Stockez et accédez à des fichiers sur Amazon S3

Dans ce chapitre, je vous propose d'essayer Amazon S3 en créant un bucket et en y ajoutant des fichiers.
Rendez-vous sur Amazon S3 (Simple Storage Service) dans votre console AWS. Vous devriez voir qu'il n'y a pour l'instant aucun bucket (compartiment) :
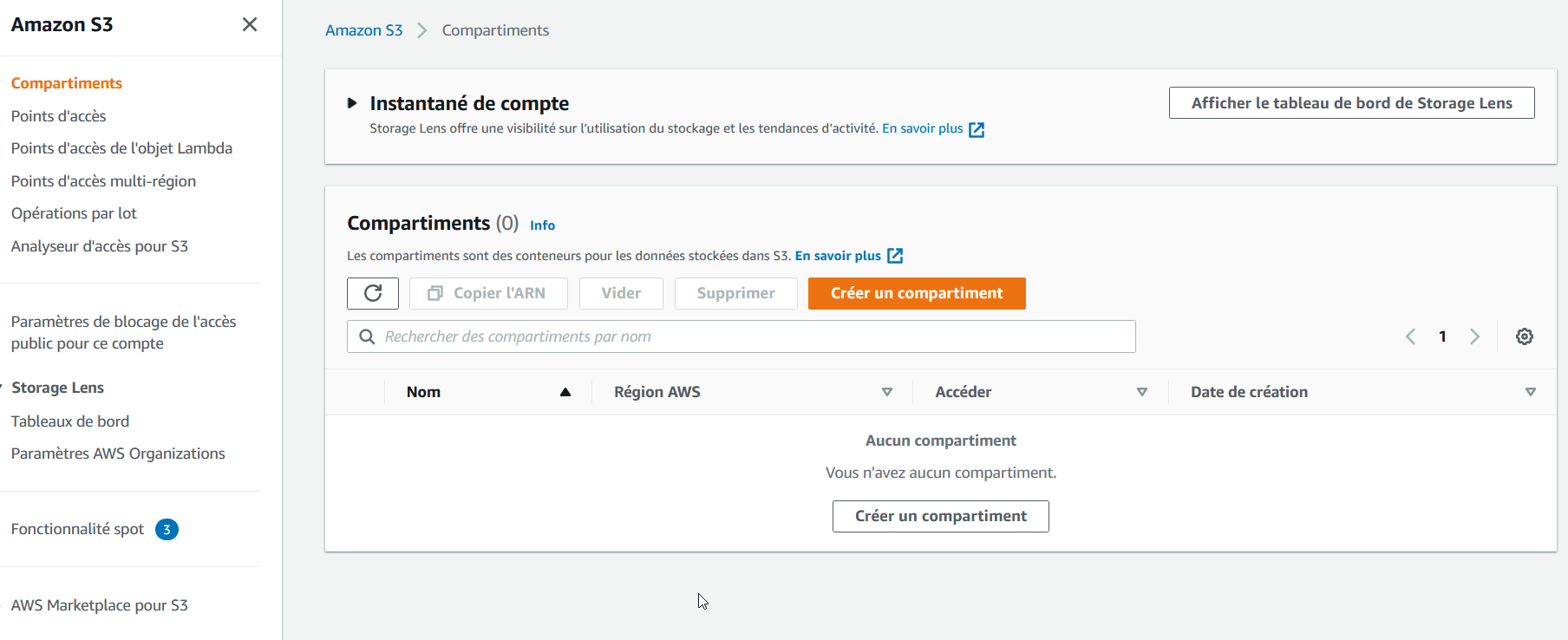
Créez votre premier bucket
Nous ne pourrons pas faire grand-chose tant que nous n'aurons pas créé un bucket. Alors allons-y ! Cliquez sur "Créer un compartiment".
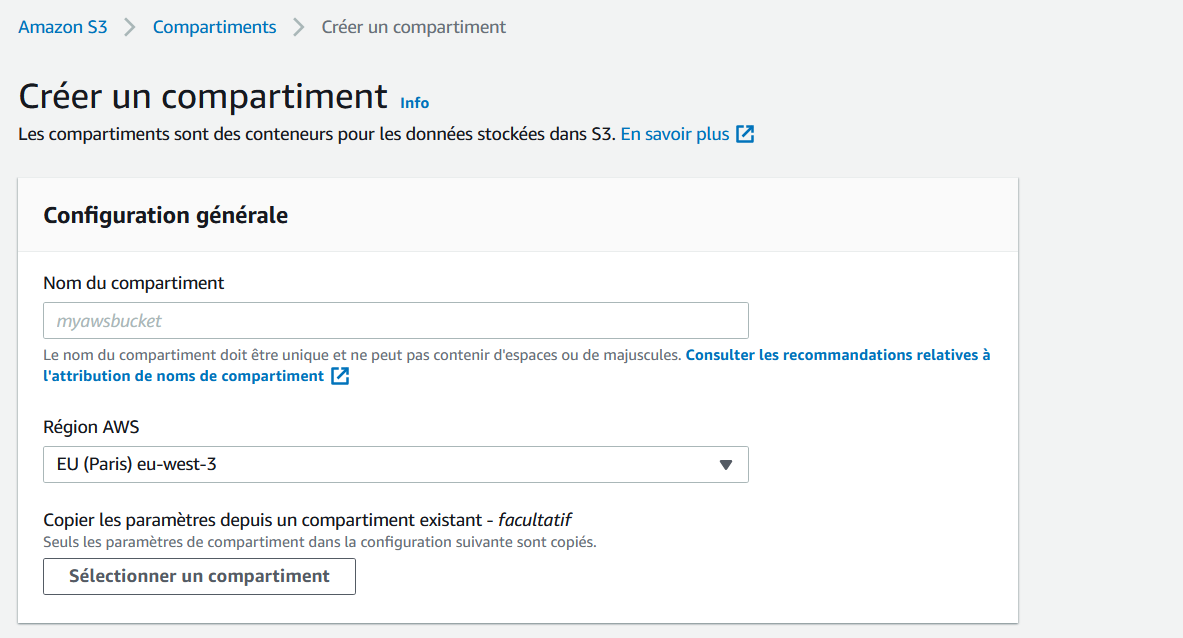
Il vous faudra donner un nom unique à votre bucket. Ce nom ne doit jamais avoir été utilisé par quelqu'un d'autre. Cela fonctionne un peu comme les noms de domaine !
