Comment interpréter une mesure de performance ? Si mon modèle atteint une AUC de 0.85 sur mon jeu de test, comment l’interpréter ? Est-ce que ça veut dire que le modèle a bien appris, ou pas ?
La performance d'un modèle dépend du jeu de données
Le théorème du "no free lunch" ("il n'y a pas de déjeuner gratuit", c'est-à-dire qu'on ne peut pas avoir le beurre et l'argent du beurre), nous dit qu'aucun algorithme de machine learning ne fonctionne bien sur tous les jeux de données.
Comme nous l'avons vu précédemment, les données que nous observons ne suffisent pas à déterminer le modèle. Nous devons rajouter des hypothèses, par exemple le fait que les classes peuvent être séparées par des hyperplans, pour pouvoir construire un modèle. Ces hypothèses et leur validité dépendent du problème étudié.
Prenons l'exemple suivant : imaginons que nous cherchions à classifier des voitures en deux classes : citadines ou sportives. Nos voitures sont représentées par leurs dimensions et leur consommation. A priori, deux voitures de la même classe vont avoir des tailles et consommations similaires, et nous allons être capables de construire un bon modèle.
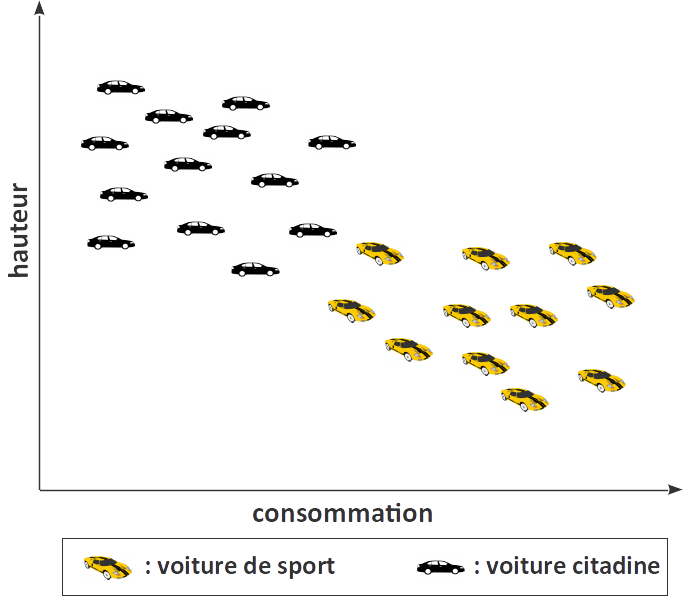
Imaginons maintenant que nous cherchions à utiliser les mêmes descripteurs et le même algorithme pour un autre problème de classification binaire : séparer les voitures d'occasion des voitures neuves.
C'est a priori beaucoup plus difficile. Nous vouons alors beaucoup d'efforts à développer un modèle compliqué pour notre problème, et mesurons un taux d'erreur très faible sur notre jeu de test. Mais il se pourrait que dans nos données, toutes les voitures d'occasion soient des citadines et toutes les voitures neuves des voitures de sport ! Dans ce cas, nous pourrions obtenir le même taux d'erreur avec un algorithme beaucoup plus simple…

Pour mieux comprendre la difficulté de notre problème, et évaluer les performances que l'on peut facilement atteindre, on peut utiliser des approches naïves : des approches très simples mais qui s'appuient néanmoins sur le jeu de données pour construire un modèle. Ces méthodes ne permettent pas réellement de faire de l'apprentissage, mais servent de point de comparaison pour évaluer nos modèles.
Approches naïves pour des problèmes de classification (binaire)
Voici quelques approches naïves pour des problèmes de classification. Elles sont implémentées dans la classe DummyClassifier du module dummy de scikit-learn.
Prédire la même classe pour tous les échantillons : la classe la plus fréquente dans le jeu d'entraînement. Cette approche naïve nous permet d’évaluer si le modèle que nous proposons a appris « plus » que simplement quelle est la classe la plus fréquente. C’est particulièrement intéressant si une des classes est beaucoup plus fréquente que les autres. Pensez que pour un problème de classification binaire sur des données contenant 90% d’échantillons positifs, un classifieur qui retourne systématiquement « positif » aura une accuracy de 90%.
Prédire une classe aléatoirement, dans les mêmes proportions que dans le jeu d'entraînement. Cette approche naïve nous permet d’évaluer si les performances que nous observons ne seraient pas simplement dûes aux proportions relatives des classes.
Retourner aléatoirement des scores selon une distribution uniforme, puis leur appliquer un seuil pour obtenir une prédiction binaire. Cette méthode est recommandée quand on cherche à interpréter une courbe ROC ou une AUROC, elles-mêmes construites à partir de classifieurs qui retournent des scores.
Résumé
Les performances d'un modèle dépendent du jeu de données.
Les approches naïves sont des approches simples qui n'apprennent pas vraiment mais servent de point de comparaison pour évaluer nos modèles.
Pour un problème de classification, on peut utiliser une des approches naïves suivantes :
Retourner toujours la même classe ;
Retourner une classe aléatoire ;
Retourner un score aléatoire, puis utiliser un seuil.
