Analysez une variable quantitative et une qualitative par ANOVA
Dans les 2 chapitres précédents, nous avons étudié les corrélations entre 2 variables quantitatives. Maintenant, passons à l'étude de deux variables dont l'une est qualitative, l'autre quantitative.
Définissez quelles questions se poser
En fonction des couples de variables que nous utiliserons, la méthode d'analyse sera la même, mais nous pourrons répondre à différentes questions intéressantes :
Les dépenses que vous faites le week-end sont-elles plus grosses qu'en semaine ? (Variables montant et weekend).
Les dépenses que vous faites en début de mois sont-elles plus grosses qu'en fin de mois ? (montant et quart_mois).
Le montant d'une opération est-il différent d'une catégorie de dépense à l'autre ? (montant et categ).
Vos paiements en carte bancaire sont-ils toujours petits, et vos virements importants ? (type et montant).
Le solde de votre compte est-il plus petit en fin de mois qu'en début de mois ? (solde_avt_operation et quart_mois).
Créez des graphiques
Voici le code qui permet de représenter une variable quantitative et une variable qualitative. Tout d'abord, créez le sous-échantillon sur lequel vous souhaitez travailler en adaptant ce code, notamment les variables X et Y selon la question que vous aurez choisie parmi celles ci-dessus.
X = "categ" # qualitative
Y = "montant" # quantitative
# On ne garde que les dépenses
sous_echantillon = data[data["montant"] < 0].copy()
# On remet les dépenses en positif
sous_echantillon["montant"] = -sous_echantillon["montant"]
# On n'étudie pas les loyers car trop gros:
sous_echantillon = sous_echantillon[sous_echantillon["categ"] != "LOYER"] Ensuite, ces quelques lignes de code affichent votre graphique !
modalites = sous_echantillon[X].unique()
groupes = []
for m in modalites:
groupes.append(sous_echantillon[sous_echantillon[X]==m][Y])
# Propriétés graphiques (pas très importantes)
medianprops = {'color':"black"}
meanprops = {'marker':'o', 'markeredgecolor':'black',
'markerfacecolor':'firebrick'}
plt.boxplot(groupes, labels=modalites, showfliers=False, medianprops=medianprops,
vert=False, patch_artist=True, showmeans=True, meanprops=meanprops)
plt.show() 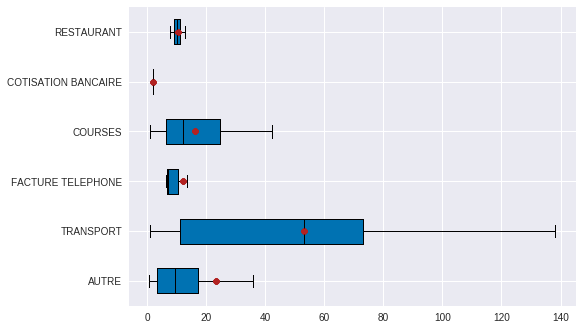
On voit ici que les montants sont très différents d'une catégorie à l'autre. Par exemple, les montants des dépenses de transport sont plus élevés et plus dispersés que ceux des factures téléphoniques. Mais vérifions maintenant cette affirmation par les chiffres, grâce à une modélisation.
Modélisons
Revenons sur la démarche que nous avons eue au chapitre précédent. Pour voir s'il existait une corrélation (linéaire) entre 2 variables, nous avons supposé que cette corrélation existait, puis nous avons appliqué un modèle sur cette supposition. Nous avons ensuite estimé les paramètres et . Enfin, nous avons vérifié la supposition de départ en évaluant la qualité du modèle. Si ce modèle est de bonne qualité, alors c'est qu'il y a une forte corrélation entre X et Y. En bonus, nous avons profité de la formule de la régression linéaire pour interpréter comme la somme d'argent consommée en 1 jour, et comme la somme d'argent de vos stocks et produits non consommables.
Ici, nous utiliserons la même démarche.
On pourrait reprendre la formule de la régression linéaire ci-dessus, sauf qu'elle implique de multiplier par . Or cette fois-ci, X est qualitative, comme notre variable categ. Multiplier une variable qualitative par un nombre n'a aucun sens (ex. : "TRANSPORT" * 3 n'a aucun sens !).
