Comprenez les enjeux de l’analyse bivariée
Vous êtes maintenant capable d’étudier toutes les variables l’une après l’autre. Bravo, vous êtes donc un pro de l’analyse univariée.
J’ai étudié toutes les variables, c'est tout bon ! Mais alors pourquoi il reste des chapitres à ce cours ? :o
Eh bien non, ce n’est pas fini. Dans cette troisième partie, nous allons étudier les relations entre deux variables. C’est l’analyse bivariée. Pour certains chapitres, il faudra vous accrocher. Mais si vous êtes arrivé jusqu'ici, vous ne devriez normalement pas avoir trop de soucis. De plus, c'est à partir d'ici que l'analyse des relevés de comptes devient intéressante !
Découvrez l'intérêt de l'analyse bivariée
Pourquoi étudier les relations entre variables ?
Petit exemple. Vous travaillez pour un site web de e-commerce. Vous avez accès à la base de données des clients du site, ainsi qu'aux données de navigation sur le site. Grâce aux données de navigation, vous pouvez savoir quel client a consulté quelle page sur le site, combien de temps il a passé sur chaque page, etc. Dans le but de créer un algorithme de recommandation (qui proposera de nouveaux produits aux clients), vous décidez de faire une petite étude préliminaire.
Grâce aux données de navigation, vous pouvez sélectionner un échantillon de clients qui consultent souvent les derniers albums musicaux de variété française. Vous décidez alors de déterminer l'intérêt qu'ils portent au nouvel album d'un chanteur populaire, en modélisant cet intérêt par un score allant de 0 à 10 sur une échelle continue :
Si un client donné n'a jamais visité la page qui présente ce nouvel album, vous lui attribuez le score intermédiaire de 5.
S'il a souvent visité la page de cet album, qu'il y est resté longtemps, et qu'il a finalement acheté l'album, vous lui attribuez le score de 10.
Au contraire, s'il a consulté la page, qu'il n'y est pas resté longtemps, et qu'il n'a pas acheté l'album lors de sa dernière commande sur le site, alors c'est qu'il semble ne pas aimer ce nouvel album. Vous lui attribuez donc le score de 0.
Vous connaissez l'âge de chaque client. Vous obtenez donc un échantillon de clients caractérisés par 2 variables : l'âge et le niveau d'intérêt.
Vous décidez donc d'étudier ces 2 variables séparément, avec des histogrammes :

Ces histogrammes montent que les âges sont assez bien répartis sur cet échantillon : il y a à peu près autant de personnes jeunes que de personnes plus âgées. Quant au niveau d'intérêt, il y a également autant de personnes qui s'intéressent au nouvel album que de personnes qui n'y portent pas d'intérêt.
Bon. C’est déjà bien de savoir cela, mais nous allons voir que nous pouvons faire beaucoup mieux !
Maintenant, plaçons sur un graphique en 2 dimensions les individus de notre échantillon. Chaque point de ce graphique représente une personne. La position de chaque point peut être repérée selon 2 axes : l’axe des abscisses (horizontal), et l’axe des ordonnées (vertical). L’abscisse d’un point, c’est un nombre. Si ce nombre est grand, alors ce point sera très à droite du graphique, mais s’il est proche de 0, alors il sera très à gauche. C’est pareil pour l’ordonnée du point : si elle est élevée, le point sera très haut, mais si elle est proche de 0, le point sera très bas.
Ici, on place la variable âge en abscisse et celle du niveau d'intérêt en ordonnée. Un point qui sera en haut à droite représentera donc une personne plutôt âgée très intéressée par le nouvel album. Au contraire, un point qui sera en bas à gauche représentera une personne jeune n'aimant pas l'album.
En fait, plusieurs cas sont possibles. Voici 2 exemples un peu extrêmes :

Dans le cas A, beaucoup de personnes âgées aiment ce nouvel album, et beaucoup de personnes jeunes ne l'aiment pas. Ainsi, votre algorithme de recommandation devra conseiller ce nouvel album aux personnes plutôt âgées, et ne pas le recommander aux personnes jeunes (mieux vaudra leur proposer des produits qu'elles sont plus susceptibles d'aimer).