Je vais appeler le mien "mateotestbucket", celui-là n'est pas pris !
Vous pouvez aussi indiquer ici la région où le bucket sera créé.
Faites défiler la page de création sans toucher au reste des options :
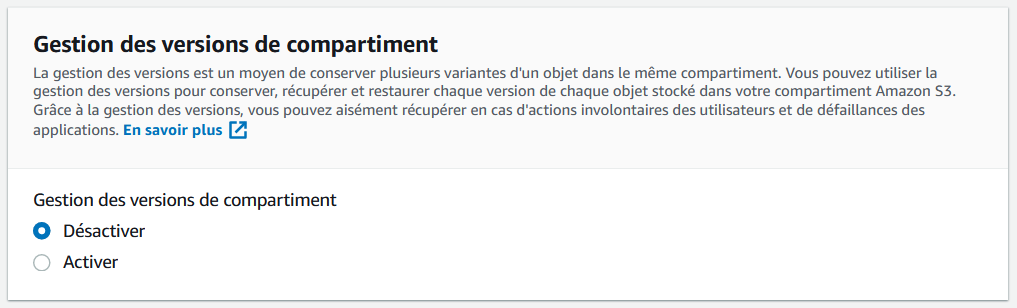
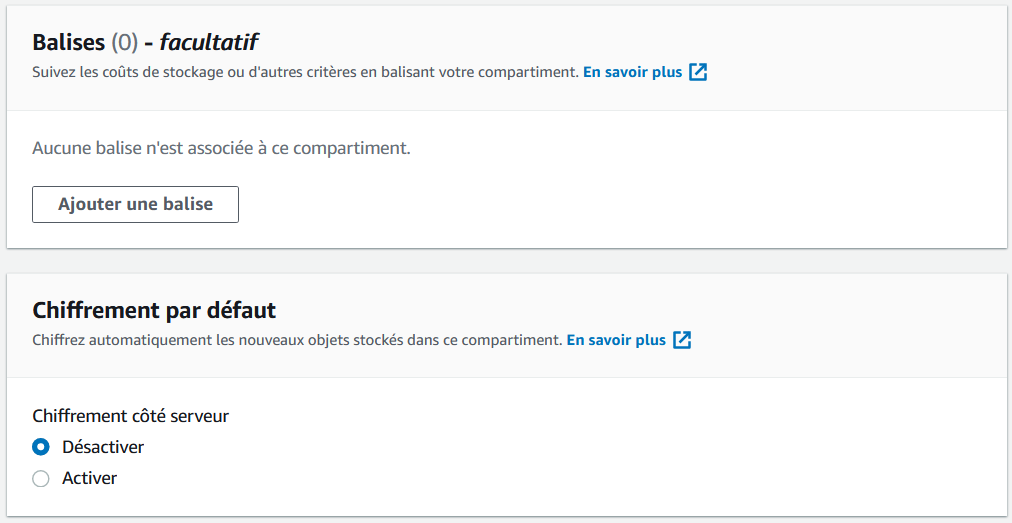
Nous n'allons utiliser aucune de ces options, mais pour information en voici quelques-unes qui pourraient vous intéresser dans le futur :
gestion des versions : permet d'activer le versioning des fichiers. Si vous écrasez un fichier par une nouvelle version, l'ancienne version reste sauvegardée au cas où vous en auriez besoin ;
balises : comme pour les serveurs, les balises vous permettent de "marquer" les compartiments pour les retrouver plus facilement par la suite. C'est une façon de les regrouper par thème ;
chiffrement : vous permet de chiffrer les données, si ce sont des données sensibles.