Nous allons faire autrement. Nous allons donc faire la supposition que vos opérations bancaires ont un montant de référence en commun appelé . Ensuite, on considère que le montant de l'opération s'ajuste en fonction de la catégorie de dépense (loyer, transport, courses, etc.). Si une catégorie a des montants qui sont en général inférieurs à , alors cet ajustement sera négatif. Dans le cas contraire, il sera positif. On ajoute la contrainte que la somme de tous les soit égale à 0.
Comme au chapitre précédent, tu commettras toujours une erreur de prédiction, car au sein d'une même catégorie, les montants ne sont pas tous les mêmes !
C'est bien vrai. Comme pour le modèle de la régression linéaire, on aura ici aussi un terme d'erreur :
Comme dans le chapitre précédent, on peut laisser l'ordinateur estimer tous les et , sauf qu'ici, les calculs mathématiques qui nous disent quels sont les et qui minimisent l'erreur donnent des résultats très intuitifs :
Le montant de référence est estimé par la moyenne de tous les montants. On appelle cette estimation
Pour une catégorie , est estimé en calculant l'écart entre et la moyenne des montants de la catégorie , c'est-à-dire :
Évaluez notre modèle : les variables sont-elles corrélées ?
Notre modèle est-il de qualité ? Prévoit-on correctement les montants des opérations uniquement à partir de leur catégorie ?
Comme au chapitre précédent, on espère que notre modèle parvienne à expliquer un gros pourcentage des variations des données. Si c'est le cas, cela signifie que les variables categ et montant sont fortement corrélées.
Pour évaluer cela, la formule utilisée est exactement la même que celle du chapitre précédent : . Mais ici, comme la variable X est qualitative, on peut donner à SCT, SCE et SCR des expressions équivalentes à celles du chapitre précédent. Elles sont données dans la section juste en dessous. De plus, cela permet une meilleure interprétation de ces 3 sigles, qui peuvent être renommés respectivement en variation totale, variation interclasse et variation intraclasse (les classes sont les modalités de X).
De la même manière qu'on avait au chapitre précédent , l'équivalent ici s'appelle le rapport de corrélation, compris entre 0 et 1, donné par :
Si , cela signifie que les moyennes par classes sont toutes égales. Il n’y a donc pas à priori de relation entre les variables Y et X. Au contraire, si , cela signifie que les moyennes par classes sont très différentes, chacune des classes étant constituée de valeurs identiques : il existe donc à priori une relation entre les variables Y et X.
Voici le code permettant de calculer (eta carré ou eta squared, en anglais). Je vous propose ici de faire le calcul à la main ;) :
X = "categ" # qualitative
Y = "montant" # quantitative
sous_echantillon = data[data["montant"] < 0] # On ne garde que les dépenses
def eta_squared(x,y):
moyenne_y = y.mean()
classes = []
for classe in x.unique():
yi_classe = y[x==classe]
classes.append({'ni': len(yi_classe),
'moyenne_classe': yi_classe.mean()})
SCT = sum([(yj-moyenne_y)**2 for yj in y])
SCE = sum([c['ni']*(c['moyenne_classe']-moyenne_y)**2 for c in classes])
return SCE/SCT
eta_squared(sous_echantillon[X],sous_echantillon[Y])On obtient un résultat proche de 0.4, ce qui laisse penser qu'il y a effectivement une corrélation entre le montant des dépenses et leur catégorie. C'est ce que nous avions observé sur le graphique en haut du chapitre !
Appréhendez les expressions de SCT, SCE et SCR
Les expressions de SCT, SCE et SCR introduisent les effectifs de chacune des classes , qui sont au nombre de . Ainsi,
À vous de jouer

On va aller plus loin en analysant la corrélation entre la variable quart_mois créée précédemment et le montant des achats. En effet, il serait intéressant de déterminer si certains jours sont plus "propices" à la dépense que d'autres et pourquoi pas, essayer de dégager les raisons !
En résumé
Le graphique le plus adapté pour représenter la relation entre une variable quantitative et une variable qualitative est une boite à moustaches, ou boxplot, en anglais.
L'ANOVA est une modélisation qui essaie d'expliquer les variations de la variable quantitative en fonction des modalités de la variable qualitative.
Elle permet de calculer le rapport de corrélation, noté utile pour évaluer numériquement la corrélation
Enfin, terminons avec l'analyse de deux variables qualitatives avec le Chi-2. Vous êtes prêt ?
