Elasticsearch est une base de données NoSQL dont la particularité est de pouvoir indexer des documents fortement orientés textes. On pourrait le comparer à un moteur de recherche, mais que vous pourriez paramétrer pour qu’il colle exactement à vos besoins de recherche. Elasticsearch, c’est donc un moteur de recherche capable de stocker une grande quantité de documents et que l’on peut interroger en temps réel. De plus, son langage de requête apporte des possibilités d’interrogation intéressantes que l’on pourra exploiter pour extraire des statistiques en temps réel, mais gardons cela pour le dernier chapitre.
![]()
Tout d’abord, intéressons-nous aux données que l’on peut insérer dans Elasticsearch. Nous allons, sans surprise, utiliser des documents JSON avec du texte. Mais on pourra également exploiter les informations provenant des listes et des documents imbriqués. Le document ci-dessous illustre notre besoin, avec des descriptions de films connus :
{
"title" : "Star Wars",
"directors" : ["George Lucas"],
"release_date" : "1977-05-25T00:00:00Z",
"rating" : 8.7,
"genres" : ["Action","Adventure","Fantasy","Sci-Fi"],
"plot" : "Luke Skywalker joins forces with a Jedi Knight, a cocky pilot, a wookiee and two droids to save the universe from the Empire's world-destroying battle-station, while also attempting to rescue Princess Leia from the evil Darth Vader.",
"image_url" : "http://ia.media-imdb.com/images/M/MV5BMTU4NTczODkwM15BMl5BanBnXkFtZTcwMzEyMTIyMw@@._V1_SX400_.jpg",
"rank" : 226,
"running_time_secs" : 7260,
"actors" : ["Mark Hamill","Harrison Ford","Carrie Fisher"],
"year" : 1977
}Nous pouvons voir que le document contient un titre, une liste de réalisateurs (directors), une liste de genres (genres), un résumé (plot), son rang dans la collection (rank) ou sa note attribuée par les internautes (rating). Nous reposerons sur ces clés par la suite pour interroger les documents.
Avant d’étudier le fonctionnement d'Elasticsearch, il faut d’abord comprendre le fonctionnement d’un moteur de recherche. Les résultats retournés par une requête peuvent être de nature troublante lorsque l’on est habitué à manipuler une base de données. En effet, à chaque requête correspond l’évaluation de la pertinence des documents par rapport à cette requête. Cette pertinence est donnée par le calcul d’un score par document. En gros, plus le document ressemble à la requête, plus il aura un score élevé.
Le moteur de recherche Lucene
Les moteurs de recherche reposent sur le domaine de la "Recherche d’information" principalement utilisé dans les moteurs de recherche tels que Google, Bing, Yahoo!, DuckDuckGo, Qwant… Parmi eux, nous pouvons trouver le moteur de recherche Lucene, un logiciel OpenSource Apache présent dans de nombreux site web pour créer des moteurs de recherche dédiés. L’avantage est de pouvoir le paramétrer et de jouer avec le nombreuses fonctionnalités du moteur (chapitre "Putting into Practice - Full-Text Indexing with Lucene" du livre "Web Data Management"). Mais ce qui est encore plus intéressant est de savoir qu’Elasticsearch utilise Lucene pour ses requêtes. Regardons cela ensemble.
Le principe est assez simple : tous les mots d’un texte ont leur importance et on peut effectuer des recherches sur ces mots. Mais cela ne repose pas simplement sur le fait que le mot est présent dans un document pour qu’il réponde ; il faut être capable de déterminer sa pertinence, sinon comment ferions-nous pour trouver celui qui nous intéresse le plus ?
Pour cela, nous allons utiliser la fréquence des mots dans le document (de quoi on parle dans ce document), la fréquence des mots dans l’ensemble des documents (est-ce que ce mot est vraiment important), la taille du document (document court vs roman). Au final, on va obtenir pour chaque mot un poids qui va nous servir pour établir un score pour chaque requête avec un modèle mathématique reposant sur des vecteurs et la fonction cosinus.
