire un throw avec un événement qui interrompt le déroulement normal de l'exécution en cas de problème. Si cet événement est détecté, le problème peut être résolu. Sinon, le programme plante avec une trace de pile qui décrit ce qui s'est passé.
Pour cela, il existe un modèle de code général, try/catch (essayer/capturer). Cela signifie que vous demandez à faire quelque chose – exécuter un bloc de code, ou plutôt, try (essayer) de le faire. Si une erreur se produit, vous la capturerez : catch .
Vous pouvez gérer l'erreur (ou les erreurs) dans la partie catch. Cela peut être aussi simple que de ne rien faire ou de réessayer (si votre logique métier le permet). En capturant une erreur (même si vous n'avez rien fait), vous avez empêché l'application de planter.
Voici à quoi ressemble cette construction en Java :
try {
// un peu de code
// une fonction à essayer pouvant générer une erreur
// encore du code
}
catch (ExceptionName e) {
// code à exécuter au cas où l'essai ne fonctionnerait pas et qu'une erreur se produirait
}Que se passe-t-il si on essaie avec try ?
En cas de problème à l'intérieur d'une méthode pendant son exécution, une erreur est générée, throw . Cette exception remonte jusqu'à la chaîne d'appels de méthode jusqu'à ce qu'elle soit capturée, catch . Si aucune instruction d'interception n'est fournie, le programme finit par planter.
Corrigeons notre programme pour gérer nos sources d'erreurs connues :
package exceptions;
import java.util.ArrayList;
import java.util.List;
public class TemperatureAverageWithExceptionHandling {
/** affichez la température moyenne à partir des valeurs fournies comme arguments en ligne de commande
*
* @param args liste de températures séparées par des espaces
*/
public static void main(String[] args) {
try {
List<Integer> recordedTemperaturesInDegreesCelcius = new ArrayList<Integer>();
// remplissez la liste à partir des valeurs fournies comme arguments en ligne de commande
for (String stringRepresentationOfTemperature : args) {
int temperature = Integer.parseInt(stringRepresentationOfTemperature);
recordedTemperaturesInDegreesCelcius.add(temperature);
}
// calculez et affichez la température moyenne
int averageTemperature =
SimpleMaths.calculateAverage(recordedTemperaturesInDegreesCelcius);
System.out.println("The average temperature is " + averageTemperature);
} catch (NumberFormatException e) {
System.out.println("All arguments should be provided as numbers");
System.exit(-1);
} catch (ArithmeticException e) {
System.out.println("At least one temperature should be provided");
System.exit(-1);
}
}
}Ce code est divisé en deux parties :
le flux normal, entre
try{et}, est détecté : il se compose des instructions à exécuter tant qu'aucune erreur ne se produit ;Un ensemble d'instructions
catch(Exception e). Si une erreur se produit et que l'exception qui est lancée correspond au type d'exception défini dans une instructioncatch, le bloc qui correspond à cette instruction catch est exécuté. Si aucune instruction de capture ne correspond, le programme plante et affiche la trace de la pile.
Ce mécanisme permet de séparer le flux normal d'un programme de la partie de traitement des erreurs. Il permet même de gérer une erreur de méthode dans la méthode appelante. Dans notre exemple, l'exception ArithmeticException est générée depuis la méthode calculateAverage , mais interceptée dans la méthode main .
En résumé
La compilation est le processus de traduction du code d'un langage de programmation en code machine. Les erreurs de compilation sont faciles à découvrir et doivent être résolues pour terminer le processus de compilation.
L'exécution est le processus d'utilisation ou d'exécution de l'application. Les erreurs d'exécution sont plus difficiles à découvrir et provoquent le crash d'une application.
En Java, les erreurs d'exécution génèrent des exceptions.
Les exceptions sont gérées à l'aide d'une instruction try/catch :
Tryindique qu'une fonction peut lancer une exception ;Catchindique quel code exécuter si une exception est générée (throw).
Dans le chapitre suivant, nous traiterons de la lecture et de l’écriture de données dans un fichier où nous verrons que la gestion des exceptions est importante.
Manipulez les fichiers
Jusqu’à maintenant, nos programmes sont isolés et n'interagissent pas avec d'autres composants (fichiers, programme, etc.). Dans ce chapitre, nous verrons comment donner un autre pouvoir à nos programmes : manipuler des fichiers.