Comme vous pouvez le voir, par défaut le compartiment n’est pas ouvert au public :
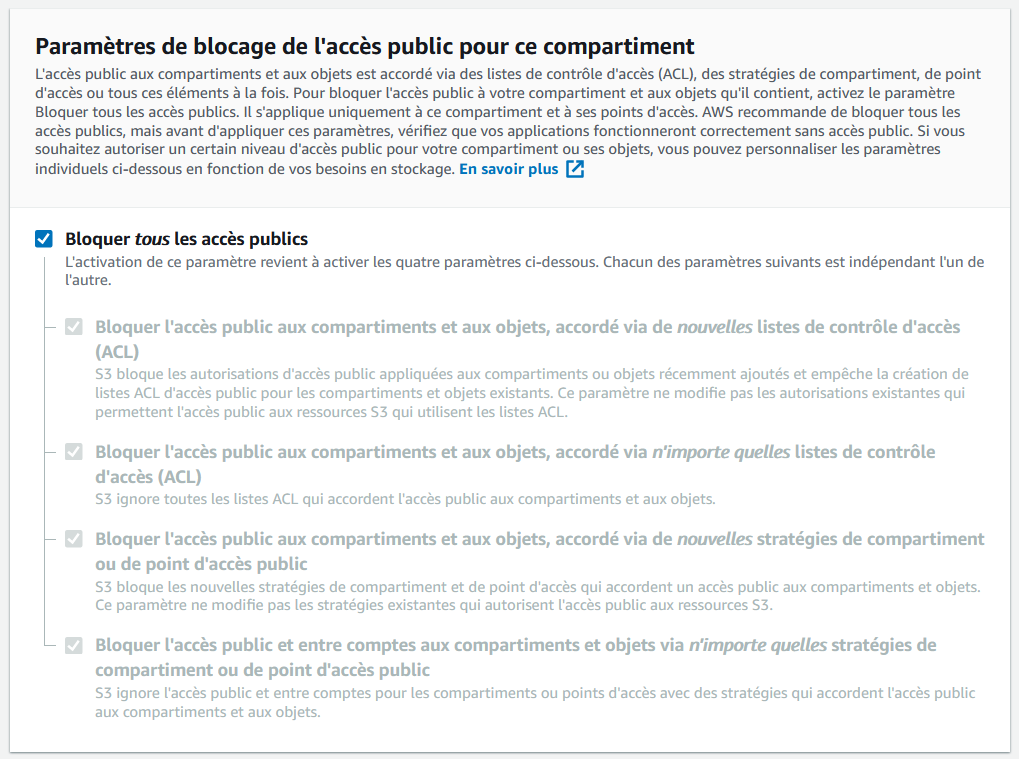
Par défaut, votre utilisateur pourra lire et écrire des objets dans le bucket, modifier sa configuration, etc. Néanmoins, une personne lambda sur Internet ne pourra pas accéder à vos fichiers. C’est la configuration recommandée par défaut, n’y touchez surtout pas.
Mais comment mes utilisateurs pourront-ils télécharger les images de mon site web ?
Pas d’inquiétude, nous verrons comment ouvrir l’accès de manière sécurisée plus tard dans le cours.
À la fin, cliquez sur “Créer un compartiment”.
Après quelques instants, votre bucket est créé :
Ajoutez et modifiez des objets
Cliquez sur le bucket pour rentrer à l'intérieur. Pour l'instant, celui-ci est vide (quelle surprise !) :
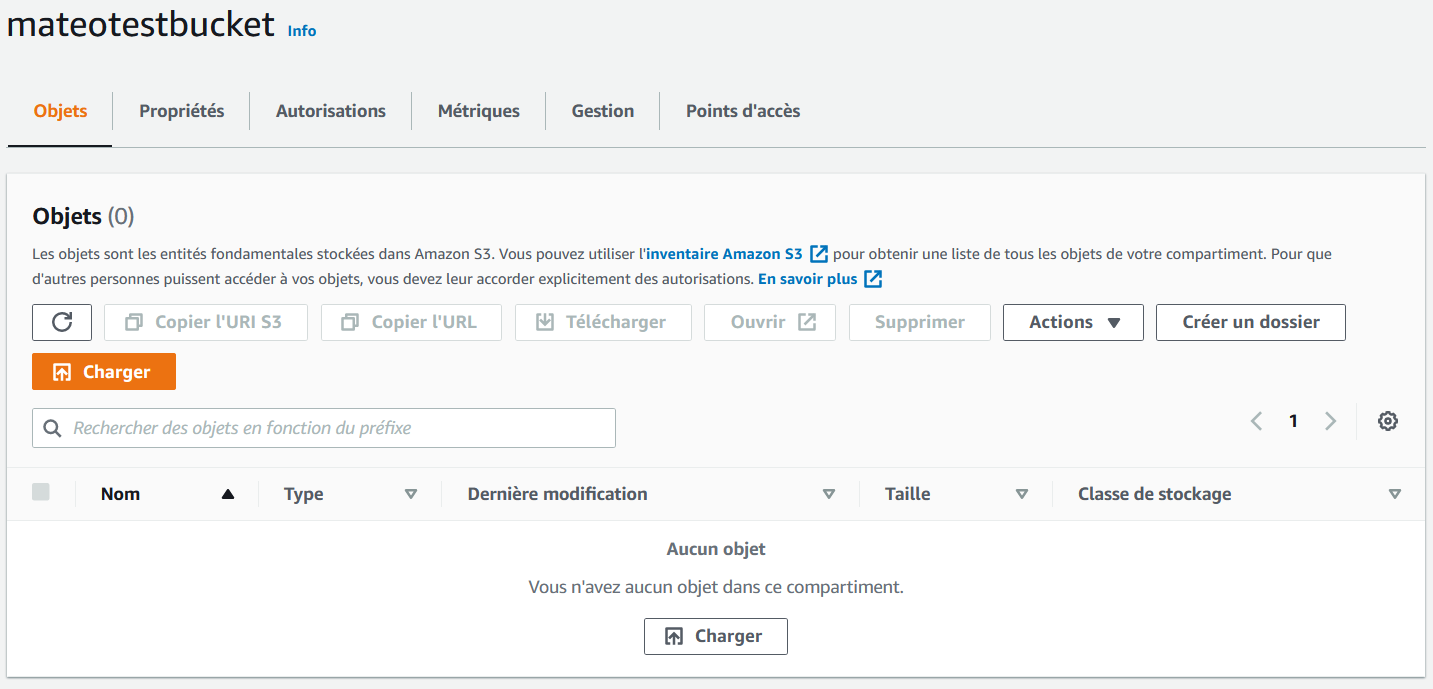
Les onglets tels que "Propriétés" et "Autorisations" vous permettent de modifier le fonctionnement de votre bucket après sa création. Si vous allez dans "Gestion", vous pouvez aussi avoir accès à des statistiques d'utilisation, mettre en place la réplication des données entre datacenters, ou définir une expiration des objets après un certain temps.
