Nettoyez vos données avec Python
Nous allons nettoyer le jeu de données présenté dans les chapitres précédents, nommé personnes.csv, que vous trouverez à cette adresse. Nous illustrerons ceci en Python, mais si vous préférez R, vous trouverez le code utilisé en Python, avec sa traduction en R dans le dossier suivant.
Nous commencerons par charger le fichier personnes.csv dans une variable que nous appellerons data . Cette variable sera donc un dataframe. Vous pouvez charger ce fichier grâce à ces lignes de code :
# import des librairies dont nous aurons besoin
import pandas as pd
import numpy as np
import re
# chargement et affichage des données
data = pd.read_csv('personnes.csv')
print(data)Détectez les erreurs
Certaines erreurs sont indéniablement plus faciles à détecter que d'autres. Par exemple, les valeurs manquantes sont assez faciles à détecter ! Il existe une méthode .isnull() qui peut s'appliquer aux dataframes ou aux Series pour vérifier si une valeur est une valeur manquante ou non. Voilà une ligne permettant de comptabiliser le nombre de valeurs manquantes par variable :
print(data.isnull().sum()) 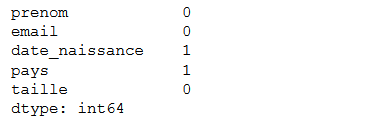
Pour les valeurs extrêmes, des méthodes comme celles de l'écart interquartile ou du Z-score permettent assez facilement de mettre en valeur des outliers.
Pour les doublons, l'utilisation de la méthode .duplicated() permet de vérifier si au sein d'une ou plusieurs variables, il existe des doublons. Cette méthode retournera True dans ce cas, et False sinon. Voilà un exemple avec l'e-mail, qui affichera l'ensemble des lignes concernées par un doublon sur la variable e-mail :
data.loc[data['email'].duplicated(keep=False),:]
Pour le reste des erreurs, il n'y a malheureusement pas de solution magique. Il faudra généralement créer des fonctions spécifiques pour identifier les différentes erreurs. Par exemple, pour une erreur de formatage, on peut fixer un format et cibler l'ensemble des valeurs qui ne rentrent pas dans ce format.
Maintenant que nous avons tous les outils en main pour détecter les erreurs, il est temps de les traiter !
Traitez les erreurs
Souvenez-vous, nous avions déterminé plusieurs erreurs : sur les pays, sur les e-mails, sur les tailles et sur la date de naissance ! Nous allons donc parcourir chacune des colonnes pour détecter les erreurs, les corriger, puis actualiser les colonnes en conséquence. Que ce soit en Python ou en R, actualiser une colonne d'un dataframe se fait de cette manière :
data['nom_colonne'] = nouvelle_colonneIci, on cherche à remplacer les valeurs de la colonne (ou variable) nom_colonne. Si le dataframe a 7 lignes, alors la colonne nom_colonne contient 7 valeurs. Pour les remplacer, nouvelle_colonne doit ainsi être une liste de 7 valeurs.
Il se peut qu'à certains moments, on ne souhaite pas modifier l'entièreté de la colonne mais seulement une partie, comme l'ensemble des valeurs satisfaisant une certaine condition. Pour cela, le plus simple reste de stocker la condition dans un mask, qui pourra ensuite être utilisé :
mask = # condition à vérifier pour cibler spécifiquement certaines lignes
data.loc[mask, 'ma_colonne'] = nouvelles_valeursDans l'exemple ci-dessus, on a stocké une condition dans la variable mask(comme par exemple : data['email'].duplicated(keep=False) pour reprendre l'exemple ci-dessus). ma_colonne correspond forcément à une colonne existante, et seules les lignes satisfaisant la condition stockée dans mask au sein de cette colonne verront leurs valeurs modifiées. Naturellement et comme précédemment, si votre condition ne concerne que 4 valeurs, il faudra également que nouvelles_valeurs soit une liste de 4 valeurs.
Cette dernière approche peut sembler un peu déroutante à première vue, mais vous verrez qu'avec un peu de pratique, cela deviendra vite un outil indispensable lors de vos analyses de données. :soleil:
Traitez les pays
Pour les pays, nous avions un problème majeur qui était la valeur , à la 5e ligne. La première approche pourrait être de considérer que l'ensemble de mes pays doivent être des chaînes de caractères, et donc que toutes les valeurs numériques doivent être remplacées par des valeurs manquantes. Mais pour faire la chose encore plus "proprement", on pourrait définir une liste de pays valides, et remplacer toutes les valeurs qui ne concordent pas avec la liste par des valeurs manquantes :
VALID_COUNTRIES = ['France', 'Côte d\'ivoire', 'Madagascar', 'Bénin', 'Allemagne'
, 'USA']
mask = ~data['pays'].isin(VALID_COUNTRIES)
data.loc[mask, 'pays'] = np.NaNIci, ma condition utilisant .isin() renvoie True si la valeur est dans la liste passée en paramètre (donc ici VALID_COUNTRIES ), False sinon : ainsi, le .loc() permet de ne sélectionner que les lignes dont le pays est dans la liste définie.
