Mettez en place une stratégie de restauration en cas de sinistre

Adoptez les stratégies de reprise après sinistre
AWS met à disposition 4 stratégies de reprise après sinistre pouvant être classées en quatre approches, allant du faible coût et de la faible complexité des sauvegardes à des stratégies plus complexes utilisant plusieurs régions actives :
Sauvegarde et restauration (Backup and Restore) : c’est la stratégie la moins chère, mais qui met le plus de temps pour restaurer. Elle consiste à effectuer régulièrement des sauvegardes des données de bases de données ou systèmes de stockage dans un datacenter on-premises ou dans une région AWS vers une autre région AWS. Lors du sinistre, il faudra réinstaller toutes les applications sur la nouvelle région AWS et restaurer les bases de données et systèmes de stockage à partir des sauvegardes.
Environnement de veille(Pilot Light) : les sauvegardes des données sont toujours effectuées dans une autre région AWS. De plus, d'autres éléments, tels que les serveurs d'applications, sont chargés avec le code d'application et les configurations mais sont désactivés (en veille) et ne sont utilisés que pendant les tests ou lorsque le basculement de reprise après sinistre est invoqué. Cette stratégie est plus rapide que la stratégie Sauvegarde et restauration.
Secours à chaud(Warm Standby) : consiste à installer dans une autre région une copie réduite, mais entièrement fonctionnelle, de l’environnement de production. Lors du sinistre, il est alors rapide de basculer vers cette copie, ce qui implique peu de temps d’indisponibilité.
