Découvrez les cellules à mémoire interne : les LSTM
Dans ce chapitre, nous allons découvrir les cellules à mémoire interne : les LSTM et comprendre le mécanisme des portes de contrôle. Ensuite, nous allons assimiler l'utilisation des LSTM en couches et comprendre l'intérêt des LSTM bidirectionnels et multidimensionnels, et leur fonctionnement.
La cellule LSTM : Long Short Term Memory
Comme nous l'avons vu dans le chapitre précédent, afin de modéliser des dépendances à très long terme, il est nécessaire de donner aux réseaux de neurones récurrents la capacité de maintenir un état sur une longue période de temps.
C'est le but des cellules LSTM (Long Short Term Memory), qui possèdent une mémoire interne appelée cellule (ou cell). La cellule permet de maintenir un état aussi longtemps que nécessaire. Cette cellule consiste en une valeur numérique que le réseau peut piloter en fonction des situations.
La figure suivante présente le schéma d'un seul neurone LSTM :
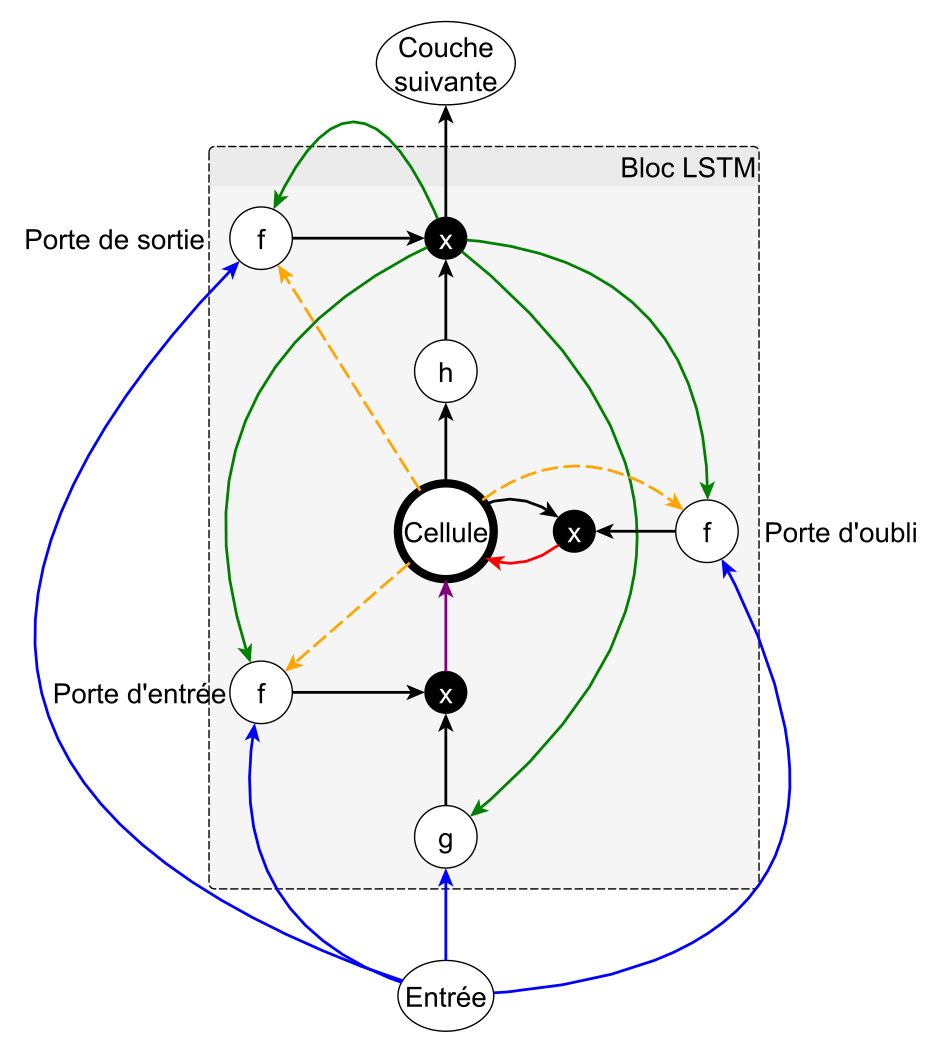
Comme on peut le constater sur le schéma, la cellule mémoire peut être pilotée par trois portes de contrôle qu'on peut voir comme des vannes :
la porte d'entrée décide si l'entrée doit modifier le contenu de la cellule ;
la porte d'oubli décide s'il faut remettre à 0 le contenu de la cellule ;
la porte de sortie décide si le contenu de la cellule doit influer sur la sortie du neurone.
Le mécanisme des trois portes est strictement similaire. L'ouverture/la fermeture de la vanne est modélisée par une fonction qui est généralement une sigmoïde. Cette sigmoïde est appliquée à la somme pondérée des entrées (en bleu), des sorties (en vert) et de la cellule (en orange), par des poids spécifiques à chaque connexion entre les signaux et .
Soient et les entrées et les sorties de la cellule, la valeur de la cellule et les indices décrivant respectivement les signaux issus de la porte d'entrée, d'oubli et de la cellule. sont donc les poids reliant les entrées à la cellule d'entrée, les poids reliant les sorties à la porte d'oubli, etc.
Les équations régissant les trois portes de contrôle sont donc les suivantes ; elles sont l'application de la somme pondérée suivie de l'application d'une activation , typiquement la sigmoïde :
Porte d'entrée :
Porte d'oubli :
Porte de sortie :
Concernant la cellule mémoire, son contenu peut être mis à jour ou remis à 0.
