La première étape du traitement des données est de récupérer le corpus de textes, de faire une analyse exploratoire afin de bien comprendre les spécificités du jeu de données, et de nettoyer les données afin de pouvoir les utiliser ultérieurement dans vos algorithmes.
Mais avant de nous plonger dans le vif du sujet, introduisons quelques notions.
Si la notion de token ou de vocabulaire est relativement invariante en fonction des jeux de données, le corpus et les documents peuvent avoir des formes très variées :
un fichier excel ou csv avec une liste de produits. Ici, la colonne 'description' est notre corpus, chaque cellule de la colonne 'description' constitue un document:
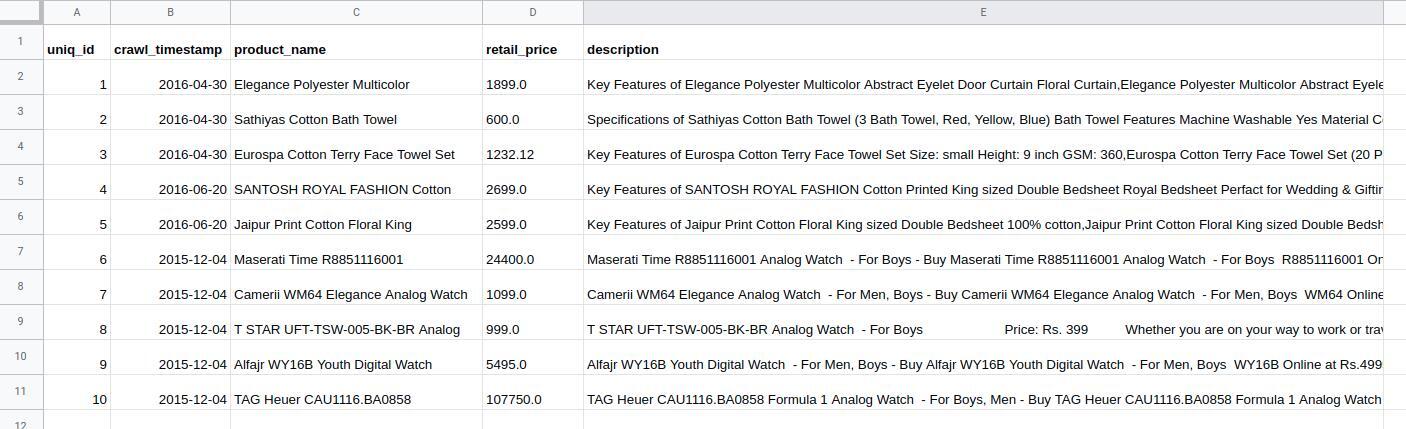
un fichier csv un dossier avec différents fichiers. Chaque fichier est un document et l'ensemble des fichiers constitue le corpus :

une liste de fichiers dans un dossier plusieurs pages web, au format html. Il faudra d'abord télécharger depuis le web les fichiers html, à la main ou de façon automatisée (on parle alors de 'scraping') :
exemple de page wikipedia Dans le cadre d'un fichier html, il faudra transformer le document afin d'extraire l'information textuelle. Nous verrons cela un plus tard dans le cours.
Nous pouvons maintenant aborder le pré-traitement du texte en plusieurs étapes :
La récupération du corpus, ansi qu'un premier traitement de ce dernier pour avoir des données textuelles exploitables (au format string).
La tokenization, qui désigne le découpage en mots des différents documents qui constituent votre corpus.
La normalisation et la construction du dictionnaire qui permet de ne pas prendre en compte des détails importants au niveau local (ponctuation, majuscules, conjugaison, etc.)

J'en conviens, la partie nettoyage n'est pas la plus intéressante, mais elle est essentielle. Pour rendre la chose plus attrayante, je vais réaliser une étude partiale et partielle des artistes français de rap et leur vocabulaire propre.
Récupération du corpus de texte
La première étape est la récupération du texte. Il existe plusieurs manières de récupérer du texte : soit depuis une base de donnée que vous possédez, soit depuis des fichiers XML ou autres que vous possédez, soit en scrapant des pages comme le font les moteurs de recherches, en utilisant une API.
Nous ne traiterons pas cette partie, qui est relativement laborieuse et techniquement peu intéressante. Il existe diverses manières de scraper du texte comme à l'aide des librairies scrapy ou beautifulsoup.
