Affichez les données pertinentes avec SELECT
Dans la partie précédente, nous avons beaucoup parlé de la structure de la base de données : ce sont les bases de la modélisation relationnelle. À partir de maintenant, on entre vraiment dans le cœur du sujet : comment interroger les données qui sont dans la base.
Autrement dit, on considère que la BDD est déjà construite et déjà remplie, c'est-à-dire que les clés primaires, clés étrangères et tables d'association sont toutes déjà présentes. Pas besoin de les définir vous-même !
Mais du coup, pourquoi tu nous as embêtés avec tout ça ?
Pour les requêtes SQL que vous allez voir, vous devez absolument maîtriser ces notions, sinon vos requêtes n'auront ni queue ni tête. Si vous voulez apprendre à construire votre BDD de zéro (on appelle cela « modéliser » une BDD), il y a un cours dédié à cela : vous aurez même le droit de sauter les chapitres sur les clés primaires et étrangères.
Il existe différents types de requêtes SQL :
certaines pour créer des tables ;
d'autres pour aller chercher des données dans la base ;
d'autres pour modifier des données existantes ;
d'autres pour gérer les droits d'accès des utilisateurs/utilisatrices.
Celles sur lesquelles on va travailler, ce sont les requêtes pour aller chercher des données dans la base. Pour les reconnaître, rien de plus simple, elles ont toute une structure commune, contenant les mots clés SELECT et FROM :
SELECT [...] FROM [...]Souvent, d'autres mots clés seront ajoutés, comme par exemple WHERE, qui est très fréquent.
Si vous devez rechercher une information dans la base, vous avez d'abord besoin de savoir dans quelle table elle se situe, puis sur quelle ligne, et enfin dans quelle colonne. Ce sont les 3 infos essentielles. À chacune de ces 3 infos correspond l'un des mots clés que l'on vient de voir :
FROM : pour spécifier la/les table(s) ;
SELECT : pour sélectionner la/les colonne(s) demandée(s) ;
WHERE : pour filtrer les lignes de cette table et trouver la/les ligne(s) souhaitée(s).
Dans les 3 premiers chapitres de cette partie, nous allons voir comment fonctionne chacun de ces 3 mots clés.
Exécutez une requête SELECT
Commençons par SELECT à travers cette démonstration :
Ici, je vous propose de retrouver dans la base de données notre mystérieuse société Big Data Crunchers Limited.
Ce sera le point de départ de notre enquête ! Toutes les sociétés de la base de données se trouvent dans la table entity . Familiarisons-nous avec cette table, grâce à la requête la plus basique qui soit : celle qui renvoie une table sans la modifier :
SELECT * FROM entity ;Voici la réponse renvoyée :
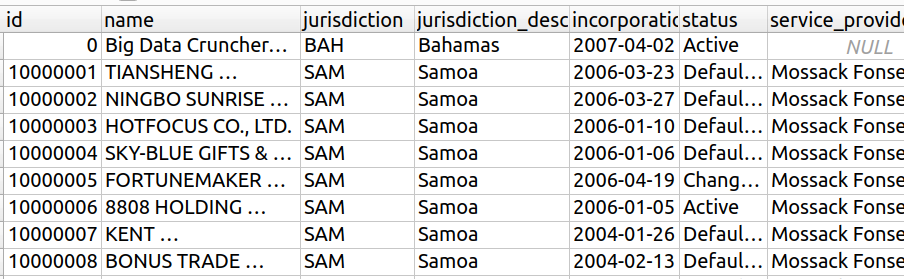
Avec cette requête, on a toutes les lignes et les colonnes de entity (attention, sur cette illustration, on ne voit pas toutes les lignes ni toutes les colonnes.)
Pour le moment, nous avons mis le caractère * derrière le SELECT. Cette étoile signifie que nous souhaitons obtenir toutes les colonnes disponibles.
Nous pouvons cependant remplacer ce caractère par les colonnes que nous souhaitons sélectionner ; par exemple :
id: c'est l'identifiant de la société dans notre BDD ;name: c'est le nom de la société ;status: c'est le statut de la société (au moment de la publication des Panama Papers) : est-elle active ? inactive ? dissoute ? en liquidation ? etc. Rassurez-vous, pas besoin de connaître la signification de ces termes : je ne les maîtrise même pas moi-même.