Dans le cas B, c’est l’inverse. Il faut conseiller cet album aux personnes jeunes et ne pas le faire pour les personnes âgées.
Vous l’aurez compris, on obtient en général beaucoup plus d’informations en étudiant les relations entre 2 variables qu’en étudiant séparément 2 variables ! Sans l’analyse bivariée, vous auriez été incapable de savoir à qui recommander (ou non) l'album !
Un autre exemple : un célèbre site de formations en ligne publie des cours, dans lesquels les étudiants doivent répondre à des quiz. Pour réussir un quiz, il faut 70 % de réponses correctes. Pour un quiz de 8 questions, il faut donc répondre correctement à au moins 6 questions pour réussir.
L’échantillon des étudiants ayant répondu au quiz est un échantillon à 8 variables. Elles sont toutes binaires (réponse bonne/réponse fausse). Pour l’un des quiz du cours intitulé Initiez-vous à l’algèbre relationnelle avec SQL, voici ces 8 variables représentées :
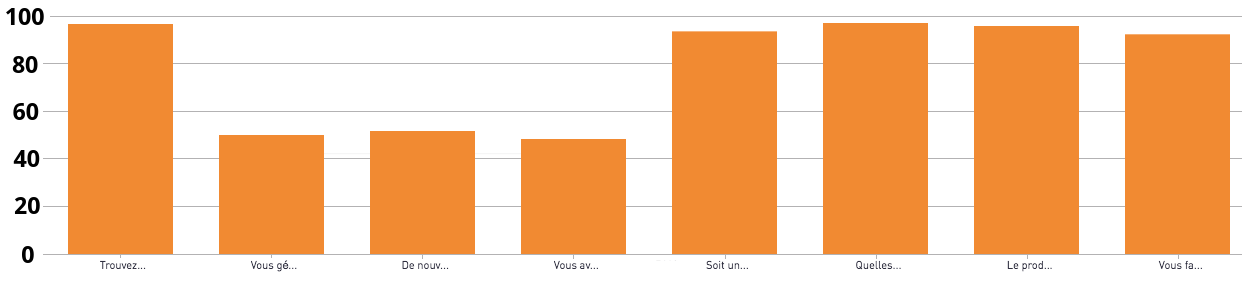
5 questions sur 8 ont un taux de réussite proche de 100 %. Les 3 autres questions ont un taux de réussite proche de 50 %. Ce graphique montre 8 analyses univariées. Mais ici, il nous faudrait étudier les relations entre ces variables. En effet, parmi les 50 % d’étudiants qui ont raté la question 2, je ne sais pas combien ont réussi la question 3, et c’est problématique car :
Si les 50 % qui ont raté la question 2, les 50 % qui ont raté la 3, et les 50 % qui ont raté la 4 sont les mêmes étudiants, alors cela signifie que 50 % d’étudiants au total ont raté le test (avec chacun 3 réponses fausses). Le taux de réussite globale au test est donc de 50 %, et il faudrait alors simplifier l’énoncé du quiz.
Si cependant les 50 % qui ont raté la question 2 sont tous parmi les 50 % qui ont réussi la question 3, alors ceux-ci auront probablement tous réussi le quiz (quel que soit leur résultat à la question 4, ils auront presque tous un score global de 6/8 ou 7/8). Ainsi, le taux de réussite globale du quiz sera proche de 100 %, ce qui est un bon taux !
En résumé
L'analyse bivariée est une analyse menée entre deux variables.
Elle permet d'établir des recommandations métier pertinentes sur les individus à partir de la compréhension du comportement d'une variable par rapport à une autre.
Commençons l'analyse bivariée par la recherche des corrélations dans le chapitre suivant ! Vous êtes prêt ?
