Choose a Relational Database or NoSQL
Understand the Structure of Your Data
Have you ever used a spreadsheet package, such as Excel or LibreOffice Calc? Then you already know how to handle structured data!
A spreadsheet has rows and columns.
Each row generally represents an instance of an entity for which you store data, and the columns represent the attributes of each entity.
This is also true for our data set:
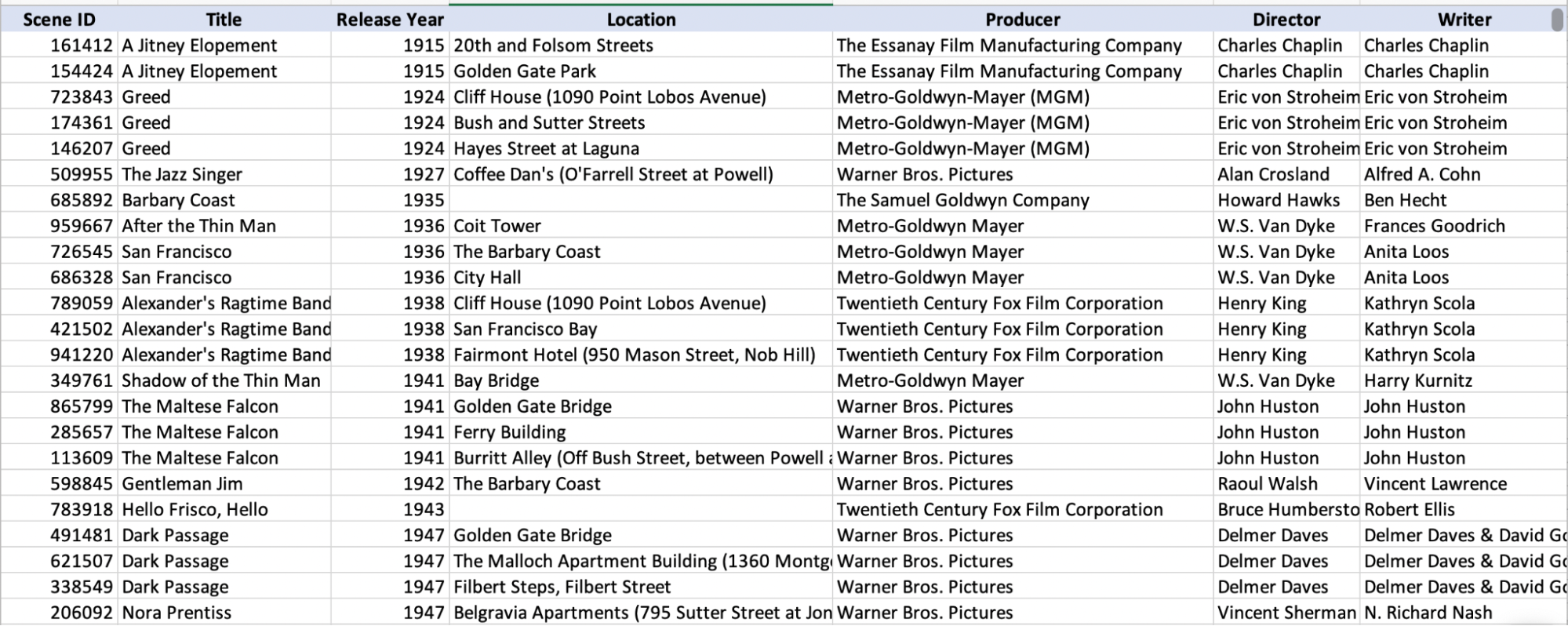
We are storing data about movie scene filmings. Here is what we have:
Each row is a scene for a particular movie.
Each column is an attribute of the scene: location, title, director, etc.
It’s nice and clear. We already know what attributes we have for each movie scene (title, director, location, etc.), so we can easily determine the names for the columns. Also, the scenes have a similar structure because they can all be represented using the same attributes/columns. For example, there isn’t a scene without a location attribute. And every location must be either an address, street intersection, or landmark.
But sometimes, it’s more complicated.
Have you ever heard of big data?
Big data is a very modern phenomenon where massive amounts of data are generated daily, mainly due to the increasing use of electronic devices such as phones, tablets, etc. With this large volume of data, we’ve had to adapt and find new technologies to store, display, organize, and analyze it.
The three Vs of big data are:
Volume
Velocity
Variety
Let’s consider the last element: variety. Website data is increasingly varied: images, videos, text, opinions on social networks, emails, etc. This data is difficult to represent in a table format. Therefore, it’s known as semi-structured data.
Display Your Data According to its Structure
Imagine that you wish to store information about individuals in a structured way. You’re going to create a table with one row per person and one column per attribute.
You can characterize a person by their name and date of birth. You can also use their internet browsing history (pages they visit), purchasing behavior (products they buy), people with whom they interact (friendship groups, professional networks, other organizations), and many other things!
So many possible attributes can make a lot of table columns.
And actually, you are highly unlikely to capture all of an individual’s attributes in one go.
What this means:
Only a small proportion of the columns will populate for a given row.
For the next row, other columns will populate, but not necessarily the same ones!
Your table will have several blank spaces and a vast number of columns. It’s not practical to have an enormous Excel sheet with just a few bits of data dotted around all over the place!

Displaying a wide variety of data in a table is not ideal.
So, how can we display unstructured data?
There are many possible options!
You can store an individual’s data in the key-value format.
In this format, each key is the type of attribute (“last name,” “first name,” etc.), and you associate a value to each key (“Smith,” “Joanne,” etc.).
