Use Normalization to Improve Your Model
There are always multiple ways of modeling data, and some are better than others. One of the first criteria for assessing quality is redundancy in the model. A set of criteria was created, database normalization, to help assess the quality of two different data models.
Up to now, we have talked a lot about redundancy, but without defining the rules. Database normalization will fill this gap. 
Learn the Notion of Dependency
Let’s use the CSV file to look at redundancy:

You can see redundancy in the type of production. For example, data indicates that the feature film Nine Months, produced by 1492 Pictures, appears several times. Why? Because the filming type is only dependent on the production. However, many rows in the file reference the same production, which means the data is duplicated.
Saying that “the filming type is only dependent on the production” means that if you see Nine Months by 1492 Pictures in the file, the filming type must be FeatureFilm .
What do you need to identify a production in your file? We already mentioned that you identify a production using its title and production company, i.e., (title, production_company) .
So, filming_type is functionally dependent on the set of attributes (title, production_company ), known as functional dependency, indicated using an arrow:
(title, production_company) -> filming_type
But hold on. The attribute set (title, production_company) isn’t unique in your file as several rows relate to the same production. If the same production appears several times (due to the functional dependency), several rows will indicate the production type for a given production. And that’s where you have redundancy.
So, if you want to avoid redundancy, you need (title, production_company) to be unique. Therefore, this set of attributes will need to be the primary key (or at least a candidate key). Here’s what you can conclude from this:
An added detail: there is still a risk of redundancy if an attribute is dependent on part of the primary key. Imagine a table with a (title, production_company) primary key, and a production_company_address attribute to hold the production company’s address.
production_company_address is uniquely dependent on production_company . Since production_company isn't unique (because it is only part of the primary key), there is a risk of redundancy:
Title [PK] | Production company [PK] | Filming Type |
Nine Months | 1492 Pictures | FeatureFilm |
Casualties of War | Columbia Picture Corporation | FeatureFilm |
Silicon Valley | Brown Hill Productions, LLC | TVSeries |
This poses a risk of redundancy.
You can add the following to the previous sentence:
Understand How to Define Dependency
But how can we be sure that an attribute A is dependent on a set of attributes S?
Imagine that you know the data you are modeling very well. Then, ask yourself this question: if you only have S, can you determine A with certainty, with no ambiguity, and without further information?
For example:
Can you determine the filming type (TV film, TV series, etc.) for a production if you only know the production company? The answer is no because one production company can produce several different types of productions. It’s ambiguous, and you need more information – i.e., the production’s title – to resolve it. With the title and the production company, you can determine the filming type if you know the data back to front. So, you can say that:
filming_typeis not uniquely dependent onproduction_company.filming_typeis dependent on(title, production_company).
Ah, but if you know the title, production company, and location of a given filming event, you can also determine the filming_type . So can you say that filming_type is dependent on (title, production_company, scene_location) ?
Yes, but it’s not particularly interesting because (title, production_company, scene_location) isn't minimal, meaning that you can take away one of the attributes ( scene_location ) without breaking the dependency. You can say that:
filming_typeis dependent on part of(title, production_company, scene_location).
Work Out the First Three Normal Forms
The process you just saw is called the norm forms and has three rules you should follow. There are more than three, but generally, a model that conforms with the first three forms avoids most data redundancy.
1NF
The first normal form (1NF) is a prerequisite for the following forms. Regarding primary keys, you must ensure that:
Each table has a primary key.
Each attribute only holds one piece of information at a time (otherwise, it can get messy to check the redundancy and uniqueness of an attribute).
In other words, each attribute must be atomic, i.e., it can’t be multivalued or composite (to refresh your memory on these two terms, look at chapter 1, part 2: “Lay the Foundations for Your Class Diagram”).
composite attribute |
| atomic attributes |
| => |
|
Let’s look at an example.
In your file, the director is multivalued because one cell can hold several directors’ names.
