Maitrisez les algorithmes d'apprentissage des réseaux récurrents
Dans ce chapitre, nous allons voir que la récurrence interdit l'utilisation des algorithmes classiques d'apprentissage de réseaux de neurones. Ensuite, nous allons découvrir l'algorithme "Rétropropagation à travers le temps" permettant l'apprentissage des RNN. Finalement, nous allons comprendre les dangers à éviter pour maîtriser l'apprentissage.
La problématique de l'apprentissage d'un réseau récurrent
Reprenons le réseau récurrent simple et classique vu dans le chapitre précédent, constitué d'une couche récurrente suivie d'une couche dense :
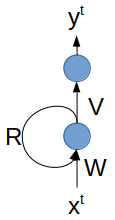
Rappelons qu'il comprend trois matrices de poids : , et ; étant la matrice des poids récurrents. L'apprentissage du réseau consiste donc à apprendre ces trois matrices sur une base d'exemples étiquetés.
Nous avons vu lors du cours précédent l'algorithme d'apprentissage des réseaux de neurones feedforward, appelé rétropropagation du gradient. Cet algorithme rétropropage le gradient de l'erreur à travers les différentes couches de poids du réseau, en remontant de la dernière à la première couche.
La solution : la rétropropagation à travers le temps
La solution à ce problème consiste à exploiter la version dépliée du réseau, qui élimine les cycles.
Nous allons donc utiliser une approximation du réseau récurrent par un réseau déplié fois, comme présenté sur la figure suivante avec :
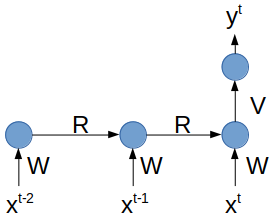
Rappelons qu'un réseau déplié fois ne permet de "mémoriser" qu'un passé limité à échantillons. Il est donc théoriquement moins performant que le vrai réseau récurrent pour modéliser les dépendances.
Mais une fois déplié, le réseau ne comporte plus de cycle, et on peut lui appliquer la rétropropagation standard ! L'utilisation combinée du dépliement à travers le temps et de la rétropropagation standard est appelée rétropropagation à travers le temps, ou BackPropagation Through Time (BPTT), en anglais.
La seule différence entre une rétropropagation standard et une rétropropagation à travers le temps est le partage des poids et . Pour cela, on force ces poids à être identiques pour chaque pas de temps, à la manière de l’apprentissage des réseaux convolutionnels.
Les dangers de la rétropropagation à travers le temps : disparition et explosion du gradient
Comme on a pu le constater sur la figure précédente, la transformation du réseau récurrent en un réseau non récurrent déplié rend celui-ci plus profond !
Dans l'exemple proposé, le réseau récurrent de profondeur 2 est transformé en un réseau de profondeur 4 (nombre maximum de couches de poids entre l'entrée et la sortie, ici entre et ). D'une manière générale, on augmente de la profondeur du réseau lorsqu'on le déplie.
Le choix de la valeur de doit donc être fixé pour la phase d'apprentissage. Un trop faible ne permettra pas de modéliser les dépendances temporelles au sein des signaux, alors qu'un trop grand ralentira considérablement l'apprentissage. Des valeurs "classiques" de varient entre 10 et 100, en fonction de la nature des signaux traités.
Mais ce n'est pas tout !
La maîtrise de la norme du gradient au sein des réseaux récurrents permet de modéliser des dépendances importantes (de l'ordre de plusieurs dizaines de pas de temps) au sein des signaux. Les réseaux récurrents sont aujourd'hui la méthode de référence pour traiter des séquences de type écriture manuscrite, parole, séries temporelles, etc.
Les limites des réseaux récurrents "simples"
Les réseaux récurrents que nous venons de décrire sont appelés simples (ou Vanilla RNN en anglais).
En effet, même en utilisant une valeur de suffisamment importante, une observation lointaine dans le passé n'aura que peu d'impact sur la décision du réseau à l'instant courant. La raison à cela est que les réseaux récurrents simples n'ont pas la capacité de maintenir un état au cours du temps.
La solution à ce problème consiste à donner aux réseaux récurrents la possibilité de contrôler un état interne en fonction du contexte passé. C'est le rôle des réseaux de neurones à mémoire interne, tels que les cellules LSTM (Long Short Term Memory) ou GRU (Gated Recurrent Unit), que nous détaillerons dans le chapitre suivant.
Apprentissage embarqué
Un des problèmes pour l'apprentissage des réseaux de neurones récurrents est la nécessité d'avoir les bonnes sorties pour tous les instants de temps de la séquence.

En plus d'être fastidieux, il est fréquent d'avoir certaines fenêtres où l'étiquette de la sortie est difficile à déterminer, par exemple lorsque la fenêtre est à cheval sur plusieurs caractères ('?').
Heureusement, il existe un algorithme, appelé CTC pour Connexionist Temporal Classification, permettant d'obtenir des étiquettes au niveau "fenêtres" à partir de l'étiquette au niveau "séquence".
L'utilisation de l'algorithme CTC nécessite donc seulement l'étiquette au niveau séquence, ce qui est beaucoup plus raisonnable !

Nous ne rentrerons pas ici dans le détail de cet algorithme, fortement inspiré de l'algorithme plus général "forward-backward". Il faut savoir qu'il s'agit d'un algorithme itératif qui cherche à estimer alternativement les paramètres du modèle et les étiquettes probabilisées associées aux fenêtres.
On appelle parfois ce type d'apprentissage un apprentissage embarqué.
Allez plus loin
Razvan Pascanu, Tomas Mikolov, Yoshua Bengio. On the difficulty of training recurrent neural networks. ICML (3) 2013: 1310-1318.
Sepp Hochreiter, Jürgen Schmidhuber: LSTM can Solve Hard Long Time Lag Problems. NIPS 1996: 473-479.
Alex Graves, Santiago Fernández, Faustino J. Gomez, Jürgen Schmidhuber:
Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. ICML 2006: 369-376.
En résumé
Dans ce chapitre, nous avons présenté l'algorithme de la rétropropagation à travers le temps, permettant d'apprendre les réseaux de neurones simples.
Cet algorithme repose sur le dépliement du réseau de neurones récurrent à travers le temps afin de rompre les cycles, et ainsi permettre l'application de la rétropropagation classique. Nous avons vu des méthodes simples mais indispensables, permettant d'éviter les problèmes de disparition et d'explosion du gradient.
Les réseaux récurrents simples sont cependant limités dans la modélisation des dépendances à long terme, à cause de l'absence de mémoires internes.