Mode actif/actif multi-site (Multi-site active/active) : l’application est simultanément exécutée dans plusieurs régions. Ainsi, le trafic est redirigé vers toutes les régions où l’application est installée. Alors que pour la stratégie Secours à chaud le trafic est redirigé vers une seule région. Ainsi, la restauration avec cette dernière stratégie après sinistre est immédiate ; elle reste aussi la plus onéreuse.
Voici un comparatif en schéma de ces 4 stratégies :
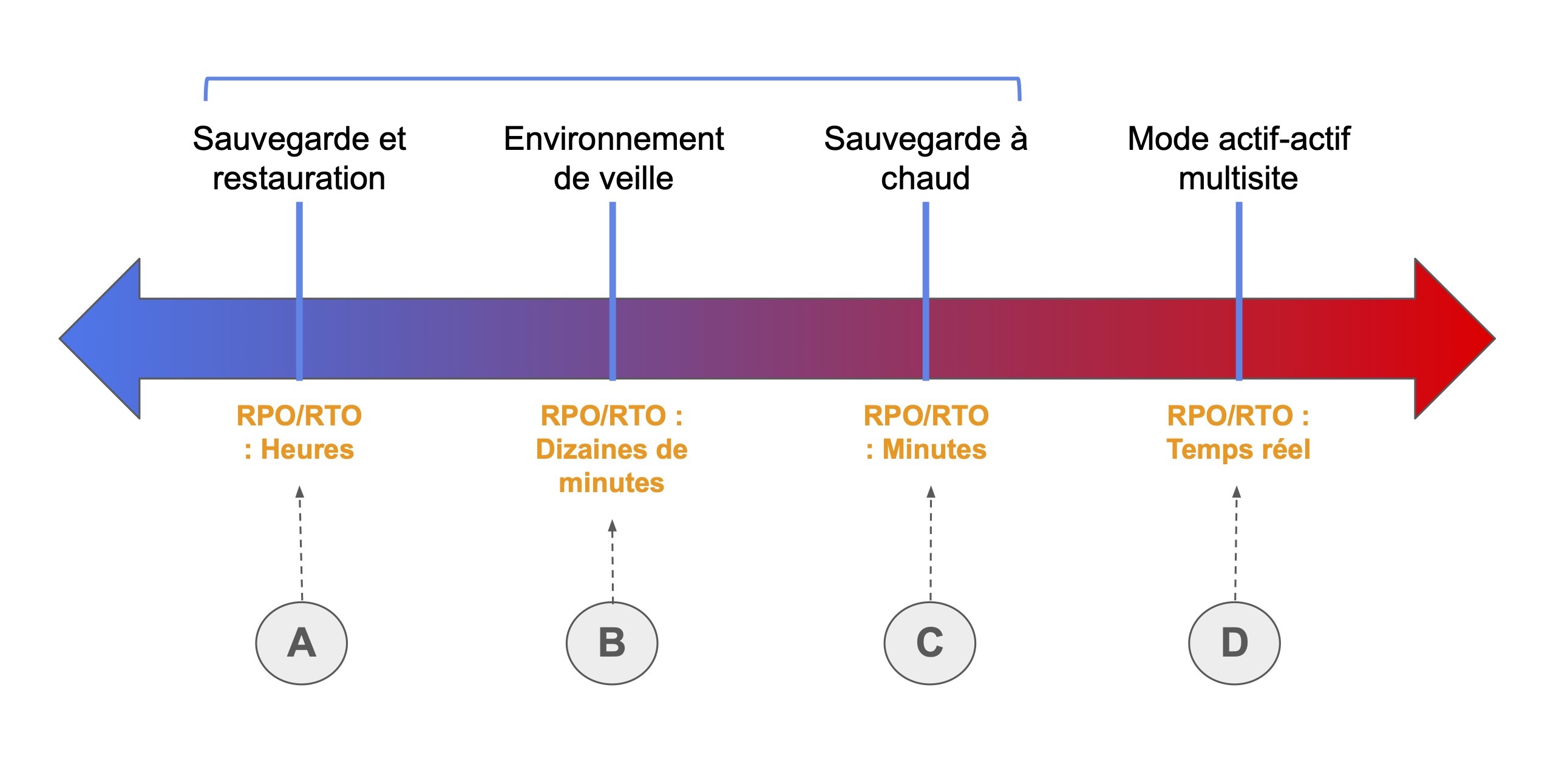
A - Cas d'utilisation de moindre priorité.
Provisionner toutes les ressources AWS après l'événement.
Restaurer les sauvegardes après l'événement.
Coût : $.
B - Données en direct.
Service inactif.
Provisionner certaines ressources AWS et mettre à l'échelle après l'événement.
Coût : $$.
C - Toujours en cours d'exécution, mais plus petit.
Critique pour l’entreprise.
Mettre à l'échelle les ressources AWS après l'événement.
Coût : $$$.
D - Zéro temps d'arrêt.
Perte de données quasi nulle.
Services essentiels à l’entreprise.
Coût : $$$$.
Restaurez le site de The Green Earth Post
Reprenons l’architecture du site web de The Green Earth Post. Les services S3, l'équilibreur de charge ALB, le groupe Auto Scaling et RDS sont régionaux, ils sont donc critiques ; les autres ne le sont pas car ils sont globaux.
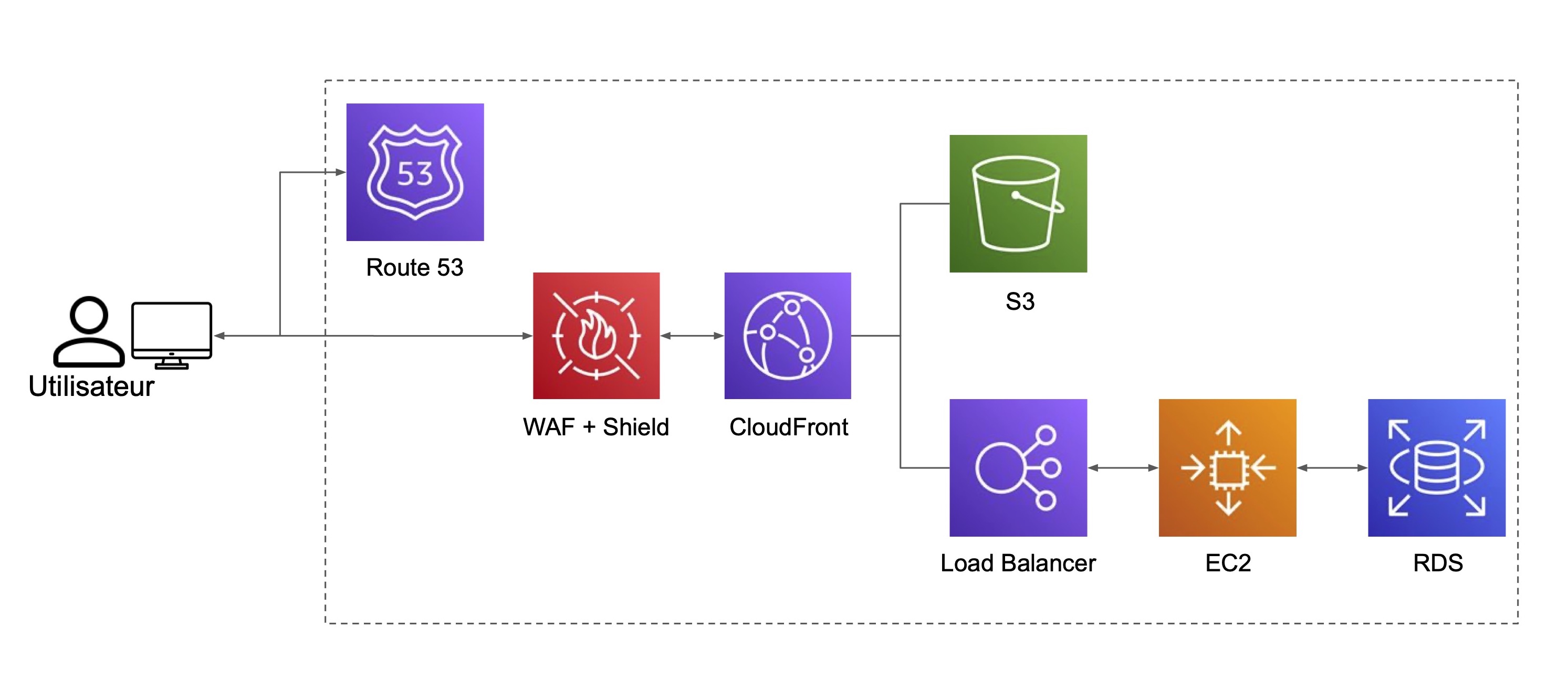
Quelle stratégie adopter pour The Green Earth Post ?
Une indisponibilité du site pendant une dizaine de minutes est acceptable, par conséquent, il faut adopter la stratégie Environnement de veille.
Pour garantir la pérennité des données, il faut réaliser des sauvegardes dans une autre région, dite région B, des données de la base de données RDS. Le service AWS Backup est utile pour cela. Pour le compartiment S3, configurez la réplication d’objets vers un compartiment S3 de la région B. Comme il est acceptable d’avoir une interruption d’une dizaine de minutes, installez un équilibreur de charge ALB, un certificat public via le service ACM et un groupe Auto Scaling dans la région B, mais qui restent désactivés.
