Après avoir vu les différents types de nettoyage du texte possible dans les chapitres précédent, nous allons maintenant étudier comment extraire l'information du texte pour le traitement ultérieur par des modèles de machine learning. En d'autres termes, nous cherchons une représentation du langage pour un modèle statistique qui vise à exploiter des données textes.
Qu'est-ce qu'un « bag of words »
La manière la plus simple de représenter un document, c'est ce qu'on a effectué dans le chapitre précédent où l'on a considéré tous les mots utilisés pour chaque artiste, sans distinction ni dépendance par vers, chanson, etc. L'analogie est donc qu'on a considéré chaque artiste par la représentation brute d'un "sac" de tous les mots qu'il a utilisé, sans soucis de contexte (ordre, utilisation, etc).
On peut faire la même chose à l'échelle d'un document qu'on représente par un ensemble des mots qu'il contient. En pratique, ça peut être par exemple un vecteur de fréquence d'apparition des différents mots utilisés (ou stem 😉).
Une représentation bag-of-words classique sera donc celle dans laquelle on représente chaque document par un vecteur de la taille du vocabulaire et on utilisera la matrice composée de l’ensemble de ces N documents qui forment le corpus comme entrée de nos algorithmes.
Prendre en compte les co-occurences
La première chose à considérer, au delà d'une tokenisation, c'est qu'il est possible de séparer le texte en groupes de plusieurs mots. On appelle les groupes de mots les n-grammes (n-gram) : bigrammes pour les couples de mots, trigrammes pour les groupes de 3, etc. Séparer en mot unique est en fait un cas particulier appelé unigrammes.
Par exemple dans la phrase : « Je mange une pomme », on peut extraire les bigrammes {(je, mange), (mange, une) et (une, pomme)}
Pourquoi utiliser des n-grammes avec n>1 ?
Lorsqu'on fait fasse à une problématique de modélisation du langage, on voit bien que pour étudier idéalement le sens d'un mot il faudrait l'observer dans son contexte. Il existe donc dans un texte (et par extension dans le langage) une forme de dépendance plus ou moins grande entre les mots.
A titre d'exemple, le pronom "je" aura grandement plus de chance d'être suivi d'un verbe. On peut donc traiter chaque mot comme ayant une probabilité d'apparition en fonction du texte qui le précède, c'est à dire comme une séquence. Dans l'idéal, on veut traiter tout le texte de cette façon, mais ce n'est pas possible en terme de capacité de calculs.
En pratique, on peut prendre les quelques mots précédents qui représentent assez d'information pour avoir un modèle séquentiel (markovien) intéressant, d'où l'apparition des n-grammes.
Par exemple on peut assigner une probabilité au bigramme ("je", "mange") :
En pratique, on peut aussi utiliser la fonction bigrams de NLTK
test = "Bonjour, je suis un texte d'exemple pour le cours d'Openclassrooms. Soyez attentifs à ce cours !"
tokens = tokenizer.tokenize(test.lower())
list(nltk.bigrams(tokens))[(u'bonjour', u'je'), (u'je', u'suis'), (u'suis', u'un'), (u'un', u'texte'), (u'texte', u'd'), (u'd', u'exemple'), (u'exemple', u'pour'), (u'pour', u'le'), (u'le', u'cours'), (u'cours', u'd'), (u'd', u'openclassrooms'), (u'openclassrooms', u'soyez'), (u'soyez', u'attentifs'), (u'attentifs', u'\xe0'), (u'\xe0', u'ce'), (u'ce', u'cours')]Une autre manière de pondérer : le tf-idf
Depuis le départ, on a seulement utilisé les fréquences d'apparition des différents mots/n-grammes présents dans notre corpus. Le problème est que si l'on veut vraiment représenter un document par les n-grammes qu'il contient, il faudrait le faire relativement à leur apparition dans les autres documents.
En effet, si un mot apparait dans d'autres documents, il est donc moins représentatif du document qu'un mot qui n'apparait que uniquement dans ce document.
Nous avons d'abord supprimé les mots les plus fréquents de manière générale dans le langage (les fameux stopwords). À présent, il ne faut pas considérer le poids d'un mot dans un document comme sa fréquence d'apparition uniquement, mais pondérer cette fréquence par un indicateur si ce mot est commun ou rare dans tous les documents.
Pour résumer, le poids du n-gramme est le suivant :
En l’occurence, la métrique tf-idf (Term-Frequency - Inverse Document Frequency) utilise comme indicateur de similarité l'inverse document frequency qui est l'inverse de la proportion de document qui contient le terme, à l'échelle logarithmique. Il est appelé logiquement « inverse document frequency » (idf).
Nous calculons donc le poids tf-idf final attribué au n-gramme :
Dans notre exemple, un document égale un artiste. Pour connaître les termes qui représentent le plus un artiste, nous allons utiliser la fonction tf-idf de scikit
import os
def stem_tokens(tokens, stemmer):
stemmed = []
for item in tokens:
stemmed.append(stemmer.stem(item))
return stemmed
def tokenize(text):
tokens = nltk.word_tokenize(text)
stems = stem_tokens(tokens, stemmer)
return stems
for subdir, dirs, files in os.walk(path):
for file in files:
file_path = subdir + os.path.sep + file
shakes = open(file_path, 'r')
text = shakes.read()
lowers = text.lower()
no_punctuation = lowers.translate(None, string.punctuation)
token_dict[file] = no_punctuation
tfidf = TfidfVectorizer(tokenizer=tokenize, stop_words=sw)
values = tfidf.fit_transform(token_dict.values())Maintenant qu'on a cet indicateur, on peut comparer les différents champs lexicaux qui représentent le plus un artiste. Qui dit comparaison dit similarité. On peut donc utiliser ... t-SNE !