Nous allons faire quelque chose de beaucoup plus basique : nous allons charger un fichier dans le bucket. Cliquez sur "Charger" :
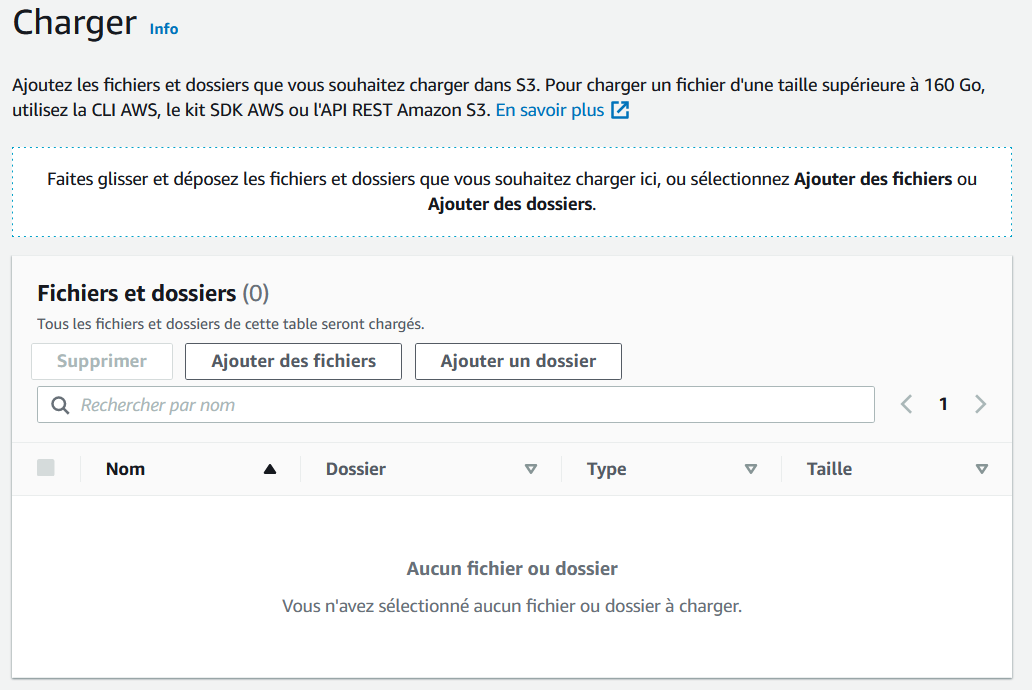
Déposez ce que vous voulez : cela peut être une image, une vidéo, un fichier ZIP...
L'assistant vous propose, si vous le souhaitez, de définir des autorisations et propriétés spéciales pour cet objet. Ce n'est pas obligatoire : par défaut l'objet va prendre les autorisations configurées dans le bucket.
Vous pouvez aussi configurer la classe de stockage de l’objet dans l’objet “Propriétés”. À moins que vous ayez des centaines de Go à charger, gardez tout simplement l’option Standard choisie par défaut.