On applique dans un premier temps une somme pondérée des entrées et des sorties :
Le contenu de la cellule à l'instant est ensuite recalculé comme une somme de deux termes :
le premier terme reprend la valeur précédente de la cellule , qui peut être annulée par la valeur de la porte d'oubli ;
le deuxième terme est l'influence de la somme pondérée, pilotée par la valeur de la porte d'entrée .
Pour terminer, la sortie du neurone LSTM est calculée par une activation appliquée à la valeur de la cellule mémoire , pilotée par la valeur de la porte de sortie :
Bien évidemment, l'ensemble des poids sont appris lors de la phase d'apprentissage.
Couches de LSTM
Comme n'importe quel neurone, les neurones LSTM sont généralement utilisés en couches.
Dans ce cas, les sorties de tous les neurones sont réinjectées en entrée de tous les neurones.
Les couches LSTM sont donc généralement combinées avec des couches denses ou des couches convolutionnelles.
Apprentissage des LSTM
Comme nous venons de le constater, les LSTM sont constitués de sommes pondérées, de fonctions d'activations différentiables et de connexions récurrentes.
Ils peuvent donc s'apprendre avec l'algorithme BPTT (Backpropagation Through Time, voir chapitre précédent), comme pour les réseaux récurrents classiques, en dépliant le réseau récurrent à travers le temps.
LSTM bidirectionnels : les BLSTM (Bidirectional - LSTM)
Dans la plupart des problèmes d'analyse de séquence, il est intéressant d'avoir une mémoire du passé pour prendre de bonnes décisions à l'instant . Mais dans certains problèmes de reconnaissance, il est parfois intéressant de regarder les observations futures, lorsque celles-ci sont disponibles !
Si l'on reprend l'exemple suivant, on peut deviner le texte caché en analysant le contexte passé, mais aussi le contexte futur.

Pour ces problèmes, il est possible d'utiliser un réseau appelé BLSTM, qui consiste à dédoubler une couche LSTM, l'une étant apprise pour parcourir le signal de gauche à droite, et l'autre de droite à gauche :
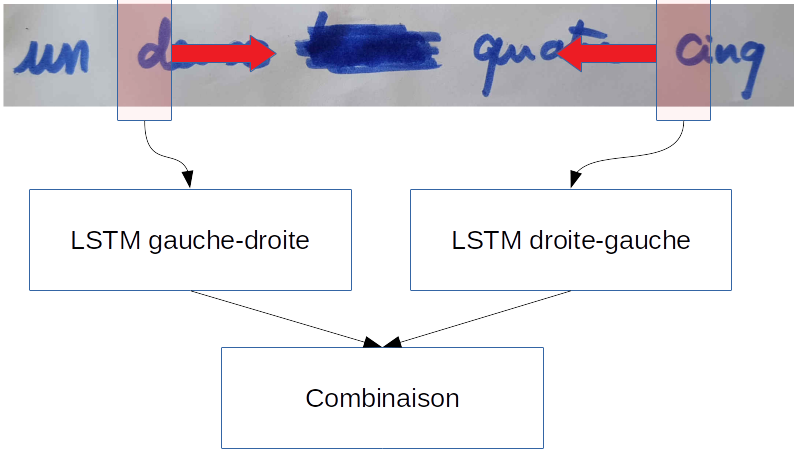
Les deux couches sont combinées afin de prendre les meilleures décisions locales en ayant "vu"... l'intégralité du signal !
Les MDLSTM : Multi-dimensional LSTM
Les Bidirectional-LSTM consistent à parcourir un signal à une dimension selon ses deux directions. Les MDLSTM généralisent ce comportement aux signaux à plusieurs dimensions. Un signal à deux dimensions, tel qu'une image, va donc être parcouru selon 4 directions (deux par dimension) :
haut -> bas ;
bas -> gauche ;
gauche -> droite ;
droite -> gauche.
![Exemple d'utilisation d'un MDLSTM pour la reconnaissance d'écriture, présenté dans l'article [1]. L'image est parcourue dans les 4 directions.](https://user.oc-static.com/upload/2019/04/19/15556575128378_mdlstm.png)
[1] Théodore Bluche, Jérôme Louradour, Ronaldo Messina (2017) Scan, Attend and Read: End-to-End Handwritten Paragraph Recognition with MDLSTM Attention. In 14th International Conference on Document Analysis and Recognition (ICDAR), 2017.
Les MDLSTM permettent ainsi de modéliser les dépendances dans des signaux, quelle que soit leur dimension.
Comme on peut le constater sur la figure précédente, des couches de LSTM sont souvent combinées avec d'autres types de couches neuronales (ici, des couches convolutionnelles et des couches denses).
Dans le chapitre suivant, nous allons présenter comment ces types de couches peuvent être combinés afin de s'adapter aux signaux à traiter et aux problèmes considérés.
Allez plus loin
Alex Graves: Supervised sequence labelling with recurrent neural networks. Technical University Munich 2008, pp. 1-117.
Alex Graves, Jürgen Schmidhuber: Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. NIPS 2008: 545-552.
Kyunghyun Cho, Bart van Merrienboer, Çaglar Gülçehre, Fethi Bougares, Holger Schwenk, Yoshua Bengio: Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. CoRR abs/1406.1078 (2014).
En résumé
Dans ce chapitre, nous avons présenté une version améliorée des réseaux de neurones récurrents simples : les LSTM, capables de modéliser des dépendances à très long terme.
Les LSTM reposent sur un mécanisme de mémoire interne piloté par des portes de contrôle. Tous les éléments étant différentiables, ces réseaux s'apprennent par une rétropropagation à travers le temps classique.
Nous avons également présenté l'utilisation des LSTM dans des architectures bidirectionnelles et multidimensionnelles, afin de modéliser les dépendances dans plusieurs directions au sein d'un même modèle.