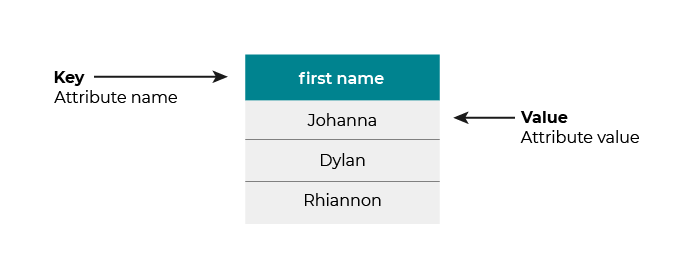
Here’s an example:
[
{
"person_ID":1,
"surname":"Smith",
"forename":"Joanne",
"favorite pages":
[
"twitter.com",
"mail.google.com",
"nytimes.com"
],
"purchasing":{
"culture":{
"books":
[
{
"ISBN":"9780261103283",
"titLe":"The Hobbit",
"author":"J. R. R. Tolkien",
"purchase_date":"18/12/2029"
},
{
"ISBN":"9781408855652",
"title":"Harry Potter and the Philosopher’s Stone",
"author":"J.K. Rowling",
"purchase_date":"23/01/2029"
}
]
}
}
},
{
"Person_ID":2,
"surname":"Jones",
"forename":"David",
"facebook_profile":"www.facebook.com/DaveTheRaver",
"twitter_profile":"twitter.com/DaveTheRaver",
"facebook_friends":
[
"www.facebook.com/PeteTheNeat",
"www.facebook.com/TrishTheFish",
"www.facebook.com/RyanTheLion",
"www.facebook.com/DennisTheMenace"
]
}
]So, for structured data, what format should the file be in?
The most common table format is CSV (comma-separated values). The first row of the file gives the names of the columns, and the following rows display all of the data, separated by commas:
scene_id,title,release_year,location,production_co,director
580623,A Jitney Elopement,1915,20th and Folsom Streets,The Essanay Film Manufacturing Company,Charles Chaplin
790953,A Jitney Elopement,1915,Golden Gate Park,The Essanay Film Manufacturing Company,Charles Chaplin
264956,Greed,1924,Cliff House (1090 Point Lobos Avenue),Metro-Goldwyn-Mayer (MGM),Eric von Stroheim
538377,Greed,1924,Bush and Sutter Streets,Metro-Goldwyn-Mayer (MGM),Eric von Stroheim
265775,Greed,1924,Hayes Street at Laguna,Metro-Goldwyn-Mayer (MGM),Eric von Stroheim
553535,The Jazz Singer,1927,Coffee Dan's (O'Farrell Street at Powell),Warner Bros. Pictures,Alan Crosland
286058,After the Thin Man,1936,Coit Tower,Metro-Goldwyn Mayer,W.S. Van DykeChoose Your DBMS Based on the Structure of Your Data
If you understand your data’s structure, you can choose the most appropriate DBMS. If your DBMS is unsuitable, it will be more difficult to write queries to access the data, and response times will probably be longer.
The most practical way to store structured data is in a relational database.
Why relational?
This term comes from the relational model, which represents how different pieces of information relate to each other. But we’ll deal with this a bit later on. 
A DBMS that manages a relational database is known as an R-DBMS. The SQL language was created to avoid having a different language for each R-DBMS. It can be used with the vast majority of R-DBMS and allows data in a relational database to be added, read, updated, or deleted.
The most well-known R-DBMS include:
PostgreSQL
MySQL
Oracle
SQLite
But what about unstructured data?
Unstructured data is more complicated because it can take many forms depending on what you want to store. A DBMS that deviates from the relational model is known as NoSQL (Not Only SQL).
Examples of NoSQL DBMS include:
Elasticsearch: very effective for storing text and carrying out searches.
Neo4j: stores graphic data, i.e., data represented as a type of network consisting of interconnected elements: social, road, or IT networks, etc.
MongoDB: stores data in the key-value format, as in the earlier example.
Which DBMS should we use for the filming locations data?
Remember that our data is structured; we know what attributes we want to capture for each movie location, and there are a finite number of them.
Therefore, we can use any of the database management systems mentioned above.
So, we’re not going to learn how to design a NoSQL structure?
No, because NoSQL databases are designed for unstructured data, and their limited structure is based on relational database concepts. So, you might as well start by learning about relational databases because it's always useful to understand how they work.
To this day, relational databases remain the most widespread type of database and the most suitable for software, mobile, and web app functionality by a very long way.
Now it's Your Turn!

It’s time to test your understanding of the concepts we’ve explored in this chapter.
You’re going to design two databases, one for each of the following scenarios:
You want to create a social network for writers, from budding poets to experienced authors. They will be posting texts of widely varying lengths. This social network must include a fast and effective search facility that can search all the texts for keywords (or a group of keywords).
You need to write some accounting software that can design and store invoices. By law, an invoice must conform to a particular structure. All invoices must display certain mandatory data items, such as issue date, invoice number, customer identifier, VAT number, etc.
For which scenario would you use a relational database, and which would you use a NoSQL database?
Answer:
In the first scenario, the social network database will mostly contain text, which is semi-structured data, because it is not easily displayed in a table format. Therefore, you will use a NoSQL type DBMS designed to store and search textual data.
In the second scenario, you will store your invoice data in a relational database for structured data. The invoice data structure is clearly defined and easy to represent in a table format.
Let’s Recap!
Structured data is easy to represent in a table format, with one row per element and with columns to represent the attributes of each element.
The CSV format provides a way of displaying data in a table.
Unstructured data is not suited to display in a table, so you need to find another way of storing and displaying it.
Relational databases are suitable for structured data.
SQL is the common language used by most relational database management systems (R-DBMS).
Well done! You now know that you will need a relational database to store your structured data. Next, you need to create a structure for this database before you can start to populate it.
