Après la tokenization, voyons comment nettoyer et normaliser notre corpus afin d'obtenir une matrice de vocabulaire et un dictionnaire représentatifs de nos documents.
Première passe de nettoyage : supprimer les stopwords
La première manipulation souvent effectuée dans le traitement du texte est la suppression de ce qu'on appelle en anglais les stopwords. Ce sont les mots très courants dans la langue étudiée ("et", "à", "le"... en français) qui n'apportent pas de valeur informative pour la compréhension du "sens" d'un document et corpus. Il sont très fréquents et ralentissent notre travail : nous souhaitons donc les supprimer.
Il existe dans la librairie NLTK une liste par défaut des stopwords dans plusieurs langues, notamment le français. Mais nous allons faire ceci d'une autre manière : on va supprimer les mots les plus fréquents du corpus et considérer qu'il font partie du vocabulaire commun et n'apportent aucune information. Ensuite on supprimera aussi les stopwords fournis par NLTK.
Allez, on s'en débarasse !
# Premièrement, on récupère la fréquence totale de chaque mot sur tout le corpus d'artistes
freq_totale = nltk.Counter()
for k, v in corpora.iteritems():
freq_totale += freq[k]
# Deuxièmement on décide manière un peu arbitraire du nombre de mots les plus fréquents à supprimer. On pourrait afficher un graphe d'évolution du nombre de mots pour se rendre compte et avoir une meilleure heuristique.
most_freq = zip(*freq2.most_common(100))[0]
# On créé notre set de stopwords final qui cumule ainsi les 100 mots les plus fréquents du corpus ainsi que l'ensemble de stopwords par défaut présent dans la librairie NLTK
sw = set()
sw.update(stopwords)
sw.update(tuple(nltk.corpus.stopwords.words('french')))
Nous avons maintenant le nombre de mots uniques non stopwords utilisés par les artistes. Pour rappel, on souhaite comprendre la variété lexicale des rappeurs choisis. Il est donc logique de supprimer les mots les plus utilisés, ce qui signifie par extension qu'ils ne sont pas porteurs de sens.
On réeffectue notre tokenisation en ignorant les stopwords et on affiche ainsi notre nouveau histogramme des fréquences duquel on a supprimé les stopwords
def freq_stats_corpora2(lookup_table=[]):
corpora = defaultdict(list)
for artist, block_ids in lt_artists.iteritems():
for block_id in block_ids:
tokens = tokenizer.tokenize(db_flat[block_id]['text'].decode('utf-8'))
corpora[artist] += [w for w in tokens if not w in list(sw)]
stats, freq = dict(), dict()
for k, v in corpora.iteritems():
freq[k] = fq = nltk.FreqDist(v)
stats[k] = {'total': len(v), 'unique': len(fq.keys())}
return (freq, stats, corpora)
freq2, stats2, corpora2 = freq_stats_corpora2()
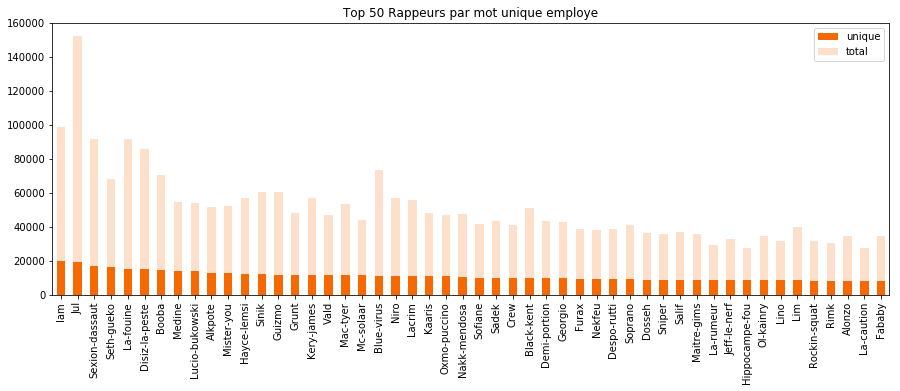
Il y a bien un changement dans le classement, maintenant qu'on a enlevé les mots les plus communs, si vous comparez au classement du chapitre précédent.
Deuxième passe : lemmatisation ou racinisation (stemming)
Plus qu'une dernière étape et vous en aurez terminé avec le prétraitement !
Le processus de « lemmatisation » consiste à représenter les mots (ou « lemmes » 😉) sous leur forme canonique. Par exemple pour un verbe, ce sera son infinitif. Pour un nom, son masculin singulier. L'idée étant encore une fois de ne conserver que le sens des mots utilisés dans le corpus.
Si l'on reprend notre exemple précédent, "Bonjour, je suis un texte d'exemple pour le cours d'Openclassrooms. Soyez attentifs à ce cours !"
L'idéal serait d'extraire les lemmes suivants : « bonjour, être, texte, exemple, cours, openclassrooms, être, attentif, cours ». Dans le processus de lemmatisation, on transforme donc « suis » en « être» et « attentifs » en « attentif ».
Dans notre cas, je voulais étudier la richesse du vocabulaire des artistes. C'est donc mieux de compter le nombre d'occurrences du verbe être plutôt que de compter séparément chaque usage de conjugaison de ce même verbe. De même pour les pluriels etc. On estime que c'est plus représentatif, j'espère que vous êtes d'accord ! 😏
Il existe un autre processus qui exerce une fonction similaire qui s'appelle la racinisation(ou stemming en anglais). Cela consiste à ne conserver que la racine des mots étudiés. L'idée étant de supprimer les suffixes, préfixes et autres des mots afin de ne conserver que leur origine. C'est un procédé plus simple que la lemmatisation et plus rapide à effectuer puisqu'on tronque les mots essentiellement contrairement à la lemmatisation qui nécessite d'utiliser un dictionnaire.
Dans notre cas, on va effectuer une racinisation parce qu'il n'existe pas de fonction de lemmatisation de corpus français dans NLTK 😶 Je suis d'accord que ce serait encore mieux.
from nltk.stem.snowball import FrenchStemmer
stemmer = FrenchStemmer()
def freq_stats_corpora3(lookup_table=[]):
corpora = defaultdict(list)
for artist, block_ids in lt_artists.iteritems():
for block_id in block_ids:
tokens = tokenizer.tokenize(db_flat[block_id]['text'].decode('utf-8').lower())
corpora[artist] += [stemmer.stem(w) for w in tokens if not w in list(sw)]
stats, freq = dict(), dict()
for k, v in corpora.iteritems():
freq[k] = fq = nltk.FreqDist(v)
stats[k] = {'total': len(v), 'unique': len(fq.keys())}
return (freq, stats, corpora)
freq3, stats3, corpora3 = freq_stats_corpora3()
df3 = pd.DataFrame.from_dict(stats3, orient='index').sort(columns='unique', ascending=False)

On a ici utilisé des étapes de nettoyage classique de texte mais en réalité, il est parfois utile de conserver le texte brut quand on est pas dans une recherche du sens d'un document mais de phrases dans leur ensemble puisqu'on cherche le lien entre les différents mots. On aura un aperçu de cet aspect dans les prochains chapitres.
Conclusion
Vous avez effectué quelques étapes essentielles du prétraitement du texte : tokenisation, suppression des stop-words, lemmatisation et stemming. Nous pouvons maintenant passer à la création de notre ensemble de features représentatives de notre corpus de texte. C'est le sujet de la prochaine partie ! Suivez-moi.