You considered this in your relational model because you transformed this multivalued attribute into a new table, director , containing a name attribute, which is atomic (and that's what you want). This new table is linked to the production table using a many-to-many association:
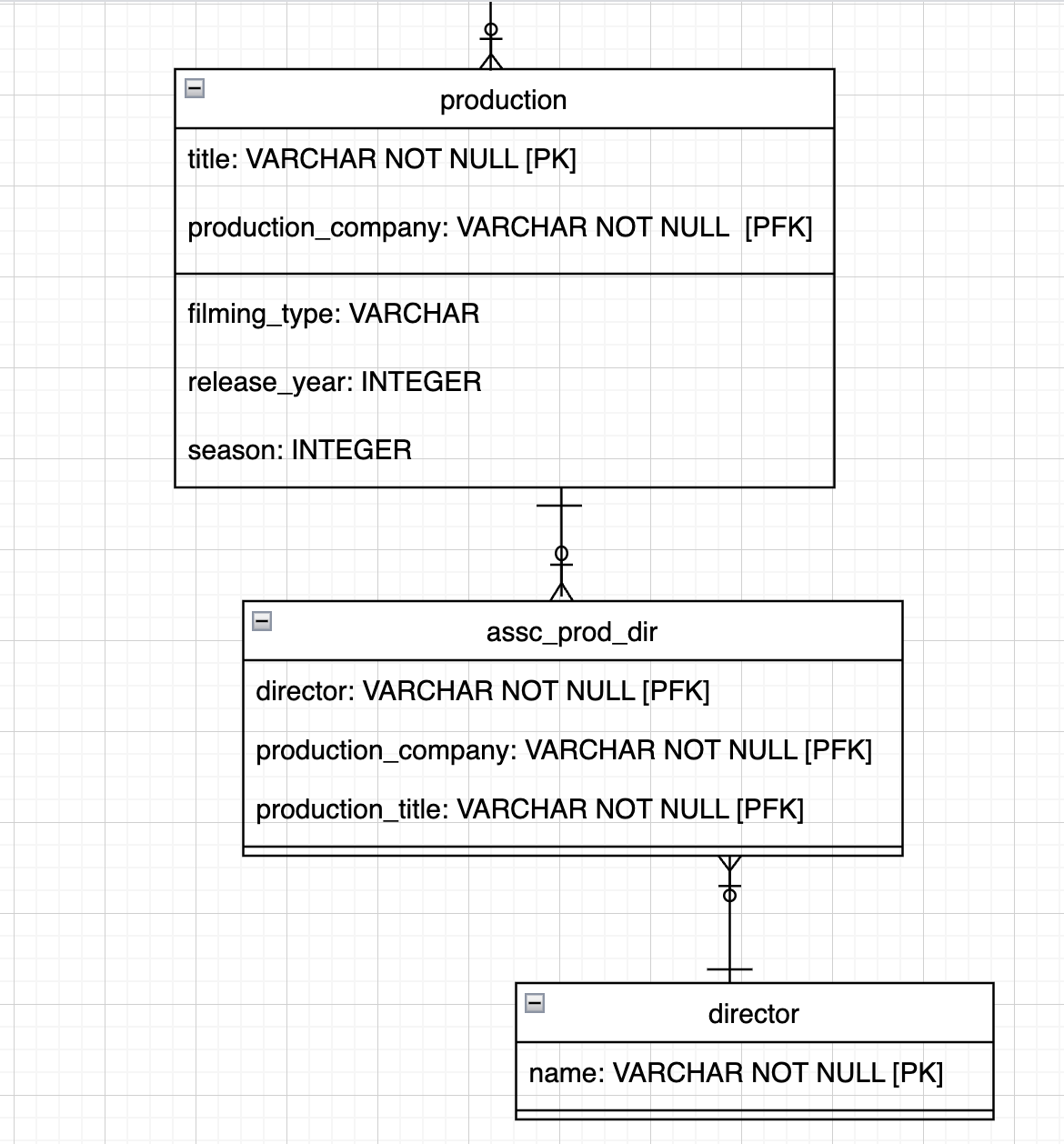
2NF
The second normal form will flow naturally from the thought process you followed above:
A table is in second normal form (2NF) if:
It’s in 1NF.