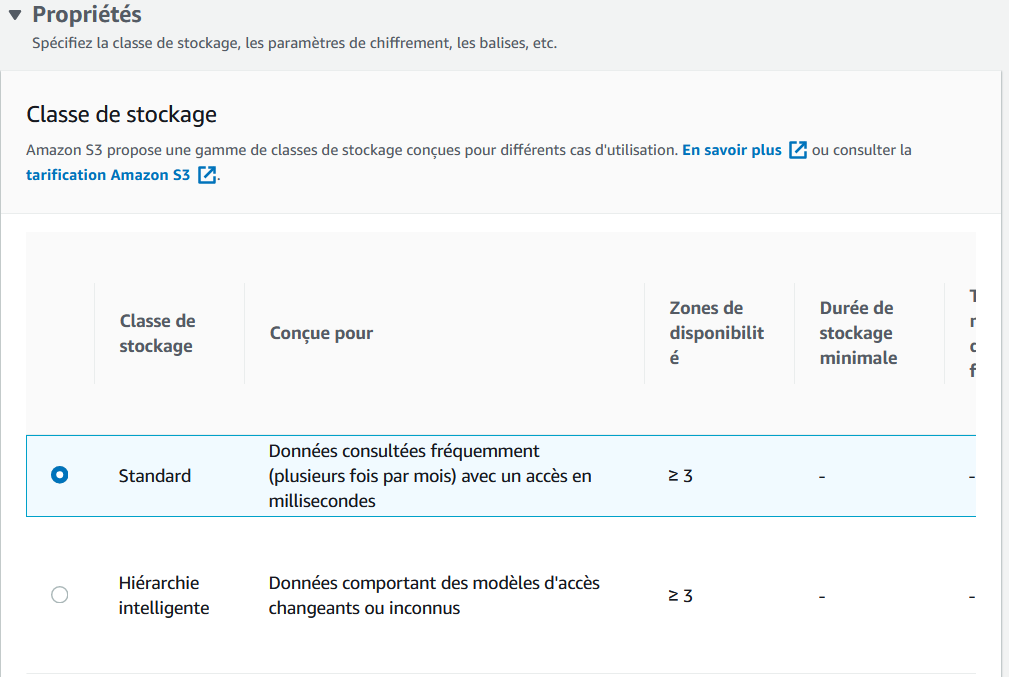
Vous pouvez donc vous contenter de cliquer sur "Charger". C'est tout simple !
J'ai personnellement uploadé une photo de montagne. Voici ce qu'il y a dans mon bucket :
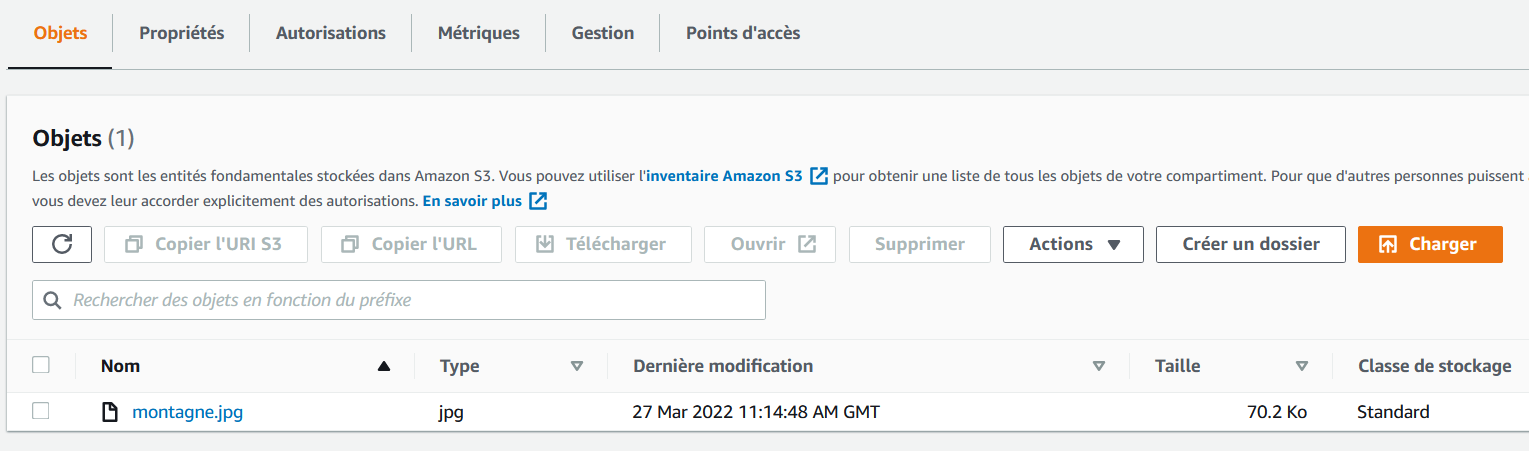
Si vous cliquez sur le fichier, vous verrez plus d'informations :
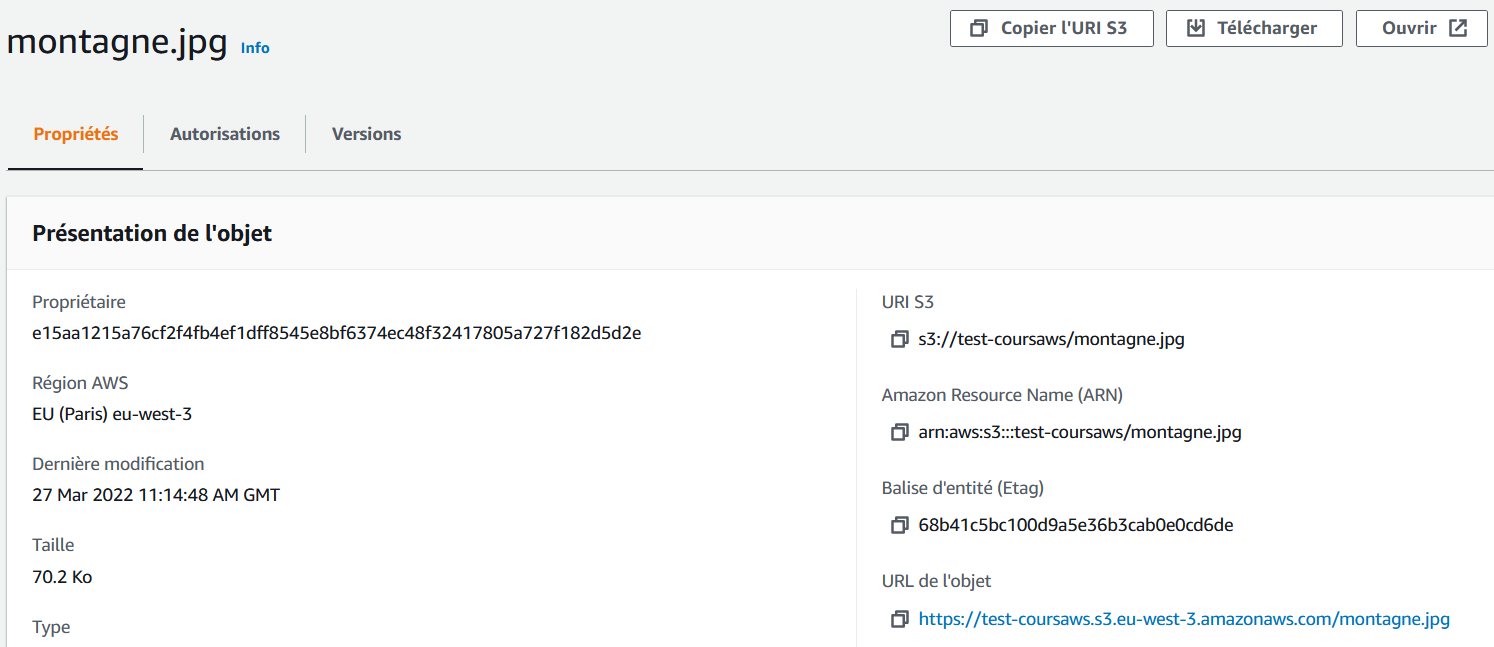
D'ici, vous pouvez le télécharger, modifier ses propriétés, sa classe de stockage, etc.
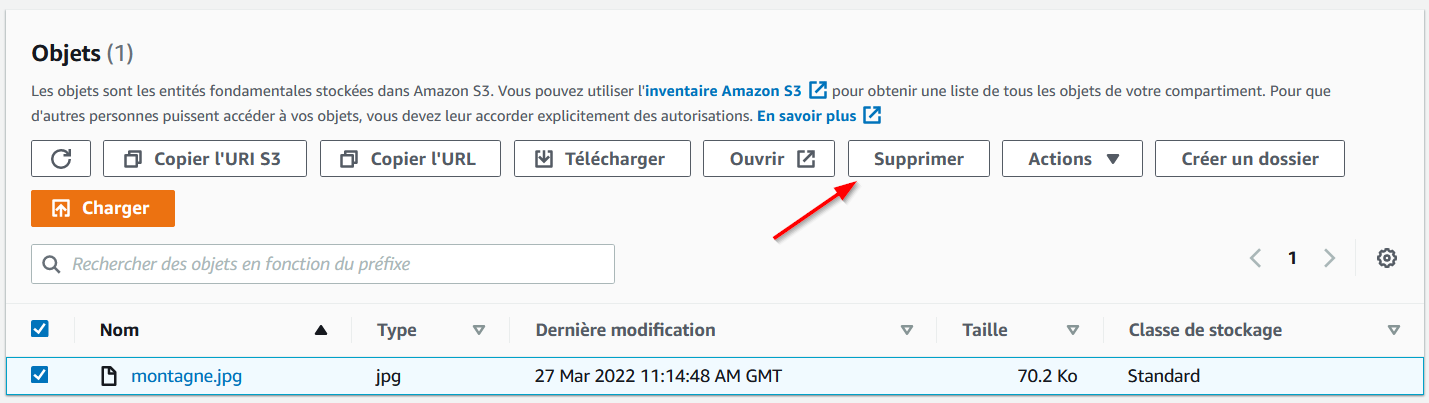
Si vous souhaitez au contraire supprimer le fichier, revenez dans le bucket, sélectionnez le fichier et cliquez sur "Supprimer" :
C'est tout ?... C'est vraiment basique, S3 !
Basique peut-être, mais cela sert à énormément de monde. Stocker un fichier est un besoin universel : pas étonnant que S3 soit si populaire !
En pratique, vous verrez que S3 propose de nombreuses options très pratiques (versioning, chiffrement, réplication...).
Doit-on vraiment passer par l'interface d'AWS pour ajouter et supprimer des fichiers ?
Non ! L'interface d'AWS est pratique, mais en fait on passe généralement par une API. Les API d'AWS sont très bien faites. Celle de S3 peut être utilisée pour charger des fichiers depuis votre site web, comme nous le verrons plus tard.
Mettez en place une règle de cycle de vie
Comme je l’ai mentionné plus haut, il est fréquent d’utiliser S3 pour stocker des backups de site web et base de données. Ce n’est pas cher, surtout si l’on profite des bonnes classes de stockage.