Dans mon cas, j'ai scrapé la page wikipédia qui propose une liste des rappeurs français. J'ai ensuite récupéré les paroles des différentes chansons de ces rappeurs sur le site Genius, toujours en scrapant. Je ne suis malheureusement pas autorisé à vous fournir ce jeu de données, libre à vous d'effectuer la même démarche. Vous pouvez aussi utiliser un jeu de données présent par défaut dans la librairie NLTK.
Le texte que vous utilisez, que l'on appelle « corpus », peut être organisé de plusieurs manière différentes :
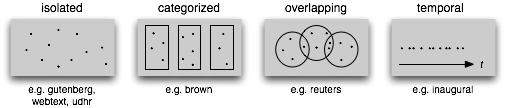
Chargeons donc les données, dans un dictionnaire python, ce que je fais avec la fonction load_all_sentences que j'ai créée pour mon exemple.
db = load_all_sentences();
print('chargement de {} vers dans la db'.format(len(db.keys())))chargement de 788957 vers dans la db
Mon dictionnaire est simplement constitué d'objets de la forme { vers, artiste }
Je crée aussi une table de recherche par artiste car on va s'intéresser à ce qui les différencie et les caractérise. De plus, je veux avoir assez de texte pour chaque artiste donc je vais éliminer ceux qui ont écrit moins de 200 vers.
from collections import defaultdict
base_artistes = defaultdict(set)
for k,v in db.iteritems():
base_artistes[v['artistes']].add(k)
artistes = { k:v for k,v in artistes.iteritems() if len(v) > 200 }
print('{} artistes'.format(len(artistes)))377 artistes
Exploration du texte : tokenisation et analyse des fréquences
On veut dans un premier temps étudier le vocabulaire utilisé par chaque artiste. Pour une première intuition, il est judicieux d'observer le nombre de mots utilisés.
On va utiliser la fonction word_tokenize (« tokenize » signifie « séparer par mot ») qui va décomposer les vers en tableaux de mots afin de pouvoir effectuer des opérations dessus. Observons déjà son comportement sur un bout de texte simple :
import nltk
test = "Bonjour, je suis un texte d'exemple pour le cours d'Openclassrooms. Soyez attentifs à ce cours !"
nltk.word_tokenize(test)['Bonjour', ',', 'je', 'suis', 'un', 'texte', "d'exemple", 'pour', 'le', 'cours', "d'Openclassrooms", '.', 'Soyez', 'attentifs', '\xc3\xa0', 'ce', 'cours', '!']
On a bien une séparation par mot. Petit problème en revanche, la ponctuation est conservée comme étant un "token" ! Il faut donc trouver un moyen d'éliminer cette ponctuation, car ce sont les mots qui nous intéressent comme caractéristiques . On remarque aussi qu'il y a un problème sur les apostrophes considérés comme faisant partie du mot. Ainsi "d'exemple" devrait être séparé en "de" et "exemple". Un autre problème, c'est que certains mots on des majuscules car ils apparaissent en début de phrases ou de vers, alors que ce sont les mêmes mots.
Ca parait tout d'un coup un peu compliqué à mettre en place, n'est-ce pas ? 😏
Il est vraiment important de regarder les options sur ce genre de fonctions qui englobent plusieurs actions sur votre corpus afin d'être bien sûr qu'elles effectuent ce que vous voulez.
Le fait d'essayer d'harmoniser les tokens est un processus nommé « normalisation ». Bon, on va déjà utiliser les bonne vieilles expressions régulières pour ne récupérer que les caractères alphanumériques de chaque phrase. Vous trouverez à cette adresse un rappel utile sur les expressions régulières.
Ensuite, on va utiliser un tokenizer specifique au français ce qui permet de traiter la ponctuation de la bonne manière. On élimine aussi les majuscules peu informatives, avec la fonction « lower ».
tokenizer = nltk.RegexpTokenizer(r'\w+')
tokenizer.tokenize("Bonjour, je suis un texte d'exemple pour le cours d'Openclassrooms. Soyez attentifs à ce cours !")