Je vous rassure, nous n’allons pas regarder le modèle mathématique en détail, le but est de comprendre ce qu’il se passe avec les mots pour au final bien écrire sa requête pour analyser les résultats. En effet, c’est cela le fond du problème : est-ce que mon moteur de recherche est utile pour ce que je demande ? Est-ce que je ne pourrais pas avoir un moteur de recherche dédié à mes données plutôt que de reposer sur Google ?
Donc, nous avons des poids ; comment pouvons-nous obtenir un score ? Nous allons pour cela représenter un document par un vecteur dans l’espace des mots. Pour cela, je suppose une requête de 2 mots au hasard : Jedi et Princess. Tous les documents peuvent alors être placés dans cet espace en fonction des poids de ces mots ; dépendant de la fréquence des mots Jedi et Princess, ainsi que de la taille des documents. De même, on peut positionner la requête avec ces deux mots. Le score de pertinence est donné par la fonction cosinus entre la requête et chacun des documents, comme l’illustre l’image ci-dessous. Le cosinus ? C’est la mesure de l’angle entre la requête et le document. Ainsi, si ceux-ci se retrouvent très proches (épisode II), alors le cosinus est grand, et le document est pertinent.
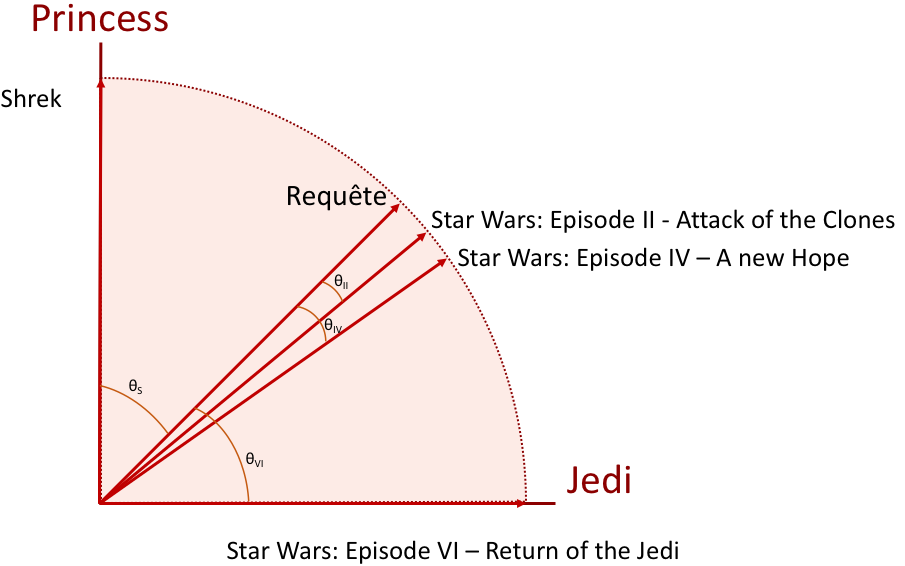
Pour comprendre le principe, il suffit de se dire que le vecteur donne le "sens" du document (au sens propre comme au figuré), si la requête va dans le même sens (cosinus proche de 1), alors c’est ce que nous parlons de la même chose. Et ce score est d’autant plus pertinent que le document parle de ces mots puisque la longueur des vecteurs sont proches (généralement pour des documents courts).
Le graphique ci-dessus illustre bien notre besoin de pertinence. Les épisodes II et IV parlent effectivement de Jedi et de Princess. Toutefois, le plot de l’épisode IV est beaucoup plus gros que celui de l’épisode II. De fait, la pertinence de ces deux mots dans l’épisode IV est amoindrie. Par contre, l’épisode VI parle bien de Jedi, mais pas de Princess (du moins, pas dans le plot), du coup, il est moins pertinent mais répond tout de même à la question en obtenant un score (plus faible). Mais n’oublions pas Shrek qui lui aussi est un film dans le plot contient le mot Princess. Il peut lui aussi répondre à la question avec un score basé uniquement sur le mot Princess.
