Agrégez des données avec Pandas
Maintenant que nous sommes capables d’accéder à tout ce que nous souhaitons au sein de notre data frame, je vous propose de voir comment agréger les différentes informations.
Notre banque opère dans 6 villes différentes : Toulouse, Paris, Marseille, Lyon, Nice et Bordeaux. Chaque prêt contracté par un de nos clients est forcément relié à l’une de ces agences. Et vous risquez de vous poser cette question :
Admettons que je veuille calculer le chiffre d'affaires mensuel réalisé par chaque agence. Comment puis-je faire ?
Bonne question !
Il va donc falloir :
sélectionner l’ensemble des clients de l’agence de Toulouse et calculer la somme de leurs mensualités ;
sélectionner l’ensemble des clients de l’agence de Paris et calculer la somme de leurs mensualités ;
etc.
Le résultat final serait ainsi une ligne par agence/ville, avec la somme des mensualités perçues par chacune d’elles.
Cette opération est ce qu’on appelle en algèbre relationnelle une agrégation. C’est une opération très courante sur des data frames, soit pour analyser les données sous un certain angle, soit pour recalculer certaines variables, comme la moyenne des mensualités par agence.
Je vous propose de voir comment réaliser cela avec Pandas.
Agrégez plusieurs lignes
La première méthode pour faire une agrégation avec Pandas est .group_by .
Pour l’utiliser, vous aurez besoin de vous fixer sur une ou plusieurs colonnes, qui seront ce qu’on appelle les index de votre résultat agrégé.
Cela vous rappelle-t-il quelque chose ?
Eh oui ! Comme nous l’avons dit dans le chapitre précédent, l’index n’est pas forcément l’indice, ça peut être également des chaînes de caractères. Dans notre exemple, notre index serait la variable ville . L’index va permettre de créer plusieurs groupes : un pour chaque valeur unique de l’index.
Après avoir choisi les colonnes sur lesquelles vous allez vous fixer, vous aurez à choisir une fonction d’agrégation. La fonction d’agrégation va prendre en entrée un groupe de plusieurs lignes, pour effectuer un calcul sur celles-ci dans l’optique de retourner une unique valeur pour chacun des groupes. Ici, la fonction d’agrégation serait une somme.
Considérons le data frame test suivant :
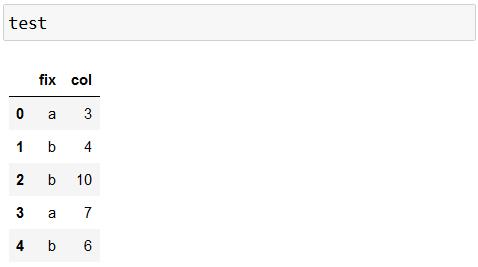
On souhaite calculer la moyenne de la variablecol pour chaque valeur de la variablefix . La ligne en Python pour faire cela est :
test.groupby('fix').mean()Décomposons ce qu’il se passe lors de l’exécution de cette ligne. Dans un premier temps, notre index sera la variablefix ; il va donc y avoir 2 groupes créés, un pour chaque valeur dans notre variablefix .
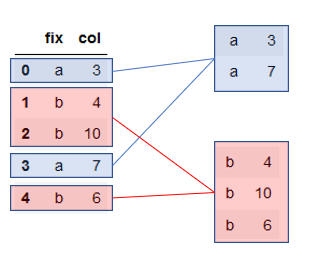
Sur chacun de ces groupes, on va appliquer la fonction d’agrégation choisie (ici, la moyenne) afin d’avoir le résultat souhaité :
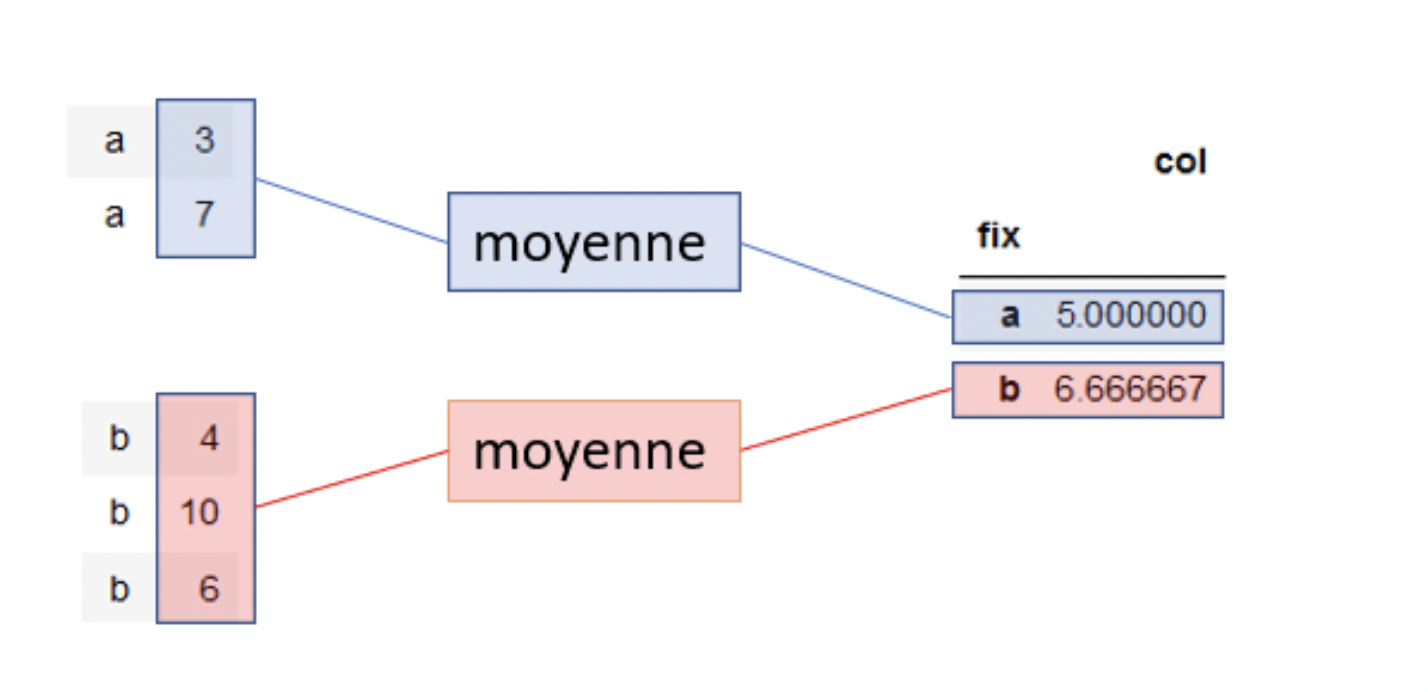
À présent, comment calculer l’information recherchée initialement, soit le chiffre d'affaires total de chacune de nos agences ?
prets.groupby('ville').sum()Maintenant, imaginons que nous ne souhaitions la même information que par agence ET par type de prêt. Vous vous en doutez très probablement, il suffira de transmettre la liste des variables à placer en index :