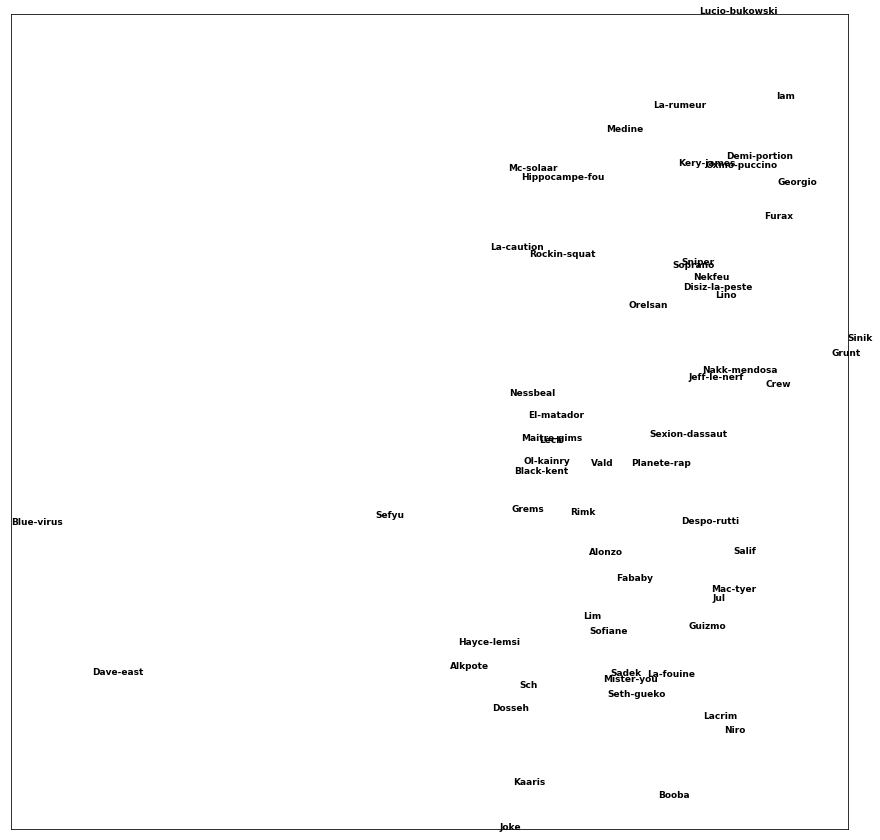
Extraire les informations
La récupération de caractéristiques va assez loin puisqu'on essaie de dégager de nos documents texte non structurés des informations structurées informatives très restreintes :
NER (Named Entity Recognition) : reconnaître des personnes, endroits, entreprises, etc.
Extraction de relations : essayer d'extraire des relations sémantiques entre différents termes du texte. Par exemple, des relations familiales ("Marie est l'enfant de Patrick") spatiales ("Le piano est devant la fenêtre"), etc. Ces informations peuvent ensuite être stockées dans une base de données relationnelles ou un graphe.
Extraction d'événements : extraire des actions qui arrivent à nos entités. Par exemple "le cours de l'action X a augmenté de 5%" ou bien "le président à déclaré X dans son discours"
POS Tagging (Part-of-Speech Tagging) : représente les méthodes qui récupèrent la nature grammatical des mots d’une phrase - nom, verbe, adjectif, etc. Ce sont des propriété qui peuvent servir de caractéristiques utile lors de la création de certains modèles

Vous pouvez essayer l'API Google Natural Langage pour avoir une idée des capacité d'extraction d'information possible par les algorithmes industriels.
Attention aux matrices creuses
Avec les méthodes de comptage évoquées, nous créons en réalité des « matrices creuses ». En effet, les mots ne sont pas présents dans chaque document (le ratio vocabulaire / taille de document est trop élevé). De plus, on utilise plus souvent certains mots (“et”, “le”, etc.) et d’autres plus rarement (dans des contextes précis).
Cette grosse différence créé des matrices larges (de la taille « nombre de documents * taille du vocabulaire ») qui sont essentiellement vides. On verra qu’on peut utiliser ces matrices avec un certain nombre d’algorithmes, mais c’est tout de même un gaspillage non négligeable de ressources que de travailler avec des matrices de cette taille alors que la plupart des entrées ne sont pas informatives.
De plus, les matrices creuses peuvent biaiser les algorithmes qui considèrent ainsi que les observations à zéro (qui sont présentes en majorité) représente une information à prendre en considération. Si on pense en terme de moyenne par exemple, elle sera écrasée par la présence de toute ces entrées vides sans pour autant apporter plus de sens à notre calcul. Nous allons voir dans les prochaines parties des alternatives de représentation de texte afin de contrecarrer ce problème quand c'est nécessaire.
Conclusion
Ces extractions de caractéristiques seront assez intuitives en fonction du problème rencontré. L'idée principale étant de transformer cette masse de texte non structurée en données digestes pour vos algorithmes et vos capacités de calculs. Cependant, ce type de représentation créé des matrices creuses qu’il est parfois difficile à gérer, par exemple dans le cadre de l’utilisation de réseaux de neurones.