SELECT id, name, status FROM entity ;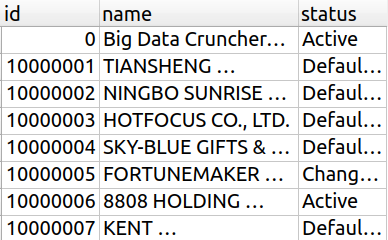
Quand vous sélectionnez certaines colonnes, il est possible que vous vous retrouviez avec des lignes 100 % identiques : c'est ce que l'on appelle des doublons. En fonction de ce que vous voulez faire, il sera souvent utile de supprimer les doublons en ne gardant qu'un exemplaire de chaque ligne. Pour ceci, il faut insérer DISTINCT juste après le SELECT :
SELECT DISTINCT status FROM entity;
Ici, on voit que parmi les quelques 200 000 lignes que contient la table entity , la colonne status ne contient que 18 valeurs différentes.
De même, si vous soupçonnez la table entity de contenir des lignes identiques, vous pouvez écrire une requête qui renverra la table entity , mais sans les doublons :
SELECT DISTINCT * FROM entity ;Réalisez des calculs sur vos données grâce aux fonctions et opérateurs
Quand on manipule des données, on est souvent amené à faire des calculs ou des modifications sur celles-ci. Par exemple, si vous devez convertir un poids exprimé en kg vers des grammes, il faudra multiplier par 1 000 votre valeur. Pour cela, il est possible d'appliquer des fonctions et des opérateurs sur les colonnes.
En SQL, pour utiliser une fonction, il faut écrire le nom de cette fonction, puis la faire suivre de parenthèses. À l'intérieur de ces parenthèses, on indique les données en entrée. Les données d'entrée de la fonction, c'est un peu ce que l'on “donne à manger” à la fonction, afin qu'elle modifie ces données (ou qu'elle effectue un calcul mathématique avec), puis qu'elle renvoie une donnée en sortie. Certaines fonctions ne prennent pas de données en entrée, certaines en prennent une ou plusieurs. Quand il y en a plusieurs, on les sépare par une virgule.
Voici quelques exemples :
SELECT upper('Bonjour')Ici on a utilisé la fonction upper, qui modifie un texte en le mettant en majuscules. On a le nom de la fonction suivi de parenthèses. Entre les parenthèses, on a donné en entrée le texte Bonjour . Si vous exécutez cette requête dans votre SGBRD, vous verrez que le résultat est BONJOUR .
SELECT round(3.1416, 2)Ici on a utilisé la fonction round, qui calcule l'arrondi d'un nombre décimal. Il y a ici deux données en entrée. La première donnée, c'est le nombre décimal à arrondir (ici 3.1416). La seconde, c'est le nombre de décimales à garder : ici on souhaite garder 2 décimales. Cette fonction renverra donc 3.14 , car c'est l'arrondi de 3.1416 avec 2 décimales.
SELECT random()La fonction random ne prend aucune donnée en entrée, et elle renvoie en sortie un nombre choisi au hasard.
Et un opérateur, c'est quoi ?
Un opérateur, c'est une fonction. Mais… c'est une fonction un peu particulière, car elle ne s'écrit pas avec la même syntaxe que ce nous avons vu jusqu'à présent. Elle s'écrit souvent avec des caractères spéciaux.
Par exemple, la fonction qui permet d'additionner deux nombres (disons 3 et 5, par exemple) ne s'écrit pas additionner(3, 5) mais elle s'écrit avec l'opérateur + . En effet, c'est bien plus lisible comme ça, regardez :
SELECT 3+5Cette requête renvoie 8, car 3+5 = 8.
Voyons quelques exemples de fonctions et opérateurs dans cette vidéo :
Utilisez des fonctions pour des calculs mathématiques
Par exemple, nous pouvons utiliser la fonction multiplication, en multipliant l'identifiant de toutes les entités par 2 (et pourquoi pas ?).