Imaginez que vous fassiez des backups tous les jours. Au bout d’un an, vous allez vous retrouver avec 365 objets…
Est-ce que j'ai vraiment besoin de tout garder ad vitam æternam ?
Peut-être, mais en tout cas AWS nous offre la possibilité de supprimer automatiquement certains fichiers après un certain nombre de jours. Il suffit de configurer une règle de cycle de vie !
Rendez-vous dans la section “Gestion” du bucket et cliquez sur “Créer une règle de cycle de vie”.
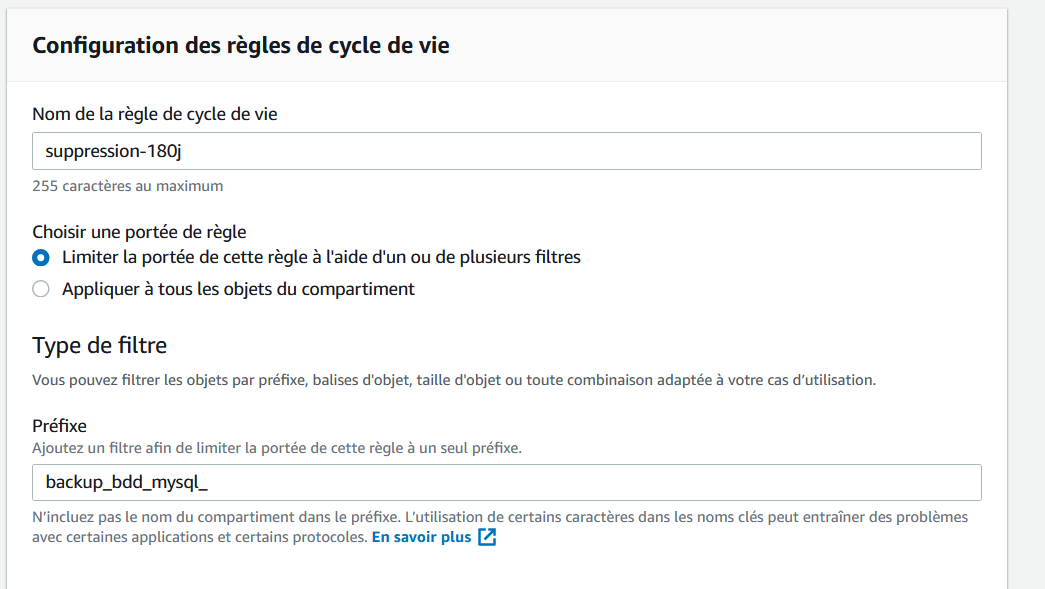
Donnez un nom à votre règle de cycle de vie, et limitez son champ d’application aux objets cibles. Par exemple, nous allons uniquement cibler les objets dont le nom commence par “backup_bdd_mysql_”
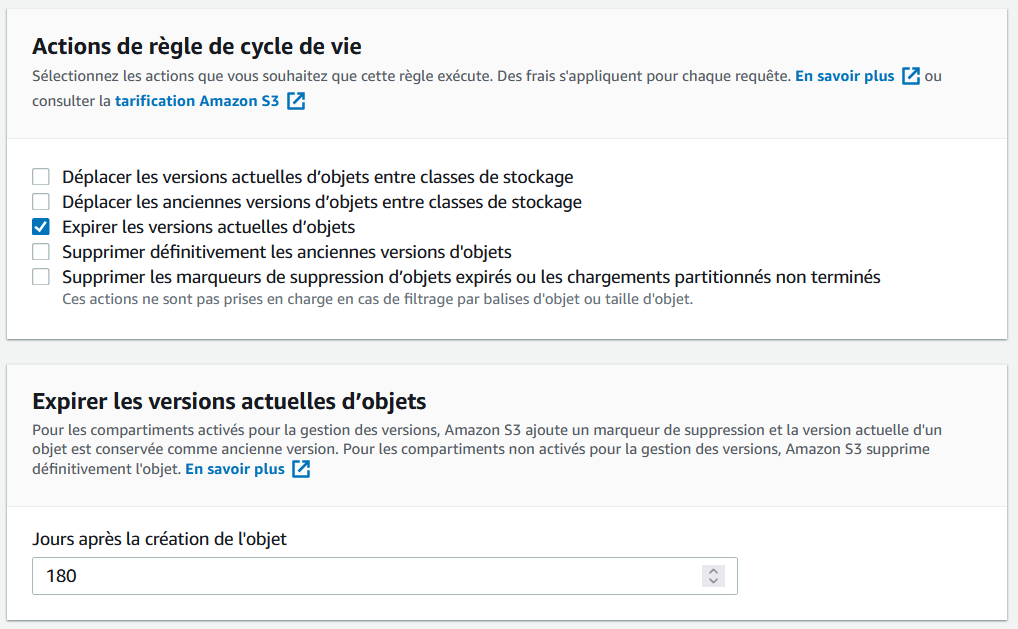
Choisissez ensuite l’action à effectuer au bout de la période choisie. On peut opter pour un changement de la classe de stockage pour réduire les coûts, ou directement pour une suppression de l’objet. On est certain que l’on n’a plus besoin des backups après 180 jours, donc on va cocher la case “Expirer les versions actuelles d’objets”.