Le poids d’un mot dépend principalement de :
Sa fréquence dans le texte (plus le mot est présent, plus le sujet est ciblé),
La taille du texte (si l’on parle de tout, chaque mot n’a plus d’importance),
Sa fréquence dans toute la collection de documents (un mot fréquent est moins pertinent). Pour ce dernier point, on peut illustrer le fait que le mot Jedi est moins fréquent dans la base de données de films que le mot Princess. Ce qui explique que ce mot ait plus d’importance et que les angles des épisodes II et IV de la figure penchent en faveur du Jedi.
Cette recherche peut être enrichie en ciblant le texte à rechercher (title, plot) plutôt que l’ensemble du document. Ainsi, les clés du document peuvent être utilisées, pour rechercher un titre de film, un réalisateur ou des mots dans le résumé. Nous verrons les subtilités du langage dans le chapitre suivant.
Maintenant que nous comprenons comment fonctionne un moteur de recherche comme Lucene, nous allons regarder comment il s’interface avec Elasticsearch et comment installer un serveur.
Elasticsearch : un moteur de texte distribué
Pour fonctionner, Elasticsearch aura donc besoin de savoir quels mots sont employés dans chaque document. Pour cela, Elasticsearch intègre un moteur Lucene qui va s’occuper d’extraire les mots d’une collection de documents et de préparer des colonnes de mots. Car en effet, elasticsearch est une base de données NoSQL orientée colonnes : un mot = une colonne de documents avec pour valeur le poids du mot dans chacun des documents. La couche de distribution effectuée par Elasticsearch permet de router les requêtes, paralléliser les traitements, répliquer les données en cas de panne et augmenter la capacité d’indexation de Lucene.
Le schéma ci-dessous illustre ce concept. Chaque serveur est donc un Lucene, en charge d’une partie des documents. Nous étudierons le passage à l’échelle dans le chapitre 3.

Installation d’un serveur elasticsearch
Pour installer un serveur Elasticsearch, il est nécessaire de télécharger les fichiers binaires, disponibles pour chaque systèmes d’exploitation.
Une fois téléchargée, ouvrez l’archive, puis rendez-vous dans le répertoire « bin/ ». Celui-ci contient les fichiers exécutables de démarrage du serveur.
La console affiche alors le log de lancement du serveur avec les modules (PluginsService), le port d’écoute pour le sharding (9300) et celui d’interrogation (9200). La santé du serveur est affichée avec une couleur (YELLOW) que nous aborderons dans le chapitre 3.
>./elasticsearch
[2017-10-09T09:02:33,467][INFO ][o.e.n.Node ] [] initializing ...