Lisez des fichiers
En Java, il peut parfois être utile de lire le contenu d’un fichier pour récupérer des données. Qu’il s’agisse d’un fichier que nous avons déjà sauvegardé ou d’un autre fichier, il est possible de le lire, ligne par ligne. Voyons ça avec un exemple :
public class Main1 {
public static void main(String[] args) {
try {
// Création d'un fileReader pour lire le fichier
FileReader fileReader = new FileReader("/path/to/the/file");
// Création d'un bufferedReader qui utilise le fileReader
BufferedReader reader = new BufferedReader(fileReader);
// une fonction à essayer pouvant générer une erreur
String line = reader.readLine();
while (line != null) {
// affichage de la ligne
System.out.println(line);
// lecture de la prochaine ligne
line = reader.readLine();
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}Ici, nous ne faisons qu’afficher chaque ligne de notre fichier, mais intéressons-nous aux différents objets de notre code :
Le try catch qui nous permet de gérer les exceptions.
Un FileReader qui va lire le fichier au chemin qui lui est donné en argument.
Un BufferedReader qui va utiliser le fileReader pour lire le fichier ligne par ligne.
Une condition while qui nous permet de répéter le code tant que nous ne sommes pas à la fin du fichier.
Écrivez dans des fichiers
Nous venons de voir comment lire un fichier, maintenant voyons comment écrire dans un fichier. Il peut être intéressant pour nos programmes Java de pouvoir écrire dans un fichier pour plusieurs raisons, comme par exemple pour traiter des fichiers de données (XML, CSV, etc.). Il est courant d’utiliser un programme informatique pour traiter ou modifier de gros volumes de données, et Java peut tout à fait s’en occuper 💪.
Notre programme pourrait aussi créer et écrire dans un fichier uniquement destiné à être lu plus tard, ce qui revient à sauvegarder l’état du programme. Prenons un exemple pour enregistrer les paramètres d’un programme Java :
public class Main2 {
public static void main(String[] args) {
try {
// Création d'un fileWriter pour écrire dans un fichier
FileWriter fileWriter = new FileWriter("/path/to/the/file", false);
// Création d'un bufferedWriter qui utilise le fileWriter
BufferedWriter writer = new BufferedWriter(fileWriter);
// ajout d'un texte à notre fichier
writer.write("preferenceNewsletter=false");
// Retour à la ligne
writer.newLine();
writer.write("preferenceColor=#425384");
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}Dans notre exemple, on enregistre les textes "preferenceNewsletter=false" et "preferenceColor=#425384" dans notre fichier. On utilise la méthode newLine du BufferedWriter pour changer de ligne entre les 2 textes.
Pour écrire notre texte, nous avons donc dû utiliser plusieurs objets qui fonctionnent ensemble :
le “try catch” qui nous permet de gérer les exceptions ;
un “FileWriter” qui va préparer le fichier au chemin qui lui est donné en argument ;
un “BufferedWriter” qui va utiliser le “fileWrite” pour écrire dans le fichier.
En résumé
La lecture du contenu des fichiers se fait grâce à un ”BufferedReader“ qui va lire le fichier ligne par ligne.
L’écriture de texte dans un fichier se fait avec un “BufferedWriter“.
Lorsqu’on manipule des fichiers, il faut toujours gérer les exceptions car les fichiers sont des éléments extérieurs à notre programme, et les problèmes d’accès ou de droits sont fréquents.
Écrivez votre premier code Lambda
Nous avons vu dans les parties précédentes de ce cours comment instancier des variables et obtenir ainsi ce qu’on appelle une référence. Il peut s'agir :
d'une référence vers un type primitif, par exemple
int cpt = 0;ou d'une référence vers une instance d’objet, par exemple
FigureGeo myFigureGeo = new FigureGeo().
Dans ce chapitre, nous allons voir qu'une référence peut également porter sur un bloc de code !
Écrivez une fonction Lambda
Depuis Java 8, il est désormais possible d’obtenir une référence vers une méthode. C’est ce qu’on appelle une “closure” en anglais, et en Java, c’est la fonctionnalité Lambda qui en est l’expression. Les Lambda sont une nouvelle manière d’écrire du code compact (et plus lisible).