Oui mais attends... ce n'était pas l'inverse que nous voulions faire ? >_<
Tout à fait ! Et tout se joue dans le petit symbole ~ placé en amont de la condition. Ce dernier permet de prendre l'exact inverse de la condition, donc ici, l'ensemble des lignes dont le pays n'est pas dans la liste définie. On remplace ensuite l'ensemble des valeurs de pays de ces lignes parnp.NaN , qui est la valeur utilisée par les librairies Numpy et Pandas pour spécifier qu'une valeur est inconnue. C'est en quelque sorte un équivalent de None .
Traitez les e-mails
Au tour des e-mails, maintenant ! Le problème avec cette colonne, c'est qu'il y a parfois 2 adresses e-mail par ligne. Nous ne souhaitons prendre que la première. Nous pouvons là aussi utiliser les outils fournis par Pandas pour faire cela :
data['email'] = data['email'].str.split(',', n=1, expand=True)[0]Lorsqu'il y a plusieurs e-mails par ligne, ceux-ci sont séparés par des virgules. Nous séparons donc la chaîne de caractères de la variable e-mail, selon les virgules grâce à la méthode split. Il y a cependant quelques arguments que nous allons ici expliciter :
','correspond au caractère qui va nous permettre de séparer notre chaîne de caractères.n=1correspond au nombre de fois où notre chaîne de caractères va être séparée. Ici nous le fixons à une fois, car nous ne souhaitons conserver qu'un seul e-mail : le premier rencontré. Le reste n'est finalement que peu intéressant.expand=Truepermet de placer les différentes séparations en plusieurs colonnes.
Nous sélectionnons ensuite la première colonne, correspondant au premier e-mail rencontré.
Traitez les tailles
Nous aurons besoin d'effectuer deux opérations :
Convertir les tailles en nombres décimaux. Nous en profiterons pour remplacer l'ensemble des tailles non conformes par des valeurs manquantes.
Remplacer les valeurs manquantes par la moyenne de notre échantillon.
Pour la première étape, comme l'ensemble de nos valeurs sont censées avoir pour format X.XXm (avec X correspondant à un chiffre), on peut par exemple supprimer le dernier caractère de la colonne et convertir l'ensemble de la colonne en numérique. Ce faisant, les valeurs non valides seront automatiquement remplacées par des valeurs manquantes, via l'argument errors que nous spécifions :
data['taille'] = data['taille'].str[:-1]
data['taille'] = pd.to_numeric(data['taille'], errors='coerce')L'argument errors permet de définir comment Python doit réagir lorsqu'il n'arrive pas à correctement convertir, ce qui correspond aux erreurs dans notre colonne. Il existe différentes options, mais 'coerce' permet de remplacer l'ensemble des erreurs par des valeurs manquantes.
Ensuite, il faut à présent remplacer les valeurs manquantes par la moyenne de la variable. Cette simple ligne permettra de faire cela :
data.loc[data['taille'].isnull(), 'taille'] = data['taille'].mean()Traitez les dates
Dernier sujet à traiter, et pas des moindres : les dates ! Ici, nous allons simplement spécifier un certain format de date, et transformer notre variable dans un type adéquat :
data['date_naissance'] = pd.to_datetime(data['date_naissance'],
format='%d/%m/%Y', errors='coerce')Le type datetime est un format très complexe, et nous n'aurons malheureusement pas le temps de l'aborder dans le cadre de ce cours. Mais pour expliquer rapidement le format, le "code bizarre" situé derrière correspond à :
%d : le jour codé sur deux chiffres (01 à 31) ;
%m : le mois codé sur deux chiffres (01 à 12) ;
%Y : l'année codée sur 4 chiffres.
Vous pourrez trouver de plus amples informations sur les différentes options de format dans la documentation officielle des datetimes.
À vous de jouer

Il est à présent temps de mettre en pratique tout ce que nous avons vu sur notre jeu de données de transactions bancaires. Si vous ne l'avez pas déjà fait, je vous invite fortement à le télécharger et l'importer via le langage de votre choix : R ou Python.
Plusieurs erreurs se sont glissées dans ce jeu de données. Votre mission, si toutefois vous l'acceptez, va être de les trouver et de proposer des solutions adéquates pour les gérer. Vous aurez besoin dans tous les cas de nettoyer votre fichier avant de passer à la suite !
En résumé
Chaque erreur nécessite un traitement adéquat. Pour faire cela, Pandas met à disposition de nombreuses méthodes et fonctions très pratiques et performantes !
Même si certaines erreurs sont faciles à détecter et à traiter, d'autres nécessiteront un peu plus de code, et de connaître les outils correspondants.
Après avoir nettoyé votre jeu de données, vous pouvez procéder à réaliser des analyses ! Nous verrons comment faire dans la prochaine partie, après un quiz !