SELECT id * 2, name, status FROM entity ;Ici, pour écrire la multiplication on a utilisé l'opérateur * .
Il est même possible de combiner des fonctions. Par exemple, calculons la valeur absolue (fonction ABS() ) de l'opposé (que l'on écrit avec l'opérateur - ) de l'identifiant multiplié par 2 :
SELECT ABS( (- id) *2 ) AS calcul_bizarre, name, status FROM entity ;Utilisez des fonctions de manipulation de texte
Il existe beaucoup d'autres types de fonctions ! Par exemple, des fonctions sur des chaînes de caractères (c'est-à-dire du texte). Si on souhaite obtenir le nom d'une société, et ajouter à cette chaîne son statut entre parenthèses, on peut utiliser l'opérateur || . Assembler plusieurs textes les uns à la suite des autres, ça s'appelle une concaténation :
SELECT name || '(' || status || ')' AS name_and_status FROM entity ;Il est possible de transformer du texte en minuscules, ou en majuscules, grâce aux fonctions lower() et upper() . Par exemple, la requête suivante sur la table entity affiche 3 colonnes :
le nom d'origine des sociétés ;
le nom des sociétés en minuscules ;
le nom des sociétés en majuscules.
SELECT name, lower(name), upper(name) FROM entityManipulez des dates
Il y a également des fonctions utilisant des dates, comme par exemple date(), qui renvoie la date actuelle :
SELECT date()Utilisez des opérateurs de comparaison
Les opérateurs de comparaison sont des fonctions qui renvoient une valeur booléenne (c'est-à-dire une valeur binaire : VRAI ou FAUX). Voici un exemple :
SELECT date() > incorporation_date FROM entity ;Ici, la fonction date() renvoie la date actuelle. Celle-ci est ensuite comparée à la colonne incorporation_date grâce à l'opérateur de comparaison > , qui renvoie TRUE (ou 1 selon votre SGBD) si incorporation_date est antérieure à la date actuelle, ou bien FALSE (ou 0 ) dans le cas contraire.
Nous aurons l'occasion de revenir aux opérateurs de comparaison un peu plus tard.
Ceci n'est qu'un petit aperçu des types de fonctions existantes. Chaque SGBDR possède ses propres fonctions. Parfois, une même fonction n'aura pas le même nom d'un SGBDR à l'autre (ex. : la fonction date() en SQLite s'appellera plutôt current_date() dans d'autres SGBDR). Pour avoir un aperçu des fonctions disponibles dans SQLite, rendez-vous sur cette page.
À vous de jouer

Contexte
Dans la BDD des Panama Papers, les pays et juridictions sont souvent désignés avec un code à 3 lettres. Comme vous ne les connaissez pas par cœur, vous avez besoin d'un tableau de correspondance entre ces codes et le nom de ces pays. Cette correspondance est donnée dans la table country .
Consignes
Écrivez une requête qui renvoie les colonnes code et country de la table country .
Ensuite, écrivez une requête qui renvoie 2 colonnes :
la colonne
idde la tablecountry;une colonne contenant le code du pays puis son nom en toutes lettres, ces 2 informations devant être séparées par le caractère
-. Vous renommez cette colonne encode_et_nom.
Vérifiez votre travail
Pour afficher les colonnes code et country, il faut placer ces 2 colonnes dans le SELECT :
SELECT code, country FROM country ;Pour afficher sur une même colonne l'identifiant et le nom, il faut les assembler avec l'opérateur de concaténation || :
SELECT id, code || ' - ' || country AS code_et_nom FROM country ;En résumé
Le SELECT sert à sélectionner une ou plusieurs colonnes d'une table.
On fait suivre le SELECT par les colonnes à sélectionner, séparées par une virgule.
On peut sélectionner toutes les colonnes d'une table avec le caractère
*.On peut renommer des colonnes grâce au mot clé AS.
On peut appliquer des fonctions scalaires aux colonnes afin d'effectuer des opérations dessus.
Maintenant que nous avons vu comment sélectionner des colonnes, nous allons voir au chapitre suivant comment sélectionner des lignes !