Every attribute (that doesn't belong to a candidate key) is not dependent on only one part of a candidate key.
3NF
A relation is in third normal form (3NF) if:
It’s in 2NF.
Every attribute (that doesn't belong to a candidate key) is not dependent on another attribute that doesn't belong to a candidate key.
Learn to Comply With the Three Normal Forms
To comply with 1NF, you need to:
Choose a primary key for each table.
Transform multivalued attributes into a new table linked to the original one using a one-to-many or many-to-many association.
Break the composite attributes into atomic attributes (e.g., deconstruct Ms. Jane Smith into three attributes: title, first name, last name).
You need to study the dependencies between attributes for 2NF and 3NF.
There is a rule to separate the attributes of one table to reduce redundancy without losing any information to help with this. Here it is:
Also, if another attribute (B) is uniquely dependent on S, you must move the attribute to the new table (T2).
For example, in your CSV file, you’ve seen that filming_type is dependent on (title, production_company) . This attribute set is also minimal. You can apply the above rule to say:
T1 = your CSV file.
A =
filming_type.S =
(title, production_company).
Following this rule:
Create T2 with a primary key of
(title, production_company), which holdsfilming_typeas an attribute.Delete the
filming_typecolumn from the big CSV file.Indicate that
(title, production_company)is a foreign key referencing T2.
And surprise! You notice that T2 exactly matches the production table that you previously defined!
title [PK] | production_company [PK] | filming_type |
Nine Months | 1492 Pictures | FeatureFilm |
Casualties of War | Columbia Picture Corporation | FeatureFilm |
Silicon Valley | Brown Hill Productions, LLC | TVSeries |
This is a good sign. It means you were on the right track when you defined your relational model without realizing it!
Would you have arrived at the same relational model if you’d followed this process to its conclusion (i.e., by breaking the large CSV file down bit by bit into separate tables)?
You’ll be able to think about your answer in just a few seconds. And actually, you’re going to apply this process in the next chapter when you separate your CSV file into different tables.
Separate Your File
Consider your CSV file as one table and then split it into several by analyzing the dependencies between the attributes. Don’t forget to apply the above rules.
But before starting, you need to determine the primary key of your big file.
Easy! The scene_id identifies each row, so this is the primary key.
That is essentially correct, but it’s not going to help much! If you use this logic, you will fall into the trap mentioned at the end of the “Determine Your Primary Keys” chapter. As a reminder, this trap involves considering an artificial key (e.g., scene_id ) as a simple solution without really thinking about the uniqueness constraint of the other attributes.
This primary key will tell you about each row in the table.
Instinctively, you could have said, “The scene_id column identifies each row.” Therefore, each row represents a location. But this isn’t true as sometimes multiple rows correspond to the same location. For example, the TV series Looking and the feature film Diary of a Teenage Girl both filmed scenes at 770 Haight St . There are fewer locations than rows in your file.
The scene_id is not a location identifier. Instead, it identifies the location of a production’s filming session for a given period. In other words, it’s the identifier of an association between:
A location (identified using
locationandzip code).A filming session (identified using
start_date,end_date) for a production (identified usingtitleandproduction_company).
So, you can determine that one of the possible primary keys is (location, zip_code, start_date, end_date, title, production_company) .
Based on this information, you can move any attribute that isn't dependent on this primary key or that only depends on part of it into a new table.
Now it's Your Turn!

You have everything you need to create a relational model based on the columns of your file.
By way of an answer, here are the dependencies between the attributes:
(
title,production_company) ->filming_type.(
start_date) ->filming_year. This attribute is not useful because it's derived.(
title,production_company,start_date, end_date) →director.
With points 1 and 2, everything aligns with what you worked out before this chapter. But point 3 is different. You can see that a director is not solely dependent on the production in question but also the filming session.
Directors can be replaced during filming, which is often true for series, where a different person could direct each episode.
For example, Sara Gran and Carl Franklin (among others) directed the series Chance.
