Extrayez et transformez des données avec l’extraction web
Qu’est-ce que l’extraction de données web ?
L'extraction de données web, c'est génial ! Imaginez que vous soyez un expert en marketing, en train de préparer une campagne pour une nouvelle veste à la mode. Vous voulez connaître le prix et la description des vestes similaires pour pouvoir ajuster votre stratégie. Mais pas besoin de perdre des heures à fouiller sur internet ! Avec Python, vous pouvez écrire des petits programmes qui vont chercher ces informations à votre place, et les enregistrer dans un fichier CSV. Fini les copier-coller manuels dans un tableur ennuyeux, faites confiance à la magie de Python pour vous faire gagner du temps et de l'énergie !
Vous êtes prêt pour un exercice d'extraction de données ? Dans les deux chapitres à venir, je vais vous montrer comment extraire des nouvelles et des communications du site web du gouvernement britannique. Vous allez apprendre de nouvelles choses, pratiquer à l'aide des outils que vous avez déjà utilisés, et devenir un pro de l'extraction de données. Et on ne va pas s'arrêter là, on va transformer ces données en un format de notre choix, et les charger dans un fichier CSV.
ETL : Extraire, Transformer, Charger
ETL signifie extraction, transformation et chargement (Extract, Transform, Load, en anglais). En d'autres termes, c'est une manière sophistiquée de dire que vous collectez des données d'un endroit, que vous les arrangez et que vous les stockez ailleurs. L'extraction de données web est un exemple d'ETL, où vous récupérez des données d'un site web, les formatez comme vous le souhaitez, et les stockez dans un fichier CSV ou une base de données.
Pour extraire des données en ligne, vous aurez besoin de comprendre un peu d'HTML et la structure de chaque page web. Mais pas de panique, ce chapitre vous expliquera tout ce dont vous avez besoin pour vous lancer dans l'extraction de données.
Lisez les balises HTML essentielles
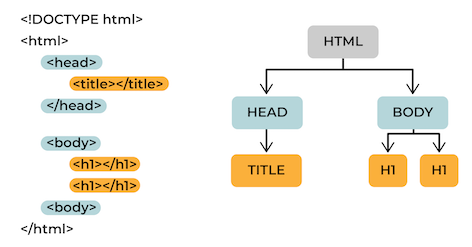
Le HTML, c'est le langage qui fait marcher le web ! Si vous voulez voir ses tripes, faites un clic droit et choisissez "Voir la page source" (ou "Afficher le code source"). Le HTML suit une structure en arborescence nommée DOM (Document Object Model). Cela signifie qu'il y a des balises pour tout, et que la plupart des éléments ont une balise d'ouverture et de fermeture.
Une balise d’ouverture ressemble à ça : <nom_element> . Une balise de fermeture a le même nom_element , mais avec / devant : </nom_element> . Par exemple, chaque page a une balise d’ouverture <html> et une balise de fermeture </html> . Toutes les informations que vous voulez dans cet élément doivent être entre ces deux balises.
Le package Requests
Pour extraire des données à partir d’un site web, nous devons utiliser le package Requests. Rappelez-vous qu’il fournit la fonctionnalité de faire des requêtes HTTP. Nous pouvons l’utiliser puisque nous essayons d’obtenir des données à partir d’un site web qui utilise le protocole HTTP (par exemple, http://google.com).
Le package Requests contient une fonction .get() qui peut être utilisée pour récupérer le code HTML du site.
Pour appliquer ça à l’exercice d’extraction de données web, nous allons utiliser le package Requests pour obtenir le code HTML de la page d’informations et de communication britannique. Dans le code ci-dessous, nous importons le package, nous sauvegardons l’URL que nous voulons extraire dans une variable url , et nous utilisons la méthode .get() pour récupérer les données HTML. Si vous exécutez le code ci-dessous, vous verrez le code source HTML affiché dans la console.
import requests
url = "https://www.gov.uk/search/news-and-communications"
page = requests.get(url)
# Voir le code html source
print(page.content)Même si nous avons récupéré tout le code HTML dans notre code, c’est toujours incompréhensible. Il nous faut encore savoir comment parser les éléments exacts que nous voulons. Et nous pouvons utiliser Beautiful Soup pour faire ça !
Le package Beautiful Soup
Maintenant que nous avons le code source HTML, nous devons le parser. On parse le HTML avec les attributs HTML class et id mentionnés plus tôt.
Nous pouvons utiliser Beautiful Soup pour trouver les éléments qui peuvent être identifiés avec la classe et l’id que nous voulons trouver. Comme pour n’importe quel package, nous allons utiliser pip pour installer Beautiful Soup.
pip install beautifulsoup4Ensuite, nous allons importer Beautiful Soup et créer un objet « soup » à partir du HTML que nous avons eu avec les requêtes. Pour rendre l'opération plus rapide, nous allons directement lire un fichier HTML local, disponible sur le répertoire GitHub.
import requests
from bs4 import BeautifulSoup
from bs4 import BeautifulSoup
with open("index.html", "r") as file:
soup = BeautifulSoup(file.read(), 'html.parser')La variable soup que nous avons créée avec Beautiful Soup possède toutes les fonctions qui facilitent l’obtention de données à partir de HTML. Avant de récupérer les données de la page d’informations et de communication britannique, nous allons parcourir certaines fonctionnalités de Beautiful Soup avec l’extrait HTML ci-dessous.