['Bonjour', 'je', 'suis', 'un', 'texte', 'd', 'exemple', 'pour', 'le', 'cours', 'd', 'Openclassrooms', 'Soyez', 'attentifs', '\xc3', 'ce', 'cours']
Ah, ça commence à être mieux ! Maintenant qu'on a bien séparé notre texte en unité de mots (tokens) on peut l'appliquer au jeu de données qui nous intéresse, et compter la fréquence d'apparition des différents mots pour avoir une idée du champ lexical. On effectue ce comptage par artiste pour comparer.
tokenizer = nltk.RegexpTokenizer(r'\w+')
def freq_stats_corpora():
corpora = defaultdict(list)
# Création d'un corpus de tokens par artiste
for artiste,sentence_id in artistes.iteritems():
for sentence_id in sentence_id:
corpora[artiste] += tokenizer.tokenize(
db[sentence_id]['text'].decode('utf-8').lower()
)
stats, freq = dict(), dict()
for k, v in corpora.iteritems():
freq[k] = fq = nltk.FreqDist(v)
stats[k] = {'total': len(v)}
return (freq, stats, corpora)
# Récupération des comptages
freq, stats, corpora = freq_stats_corpora()
df = pd.DataFrame.from_dict(stats, orient='index')
# Affichage des fréquences
df.sort(columns='total', ascending=False)
df.plot(kind='bar', color="#f56900", title='Top 50 Rappeurs par nombre de mots')
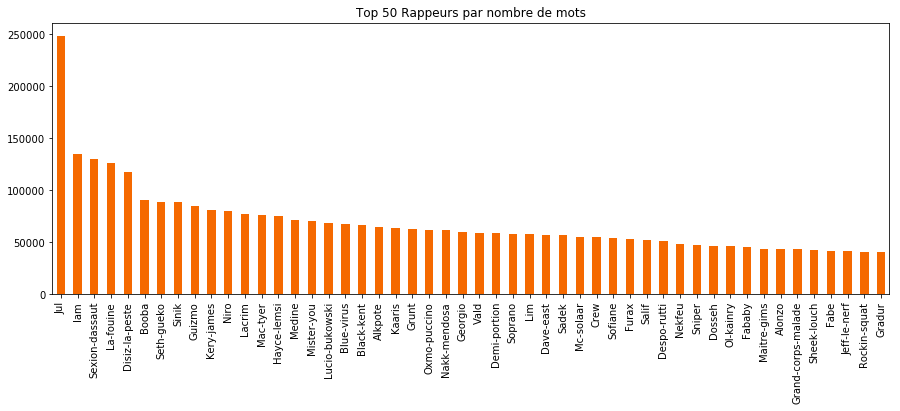
Nour voyons ici quel artiste a écrit le plus de texte et de chansons. C'est intéressant, mais qu'en est-il de la variété du champ lexical utilisé, c'est à dire le nombre de mots uniques utilisés par chaque artistes dans leurs chansons ? Nous souhaitons en effet savoir qui a le vocabulaire le plus riche !😀
Pour le savoir, nous devons représenter un document (ou ici, un artiste) par ce qu'on appelle un bag-of-words.
Modifions donc notre fonction freq_stats_corpora pour faire le comptage du vocabulaire unique.
def freq_stats_corpora():
corpora = defaultdict(list)
for artiste,sentence_ids in artistes.iteritems():
for sentence_id in sentence_ids:
corpora[artiste] += tokenizer.tokenize(
db[sentence_id]['text'].decode('utf-8').lower()
)
stats, freq = dict(), dict()
for k, v in corpora.iteritems():
freq[k] = fq = nltk.FreqDist(v)
stats[k] = {'total': len(v), 'unique': len(fq.keys())}
return (freq, stats, corpora)
Affichons à nouveau nos comptages :

Mais ça ne se terminera donc jamais ?! 😢
Pour faciliter des choses, nous décomposons les différentes étapes. À force d'utiliser des corpus de textes, vous saurez les traiter de manière un peu plus automatique en fonction de votre problématique.
Ceci-dit, le prétraitement du texte est une première étape importante et il faut vraiment observer le contenu de votre corpus après transformation pour être sûr que les données correspondent à ce que vous désirez, en vue des traitements ultérieurs.
Conclusion
Vous possédez à présent une première idée des étapes qui constituent le prétraitement du texte : récupération du corpus, tokenisation et première visualisation des différentes fréquences.