Consider the relational model from before the previous chapter. There was no way of knowing who was directing for a given period. In other words, even if you knew the directors of Chance, you had no way of knowing which episodes were directed by whom.
To resolve this, apply the above rule and create a table with a primary key of ( title , production_company , start_date , end_date ) containing one attribute, director. This table gives you the filming periods for a given production (but with no indication of the location). Call it shooting_period .
In addition, the director column is multivalued because some rows contain a pair of directors. As mentioned earlier in this chapter, you can break it down into a new table called director , which is linked to shooting_period by a many-to-many association, as follows:
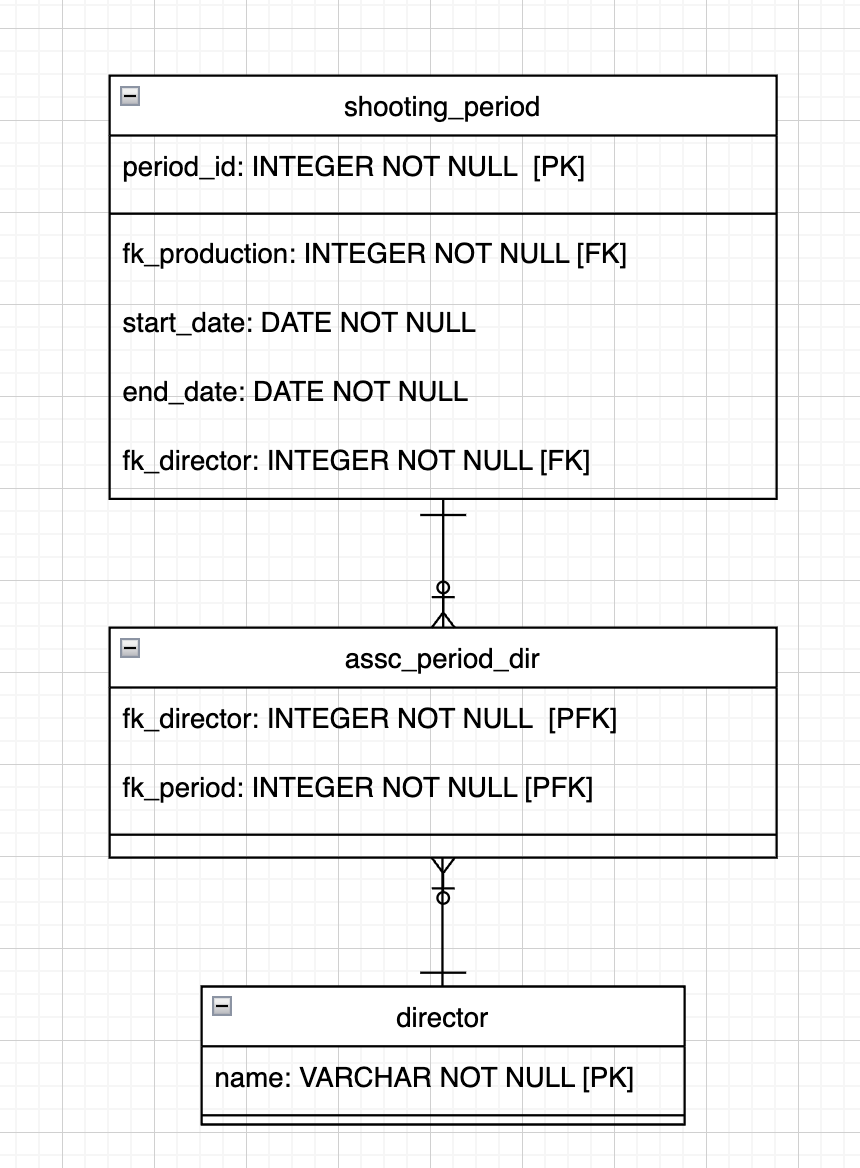
When you've created all of your separate tables, you’ll have:
location_id.A foreign key to the
locationtable, composed of two columns.A foreign key to the
filming_periodtable, consisting of four columns.
