TP : Partitionnez vos données
Appliquons la classification hiérarchique et l'algorithme k-means sur 2 de nos échantillons : bag_of_words.csv, ainsi que notre chat mystery.csv.
L'échantillon en bag of words
Vous pouvez travailler directement depuis Google Colab, ou depuis un Jupyter Notebook sur votre machine.
La particularité de cet échantillon est qu'il contient énormément de variables : plus de 9 000 !
Partitionner, c'est regrouper les individus similaires. Dans cet échantillon, les individus sont des cours OpenClassrooms. Chacun est décrit par plus de 9 000 variables, qui correspondent chacune à un mot. Ainsi, deux cours seront similaires si leurs textes contiennent beaucoup de mots en commun.
Voici un exemple de dendrogramme obtenu (cliquez sur l'image pour zoomer) :
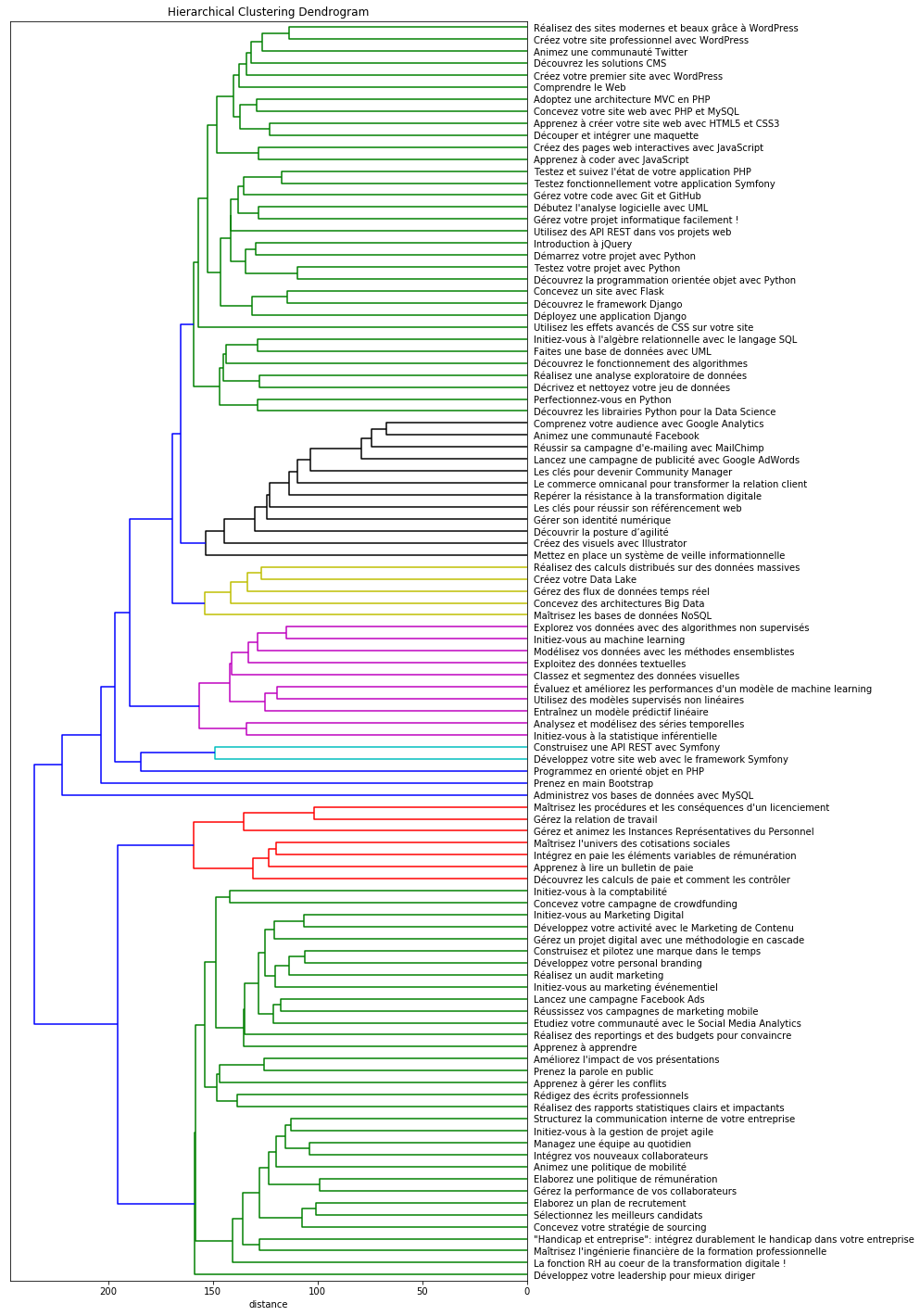
On peut ensuite couper l'arbre de manière à obtenir 12 clusters. À partir de ces 12 clusters, il peut être intéressant, par curiosité, de voir si les cours regroupés en un même cluster ont tendance à appartenir à une même thématique ou non. La thématique des cours est connue, et elle est stockée dans la variable theme. Pour ceci, nous afficherons le tableau de contingence entre les variables cluster et theme :
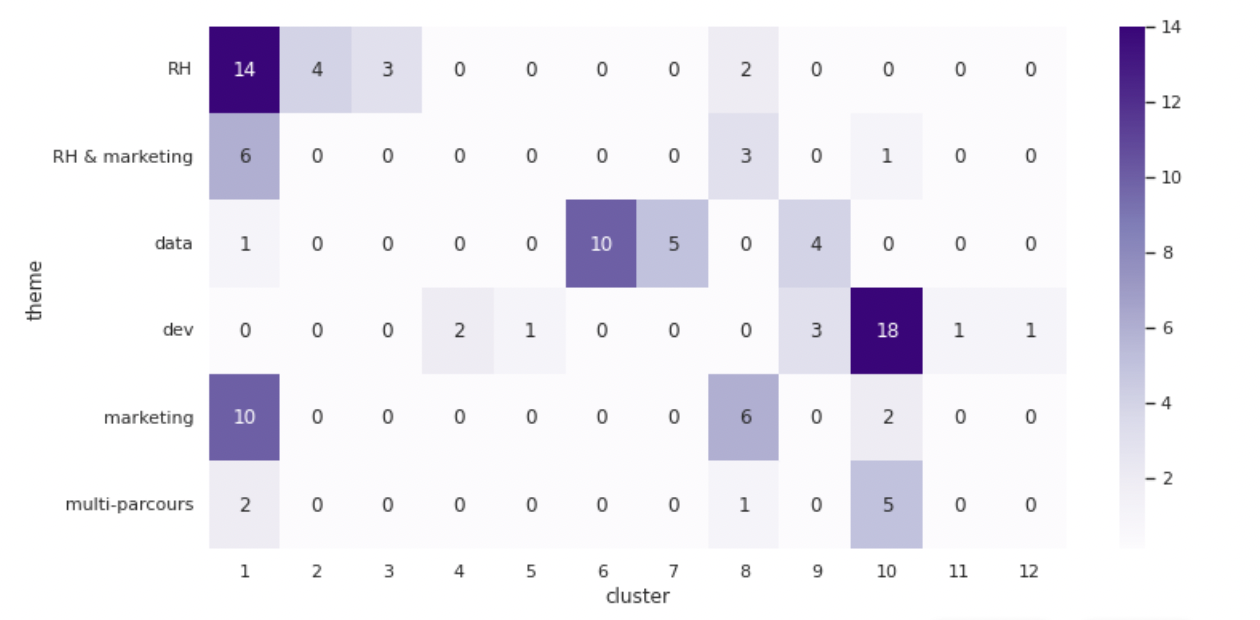
Impressionnant ! Mais comment l'analyser ?
Tout d'abord, on y voit que le cluster 1 a "capté" la grande majorité des cours de RH et de marketing : en effet, il en contient 30 (14 + 6 + 10) alors qu'il y a au total 51 cours de marketing et de RH. Et, surprise, un cours de data s'est glissé dans ce cluster !