<html>
<head><title>Les chiens les plus mignons</title></head>
<body>
<p class="title"><b>Les meilleures races de chiens</b></p>
<p class="chiens">
<a href="http://exemple.com/labradoodle" class="race" id="lien1">LabraDoodle</a>,
<a href="http://exemple.com/retriever" class="race" id="lien2">Golden Retriever</a> et
<a href="http://exemple.com/carlin" class="race" id="lien3">Carlin</a>
</p>
</body>
</html>La variablesoupque nous avons créée avec Beautiful Soup possède toutes les fonctions qui facilitent l’obtention de données à partir de HTML.
Nous allons maintenant découvrir les fonctionnalités les plus intéressantes de BeautifulSoup.
Récupération du titre de la page HTML:
`soup.title`
==> `<title>Exercice extraction HTML</title>` (un élément HTML)
Récupération de la chaîne de caractères du titre HTML
`soup.title.string`
==> "Exercice extraction HTML"
Trouver tous les éléments avec la balise <h2>
`soup.find_all('h2')`
==> renvoie une liste d'éléments HTML
Trouver le premier élément avec l’id `titre`
`soup.find(id="titre")`
==> <h1 id="titre">Bienvenue sur notre site web</h1>
Trouver tous les éléments <li>:
`soup.find_all("li")`
Trouver tous les éléments <li> avec la classe "product" en utilisant un sélecteur CSS:
`soup.select("li.product")`
==> renvoie une liste d'éléments HTMLEt ce n’est qu’un aperçu de la façon dont Beautiful Soup peut vous aider à obtenir facilement les éléments spécifiques que vous voulez à partir d’une page HTML. Vous pouvez obtenir des éléments par leur balise, id ou classe.
À présent, utilisez le modulebeautifulsoup4pour extraire des informations du fichier "index.html".
Pour lire le contenu du fichierindex.html, vous pouvez utiliser le code suivant :
with open("index.html", 'r') as file:
soup = BeautifulSoup(file, 'html.parser')1/ Récupérez les éléments suivants dans le code html et stockez-les dans des variables, puis affichez-les dans la console :
le titre de la page (<title> )
le texte de la balise <h1> avec ID "titre"
les informations sur les produits :
nom du produits
prix du produit (par exemple: 20€)
description
utilisez un dictionnaire pour stocker ces informations pour tous les produits.
2/ Nettoyez les prix des produits pour ne garder qu'un nombre (retirez le motprix, et:). Vous pouvez utiliser la fonction Pythonsplit.
3/ Convertissez les prix en euro vers le dollar (considérez que le prixdollar = euro * 1.2).
4/ Affichez les produits avec le prix en dollars (par exemple: 20$).
Maintenant que vous avez réussi à extraire des données web, vous allez les transformer dans le format dans lequel vous voulez les sauvegarder.
Transformez des données
Vous transformez des données quand vous les convertissez d’un format à l’autre. Ça peut être aussi simple que de convertir une chaîne de caractères en une liste, mais ça peut aussi concerner la transformation de milliers de listes en dictionnaires. Généralement, ça nécessite d’associer différents points de données. Il y a plusieurs façons de transformer des données, et la décision dépend finalement du type de données et du format que vous voulez avoir.
Voici quelques exemples de transformation de données :
Convertir un format de champ de date de « 28 décembre 2019 » à 28/12/19.
Convertir une somme d’argent de dollars en euros.
Standardiser les adresses e-mail ou postales. descriptions_bs=soup.find_all("p", class_="gem-c-document-list__item-description")
A vous de jouer

Contexte
Dans cet exercice, vous allez extraire des informations d'un fichier HTML à l'aide du package Beautiful Soup.
Consignes
Réutilisez le code précédent pour obtenir les informations sur les produits (et le dictionnaire associé)
Affichez les informations extraites dans la console.
Transformez ensuite le prix en dollars, et ajoutez l’information au dictionnaire pour chaque produit (considérez que le prix dollar = euro * 1.2)
Affichez les données transformées.
En résumé
L’extraction de données web est un processus automatisé de récupération des données d’internet.
ETL signifie extraction, transformation et chargement. C’est un sigle très utilisé dans la programmation pour désigner le processus de récupération de données d’un endroit, de modification légère de ces données, et de leur sauvegarde dans un autre endroit.
HTML est la structure de n’importe quelle page web, et la compréhension de cette structure va vous aider à savoir comment récupérer les données dont vous avez besoin.
Requests et Beautiful Soup sont des packages Python tiers qui peuvent vous aider à récupérer et parser les données d’internet.
Parser des données signifie les préparer pour les transformer, les sauvegarder ou les utiliser.
Maintenant que vous avez vu comment extraire et transformer des données web, vous allez apprendre à charger des données web !