[2017-10-09T09:02:33,697][INFO ][o.e.e.NodeEnvironment ] [lNfL2pE] using [1] data paths, mounts [[/ (/dev/disk1)]], net usable_space [9gb], net total_space [111.8gb], spins? [unknown], types [hfs]
[2017-10-09T09:02:33,698][INFO ][o.e.e.NodeEnvironment ] [lNfL2pE] heap size [1.9gb], compressed ordinary object pointers [true]
[2017-10-09T09:02:33,761][INFO ][o.e.n.Node ] node name [lNfL2pE] derived from node ID [lNfL2pEoS7OQGwRGnW1srQ]; set [node.name] to override
[2017-10-09T09:02:33,762][INFO ][o.e.n.Node ] version[5.6.2], pid[37682], build[57e20f3/2017-09-23T13:16:45.703Z], OS[Mac OS X/10.12.6/x86_64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_101/25.101-b13]
[2017-10-09T09:02:33,762][INFO ][o.e.n.Node ] JVM arguments [-Xms2g, -Xmx2g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -Djdk.io.permissionsUseCanonicalPath=true, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Dlog4j.skipJansi=true, -XX:+HeapDumpOnOutOfMemoryError, -Des.path.home=/Users/traversn/Downloads/elasticsearch-5.6.2]
[2017-10-09T09:02:35,724][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [aggs-matrix-stats]
[2017-10-09T09:02:35,725][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [ingest-common]
[2017-10-09T09:02:35,725][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [lang-expression]
[2017-10-09T09:02:35,725][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [lang-groovy]
[2017-10-09T09:02:35,726][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [lang-mustache]
[2017-10-09T09:02:35,726][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [lang-painless]
[2017-10-09T09:02:35,727][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [parent-join]
[2017-10-09T09:02:35,727][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [percolator]
[2017-10-09T09:02:35,727][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [reindex]
[2017-10-09T09:02:35,728][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [transport-netty3]
[2017-10-09T09:02:35,728][INFO ][o.e.p.PluginsService ] [lNfL2pE] loaded module [transport-netty4]
[2017-10-09T09:02:35,730][INFO ][o.e.p.PluginsService ] [lNfL2pE] no plugins loaded
[2017-10-09T09:02:39,428][INFO ][o.e.d.DiscoveryModule ] [lNfL2pE] using discovery type [zen]
[2017-10-09T09:02:40,714][INFO ][o.e.n.Node ] initialized
[2017-10-09T09:02:40,714][INFO ][o.e.n.Node ] [lNfL2pE] starting ...
[2017-10-09T09:02:46,138][INFO ][o.e.t.TransportService ] [lNfL2pE]
publish_address {127.0.0.1:9300}, bound_addresses {[fe80::1]:9300}, {[::1]:9300}, {127.0.0.1:9300}
[2017-10-09T09:02:49,332][INFO ][o.e.c.s.ClusterService ] [lNfL2pE] new_master {lNfL2pE}{lNfL2pEoS7OQGwRGnW1srQ}{SAMpmtTPSf6fh6gkiokXyA}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-elected-as-master ([0] nodes joined)
[2017-10-09T09:02:49,366][INFO ][o.e.h.n.Netty4HttpServerTransport] [lNfL2pE]
publish_address {127.0.0.1:9200}, bound_addresses {[fe80::1]:9200}, {[::1]:9200}, {127.0.0.1:9200}
[2017-10-09T09:02:49,367][INFO ][o.e.n.Node ] [lNfL2pE] started
[2017-10-09T09:02:49,684][INFO ][o.e.g.GatewayService ] [lNfL2pE] recovered [2] indices into cluster_state
[2017-10-09T09:02:50,367][INFO ][o.e.c.r.a.AllocationService] [lNfL2pE]
Cluster health status changed from [RED] to [YELLOW] (reason: [shards started [[movies][0]] ...]).Maintenant que cela fonctionne, laissons tourner cette console et ouvrons une page Web : http://localhost:9200. Celle-ci nous retourne un document JSON donnant les propriétés du cluster :
{
"name" : "lNfL2pE",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "V64T5YQkRAeHru8tXVbVDA",
"version" : {
"number" : "5.6.2",
"build_hash" : "57e20f3",
"build_date" : "2017-09-23T13:16:45.703Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}Importation de données
Toutefois, notre base de données est vide, il faut insérer les données dans un index (l’équivalent d’une table). Chaque index peut être raffiné avec la notion de type, correspondant à une sous-catégorie de l’index que l’on pourra spécifier au besoin. Tous les types d’un index partagent le même schéma de documents JSON.