Au-delà d'un code plus compact, un des des grands intérêts des expressions Lambda est d’avoir une alternative aux appels de méthodes à partir de classes anonymes. Sans entrer dans les détails, avant les Lambda, on utilisait souvent les classes anonymes dans le seul but de redéfinir et d’appeler la méthode d’une classe à un endroit bien précis de notre code.
Prenons un exemple :
public class MaClassPrincipale {
public static void main(String... args) {
Bird bird = new Bird() {
@Override //sert simplement à indiquer que nous redéfinissons la méthode fly()
void fly() {
System.out.println("Vole grâce à ses deux ailes...");
}
}; // Attention à ne pas oublier le “;”
// À ce moment (et uniquement à ce moment), nous redéfinissons la manière de voler d’un oiseau. Ensuite nous l'utilisons.
bird.fly(); // Va afficher "Vole grâce à ses deux ailes..."
// À noter qu’il est toujours possible de passer des paramètres à une méthode d’une classe anonyme
}
}Bien entendu, la classe Bird pourrait avoir bien d’autres méthodes qu’on serait tenté d’utiliser de la même manière. Mais croyez-moi, ça devient vite ingérable, et on fait l’impasse sur la force de la POO. 😉
Pour arriver aux "closures" et utiliser les Lambda, Java 8 a introduit ce qu’on appelle les interfaces fonctionnelles. Celles-ci n’ont (ou n’auront) qu’une seule méthode abstraite. À l’exécution du code Lambda, Java fait en sorte de déterminer la méthode à appeler.
Ayez à l’esprit qu’une expression Lambda est en quelque sorte la redéfinition d'une méthode d'une interface fonctionnelle, sans avoir à faire une classe anonyme.
Allez, voyons à quoi ressemble un code Lambda (une redéfinition de l’unique méthode d’une interface fonctionnelle) :
() -> action ou
(parametre, ...) -> une action ou
(parametre, ...) -> {traitement, retourner quelque chose} .
Voici un premier exemple :
//Votre interface “fonctionnelle”
public interface Etudiant {
void donnerNom();
}
//Utilisation
public static void main(String[] args) {
Etudiant et = () -> {System.out.println("Toto");};
et.donnerNom();//Affichera Toto
}Un autre exemple : nous faisons évoluer l’unique méthode de l’interface fonctionnelle.
public interface EtudiantEvolue {
void donnerNom(String nom);
}
//Utilisation
public static void main(String[] args) {
EtudiantEvolue et = (leNomAafficher) -> {System.out.println(“Je me nomme “ + leNomAafficher);};
et.donnerNom("Jean");//Cette fois, on affichera Jean
}Une expression Lambda, c'est toujours : <liste de paramètres> -> <le corps de la fonction> . Détaillons chaque élément :
<liste de paramètres>: indique les paramètres en entrée de l'unique méthode de l'interface fonctionnelle. Ils seront saisis entre()et il n'est pas obligatoire d'indiquer leurs types ;->: c'est le marqueur de l'expression Lambda. Il sépare la liste des paramètres du corps de la fonction ;<le corps de la fonction>: entre{}ou pas, s'il n'y a qu'une expression courte.
Le corps d’une expression Lambda
Le corps d'une expression Lambda est défini à droite de l'opérateur -> . Il peut être :
une expression unique ;
un bloc de code composé d'une ou plusieurs instructions entourées par des accolades.
Le corps de l'expression doit respecter certaines règles :
il peut n'avoir aucune, une seule ou plusieurs instructions ;
lorsqu'il ne contient qu'une seule instruction, les accolades ne sont pas obligatoires, et la valeur de retour est celle de l'instruction si elle en possède une ;
lorsqu'il y a plusieurs instructions, elles doivent obligatoirement être entourées d'accolades ;
la valeur de retour est celle de la dernière expression, ou
voidsi rien n'est retourné.
Si le corps est simplement une expression, celle-ci est évaluée, et le résultat de cette évaluation est renvoyé s'il y en a un.
En résumé
Une expression Lambda est une référence vers un bloc de code.
Une interface fonctionnelle est une interface qui n’a qu’une seule méthode abstraite.
On peut utiliser une expression Lambda pour implémenter une interface fonctionnelle sans déclarer de classe abstraite.
Téléchargez la fiche résumé du cours
C'est bientôt la fin de ce cours, mais avant, je vous propose un dernier quiz pour tester vos connaissances. C'est parti !