À y regarder de plus près, on voit qu'il s'agit du cours Réalisez des rapports statistiques clairs et impactants. Sur le dendrogramme, on voit qu'il est proche de cours tels que Rédigez des écrits professionnels ou Améliorez l'impact de vos présentations, qui sont des cours destinés aux formation RH et marketing. Finalement, c'est assez compréhensible : le cours Réalisez des rapports statistiques clairs et impactants, même s'il est destiné aux data analysts, est plus similaire aux cours de communication écrite ou orale qu'aux cours de statistiques purement mathématiques.
J'en profite au passage pour vous conseiller vivement de le suivre, car si vous ne savez pas rendre compte de vos analyses, vous aurez presque travaillé pour rien. ;)
Ensuite, on voit que le reste des cours de data sont répartis entre les clusters 6, 7 et 9. Le cluster 6 est très orienté Data Analyse / Data Science, alors que le cluster 7 est plus orienté Data Architecture ou Data Engineering. Quant au cluster 9, il contient également des cours de développement informatique. En fait, ceux-ci parlent de thématiques qui sont à mi-chemin entre la data et le développement : bases de données, librairies Python adaptées à la data science, algorithmes, etc.
Le chat
Appliquons maintenant l'algorithme k-means sur notre chat.
Mais cette fois, nous allons changer un peu de configuration... En effet, j'ai supprimé (par erreur, bien sûr) des lignes dans mon notebook. Pourriez-vous m'aider à les réécrire ?
Vous pouvez travailler directement depuis Google Colab, ou depuis un Jupyter Notebook sur votre machine.