You can delete location_id as it no longer has a purpose. This table forms an association table between location and shooting_period , which is handy because it indicates a many-to-many relationship. However:
One filming session can take place during the same period in two different locations (with two different teams or with one team that moves during the day).
One location can also host separate filming events during the same period.
So, let’s call this table assc_period_loc .
Yay! You now have your final relational model, which is in 3NF!
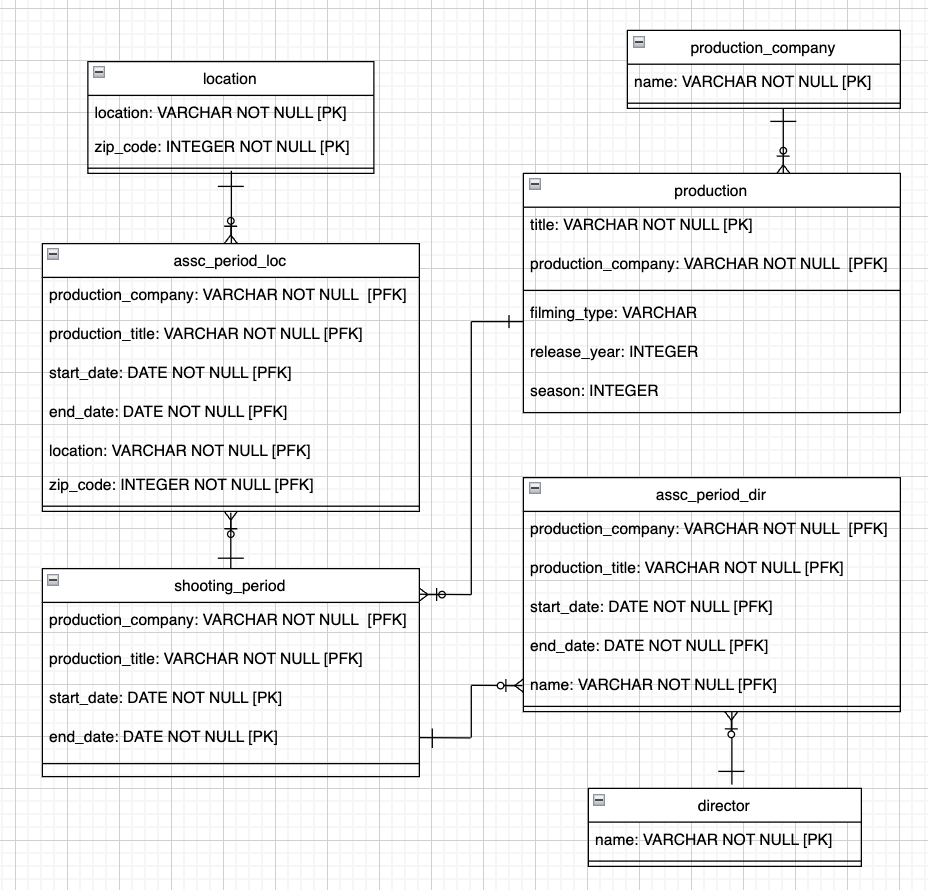
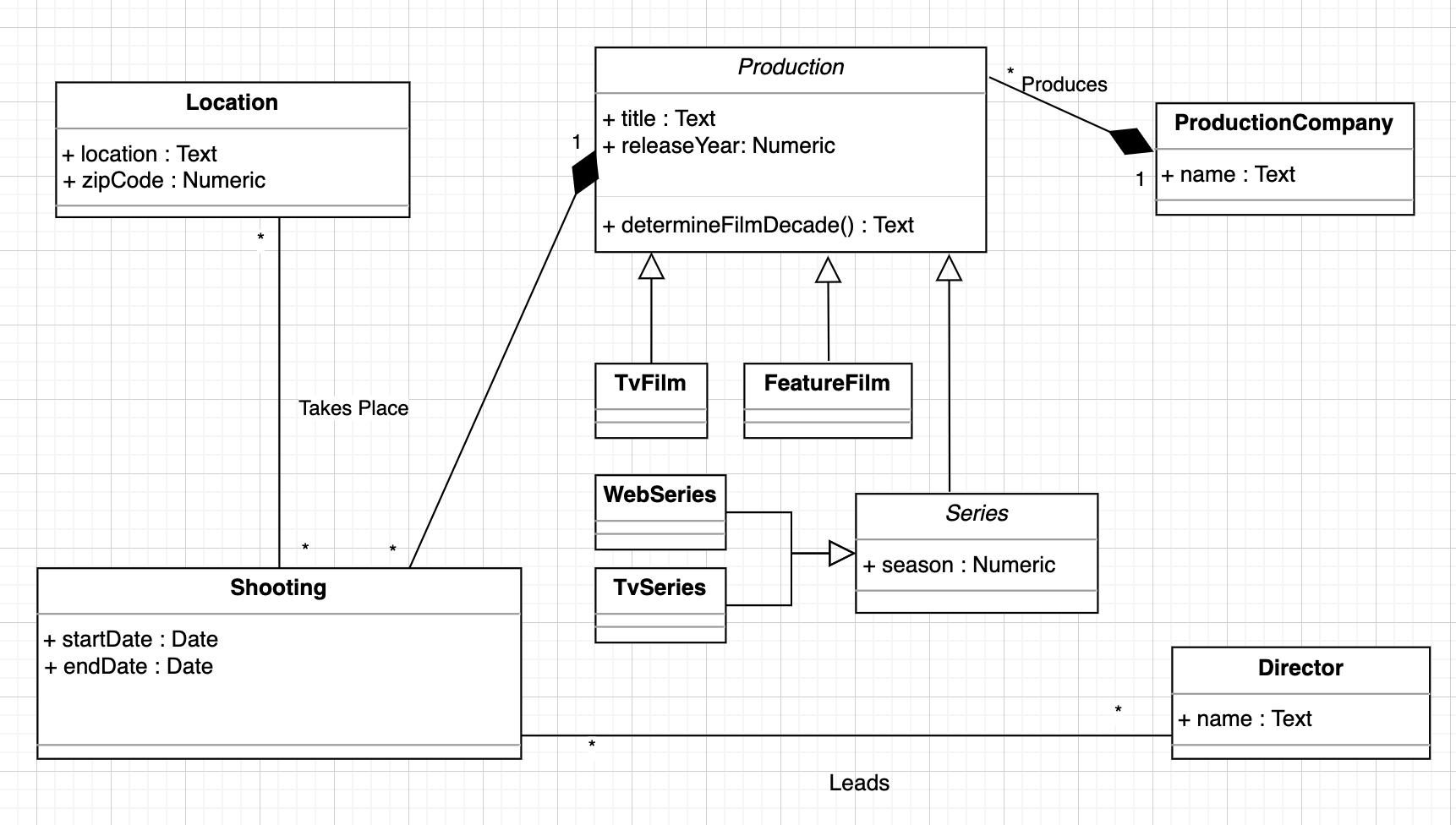
Let’s Recap!
Some attributes can be dependent on others.
To (mostly) avoid redundancy in a table, each attribute (that doesn’t belong to the primary key) must only be dependent on the table’s primary key. Each attribute must also be dependent on the whole primary key.
A table is in 1NF if there is a primary key and its attributes are atomic.
A table is in 2NF if it is in 1NF, and every attribute (that doesn't belong to a candidate key) is not dependent on only part of a candidate key.
A relation is in 3NF if it is in 2NF, and every attribute (that doesn't belong to a candidate key) is not dependent on another attribute that doesn't belong to a candidate key.
There is a rule to separate the attributes of one table to reduce redundancy without losing any information.
After normalizing a relational model, you must remember to update your UML in line with it.
There you have it! You have all of the skills required to model a relational database. But I imagine you probably feel like you haven't quite finished because you haven't even touched your data yet! The final chapter will satisfy your hunger! You will finally get to manipulate your Excel file to fit your model, and, in the end, you can even use SQL to query your database!