Lors d’un sinistre, il sera possible de facilement configurer CloudFront pour rediriger le trafic vers les services installés dans la région B.
En résumé
Mettre en place une stratégie de restauration est essentiel. AWS met à disposition 4 stratégies à connaître :
Sauvegarde et restauration
Environnement de veille
Secours à chaud
Mode actif/actif multi-site
Pour le projet The Green Earth Post, la stratégie Environnement de veille est la plus adéquate.
Pour conclure ce cours
Félicitations !
Vous avez finalement accompli le projet The Green Earth Post, que vous allez sans doute fêter ce soir avec vos collaborateurs. Vous avez défini et implémenté une architecture du site, assuré ses performances partout dans le monde, ainsi que sa sécurité contre les attaques informatiques. Et vous avez également mis en place les outils nécessaires pour la surveillance des performances du site web pour l'équipe du journal.
Regardez le chemin parcouru depuis que vous avez commencé ce cours : non seulement vous vous êtes très bien préparés pour la certification, mais vous vous êtes également mis dans la peau d'un architecte de solutions et avez réussi à mener à bien un projet avec un peu d'aide 😉. J'espère que vous vous sentez maintenant bien armé pour passer l'examen !
Si vous voulez vous assurer que vous avez bien consolidé vos connaissances pour l'examen, je vous recommande de revoir le contenu de ce cours et/ou de passer quelques examens blancs.
Avant de vous dire au revoir, je vous invite à passer le dernier quiz pour conclure la partie 4 du cours.
Bonne chance sur cette dernière ligne droite. Et je vous souhaite le meilleur dans votre parcours professionnel !