Pour ce qui est de l’import, le fichier doit respecter certaines caractéristiques. En effet, chaque document JSON à importer doit avoir la même structure (mêmes clés, mêmes types de données, et le même ordre). D’autre part, chacun des documents doit avoir un document JSON
Téléchargez l’archive suivante : movies. Après décompression, vous pourrez constater que chaque document du fichier « movies_elastic.json » est bien prefixé par un index que nous appellerons « movies », avec un type « movie » et un identifiant. Le document qui suit donne un extrait des informations qui seront indexées.
{"index":{"_index": "movies","_type":"movie","_id":1}}
{"fields" : {"directors" : ["Joseph Gordon-Levitt"],"release_date" : "2013-01-18T00:00:00Z","rating" : 7.4,"genres" : ["Comedy","Drama"],"image_url" : "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg","plot" : "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.","title" : "Don Jon","rank" : 1,"running_time_secs" : 5400,"actors" : ["Joseph Gordon-Levitt","Scarlett Johansson","Julianne Moore"],"year" : 2013},"id" : "tt2229499","type" : "add"}
{"index":{"_index": "movies","_type":"movie","_id":2}}
{"fields" : {"directors" : ["Ron Howard"],"release_date" : "2013-09-02T00:00:00Z","rating" : 8.3,"genres" : ["Action","Biography","Drama","Sport"],"image_url" : "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg","plot" : "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.","title" : "Rush","rank" : 2,"running_time_secs" : 7380,"actors" : ["Daniel Brühl","Chris Hemsworth","Olivia Wilde"],"year" : 2013},"id" : "tt1979320","type" : "add"}Pour pouvoir importer ce fichier, il faut l’envoyer sur l’API REST d’Elasticsearch. Pour cela, nous utiliserons le petit utilitaire « curl » qui permet d’envoyer des requêtes HTTP. Nous pourrons ainsi interagir avec la base de de données sur l’adresse : http://localhost:9200
Pour importer le fichier movies_elastic.json, il faut utiliser le paramètre « data-binary » sur le service REST : _bulk
curl -XPUT -H "Content-Type: application/json" localhost:9200/_bulk --data-binary @movies_elastic.jsonCa y est, les données sont importées ! Il peut y avoir des messages d’erreur pour tout document qui ne respecterait pas le schéma (mapping) construit automatiquement avec le premier document importé.
Pour vérifier le contenu de la base, il suffit d’ouvrir un navigateur Web, et d’utiliser l’URL suivante : http://localhost:9200/movies/movie/_search. La liste des films est alors produite en sortie.
L’URL est composée de :
L’index : movies
Le type : movie
Le service utilisé : _search
Schéma et mapping
Nous avons parlé de schéma, correspondant à un mapping. Mais concrètement, qu’est-ce que c’est ? Lucene a besoin, pour effectuer des recherches, de savoir comment lire les données. Par défaut, le texte sera décomposé en mots-clés, les nombres et les dates restants dans leur format d’origine (long, int, date…).
Toutefois, on pourrait se poser la question des réalisateurs ou les acteurs. Est-ce que les noms et prénoms sont des mots-clés ? Ou doit-on les traiter comme des données brutes ? Ce n’est pas grave pour les cas de recherche de texte, mais comme nous pourrons le voir dans le chapitre suivant, le regroupement de données sur du texte n’est pas évident. Par exemple, si nous voulons compter le nombre de films d’un réalisateur, l’utilisation de mots-clés ne permettra pas de combiner "George" et "Lucas" (deux mots-clés). Il faut donc préciser à Elasticsearch que le réalisateur est une donnée brute (format raw). Pour ce faire, il faut s’occuper du mapping.
Le mapping a été généré automatiquement lors de l’importation. Vous pouvez le consulter à cette adresse : http://localhost:9200/movies/?pretty
Le résultat est un document JSON donnant pour chaque clé du document son type et la manière de l’analyser : keyword, text, long, float, date.