prets.groupby(['ville', 'type']).sum()Et si vous ne souhaitez avoir que le résultat sur la variable remboursement :
prets.groupby(['ville', 'type'])['remboursement'].sum()On peut même appliquer des fonctions d’agrégation différentes en fonction de la colonne, voire appliquer plusieurs fonctions d’agrégation sur une même colonne. Ici, je calcule la moyenne et la somme deremboursement par agence, ainsi que le maximum derevenu :
prets.groupby('ville').agg({'remboursement': ['sum', 'mean'],
'revenu': 'max'})Reprenons la dernière ligne de code présentée. Imaginons à présent que nous souhaitions avoir ce même résultat, mais sous forme d’un tableau à double entrée. Je vous propose de voir ça en détail dans la prochaine section.
Agrégez des lignes et des colonnes
Nous souhaitons donc avoir la même agrégation, mais avec cette fois-ci, en lignes nos agences, et en colonnes les différents types de prêts.
La méthode qui vous permettra de faire cela est la méthode .pivot_table . Celle-ci prend 4 arguments en paramètres :
index : variable(s) placée(s) en ligne ;
columns : variable(s) placée en colonne(s) ;
values : variable sur laquelle on va appliquer la fonction d’agrégation ;
aggfunc : fonction d’agrégation.
La méthode permettant la transformation inverse s’appelle melt . Je vous propose de découvrir ces deux nouvelles méthodes en vidéo :
Prêt à mettre tout cela en pratique ? C’est parti !
À vous de jouer

Contexte
Vous l’avez probablement remarqué, certains clients ont contracté plusieurs prêts au sein de notre établissement. Cela fausse donc potentiellement les calculs réalisés jusque-là. Le responsable revient vers vous avec des demandes plus précises.
Consignes
Voici l’e-mail qu’il vous a envoyé :
Hello,
J’aurais plusieurs demandes que je souhaiterais que tu traites dès que tu peux. On en aurait besoin pour le comité de direction prévu en fin de semaine. Pourrais-tu :
créer un data frame de profil client pour avoir par client toutes les informations qui le concernent, résumées en une ligne ;
calculer le nombre exact de personnes en état de situation bancaire risquée, à partir du taux d’endettement et de ces profils clients ;
calculer le bénéfice total dégagé par chacune de nos agences, par type de prêt ;
calculer les bénéfices moyens réalisés par chaque agence, pour chaque type de prêt, sous forme de tableau à double entrée ;
me communiquer la ville qui semble la plus intéressante pour y développer les prêts immobiliers ?
Merci d’avance.
Je vous invite réaliser cet exercice.
Vérifiez votre travail
Félicitations pour être arrivé au bout ! Voici la correction correspondante.
En résumé
Pour agréger des données, il faut définir une ou plusieurs variables placées en index, pour former des groupes sur lesquels s’appliquera une fonction d’agrégation.
Le résultat final d’une agrégation contiendra autant de lignes que de valeurs différentes dans la variable ou les variables choisies en index.
Il existe deux méthodes en Python permettant de réaliser une agrégation :
la méthode
group_by;la méthode
pivot_table.
Je vous propose maintenant de voir comment fusionner plusieurs fichiers de données, avec Pandas.