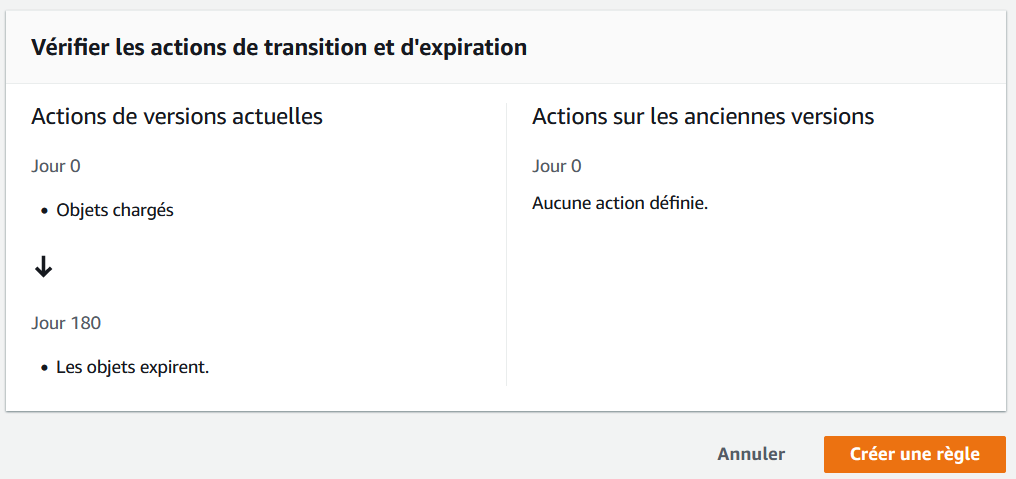
Plus bas nous retrouvons un récapitulatif de la règle de cycle de vie. Si tout est OK, cliquez sur “Créer une règle”.
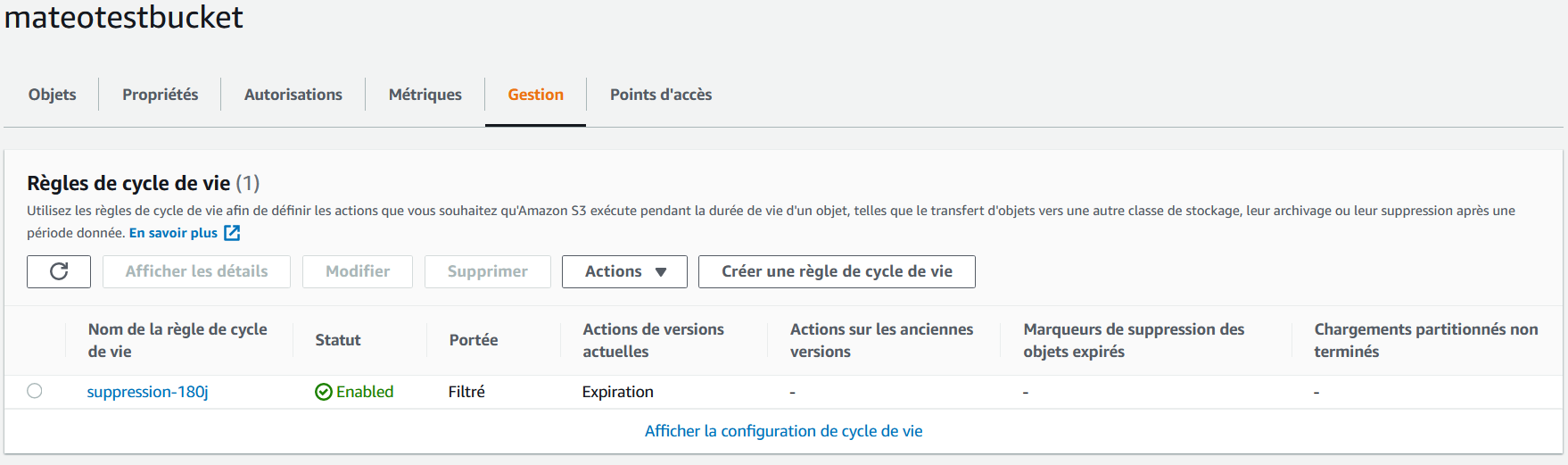
Nous retrouvons notre règle de cycle de vie nouvellement créée dans la section “Gestion” du bucket :
En résumé
Les noms de buckets doivent être uniques dans le monde.
Le dépôt et la suppression des fichiers sur Amazon S3 peuvent s’effectuer depuis la console Amazon S3.
Il est possible de sauvegarder automatiquement chaque version de l'objet déposé sur Amazon S3. Ainsi, si vous supprimez un fichier par erreur, vous pourrez facilement le restaurer sur Amazon S3.
Une règle de cycle de vie est une automatisation qui permet d'appliquer un traitement aux objets si une condition se réalise (ex. : supprimer tous les fichiers déposés il y a 180 jours).
Avant d’aller plus loin dans l’exploration de S3, nous devons faire un petit détour par un service adjacent mais fondamental dans AWS : IAM !