{
"movies" : {
"aliases" : { },
"mappings" : {
"movie" : {
"properties" : {
"fields" : {
"properties" : {
"actors" : {
"type" : "text",
"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 25}}
},
"directors" : {
"type" : "text",
"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}
},
"genres" : {
"type" : "text",
"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}
},
"image_url" : {
"type" : "text",
"fields" : {
"keyword" : {"type" : "keyword","ignore_above" : 256}}
},
"plot" : {
"type" : "text",
"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}
},
"rank" : {
"type" : "long"
},
"rating" : {
"type" : "float"
},
"release_date" : {
"type" : "date"
},
"running_time_secs" : {
"type" : "long"
},
"title" : {
"type" : "text",
"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}
},
"year" : {
"type" : "long"
}
}
},
"id" : {
"type" : "text",
"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}
},
"type" : {
"type" : "text",
"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1506695236466",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "NuuvDo6QQhOvwYWj6yD5HQ",
"version" : {
"created" : "5060299"
},
"provided_name" : "movies"
}
}
}
}Par contre, il n’est pas possible de modifier le mapping d’un index une fois qu’il a été instancié (après la première importation). Il faut soit le supprimer, soit en créer un nouveau. Pour pouvoir importer les données avec un mapping approprié à nos données et nos requêtes, nous allons devoir créer une nouvelle base de données "movies2". Le mapping par défaut du texte intègre les mots-clés "keyword", il faut maintenant transformer tout champ ne nécessitant pas une analyse par le type "raw" qui permet de prendre les données telles quel, sans les analyser.
Dans le mapping ci-dessous, nous avons changé le type pour les acteurs, les réalisateurs, genres, et URL. Ainsi, les champs sont bien du texte (type), mais analysé comme données brutes (fields : {raw : {type : "keyword"}} )
{
"movies2": {
"aliases": {},
"mappings": {
"movie": {
"properties": {
"fields": {
"properties": {
"actors": {
"type": "text",
"fields": {"raw": {"type": "keyword"}}
},
"directors": {
"type": "text",
"fields": {"raw": {"type": "keyword"}}
},
"genres": {
"type": "text",
"fields": {"raw": {"type": "keyword"}}
},
"image_url": {
"type": "text",
"fields": {"raw": {"type": "keyword"}}
},
"plot": {
"type": "text",
"fields": {"keyword": {"type": "keyword","ignore_above": 256}}
},
"rank": {
"type": "long"
},
"rating": {
"type": "float"
},
"release_date": {
"type": "date"
},
"running_time_secs": {
"type": "long"
},
"title": {
"type": "text",
"fields": {"keyword": {"type": "keyword","ignore_above": 256}
}
},
"year": {
"type": "long"
}
}
},
"id": {
"type": "text",
"fields": {"keyword": {"type": "keyword","ignore_above": 256}}
},
"type": {
"type": "text",
"fields": {"keyword": {"type": "keyword","ignore_above": 256}}
}
}
}
},
"settings": {
"index": {
"creation_date": "1506695662981",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "JYb2VcMARuCgrb5yHtwJyQ",
"version": {
"created": "5060299"
},
"provided_name": "movies2"
}
}
}
}
Dans l'archive que nous avons téléchargée, un répertoire "mapping_movies" a été décompressé, il contient le fichier de mapping et le nouveau jeu de données. En effet, chaque document doit être préfixé par le nouvel index « movies2 ».
Il faut donc :
1 - Charger le mapping pour le nouvel index "movies2" :
curl -XPUT -H "Content-Type: application/json" localhost:9200/movies2 -d @mapping_movies/mapping.json2 - Importer les données :
curl -XPUT -H "Content-Type: application/json" localhost:9200/_bulk --data-binary @mapping_movies/movies_elastic2.jsonNous pourrons alors vérifier l’importation du nouveau mapping : http://localhost:9200/movies2/?pretty
Et consulter le contenu de notre index : http://localhost:9200/movies2/movie/_search?pretty
Maintenant que nous avons importé les données dans un index sous Elasticsearch, voyons comment interroger un index avec différents types de requêtes.
