
Your Task
The website team wants to make it a bit more fun for customers to order pizza. They want to add a pizza button to their website called Adventure Time, which will automatically generate a set of ingredients that a person can order, and the chefs will cook. They saw an article by an MIT team and asked you if you can do something similar.
Understand the Data
You have been lucky enough to find the exact same data (here's a link) that the team used and load it up:
import numpy as np
data_pizza = np.load("datasets/recipes/data_pizza.npy")data_pizza.shape(200,)
You have 200 pizza recipes in there. Let's check them out:
from pprint import pprint
for entry in data_pizza[0:3]:
pprint(entry){'categories': ['pizza'],
'directions': ['Preheat oven to 400 degrees F (200 degrees C). Grease a 9x13 '
'inch baking dish. Place ground beef in a large, deep skillet. '
'Cook over medium high heat until evenly brown. Stir in '
'pepperoni, and cook until browned. Drain excess fat. Stir in '
'pizza sauce. Remove from heat, and set aside.',
'Cut biscuits into quarters, and place in the bottom of baking '
'dish. Spread meat mixture evenly over the biscuits. Sprinkle '
'top with onion, olives and mushrooms.',
'Bake uncovered in a preheated oven for 20 to 25 minutes. '
'Sprinkle top with mozzarella and Cheddar cheese. Bake an '
'additional 5 to 10 minutes, until the cheese is melted. Let stand '
'10 minutes before serving.'],
'ingredients': [[1, '', 'beef', ''],
[0.25, '', 'sausage', 'sliced'],
[1, '', 'sauce', ''],
[2, '', 'buttermilk', 'refrigerated'],
[0.5, '', 'onion', 'sliced_separated'],
[1, '', 'black', 'sliced'],
[1, '', 'mushroom', 'sliced'],
[1.5, '', 'mozzarella_cheese', 'shredded'],
[1, '', 'cheese', 'shredded']],
'servings': ''}
{'categories': ['pizza'],
'directions': ['Preheat the oven to 375 degrees F (190 degrees C).',
'Cook bacon in a large skillet and over medium-high heat, '
'turning occasionally, until evenly browned, about 10 minutes. '
'Drain bacon on paper towels and cool.',
'Pour oil into a 12-inch cast iron skillet. Brush oil all over '
'the interior of the skillet. Place dough into the pan and '
'shape into a pizza, forming a crust at the edge. Prick dough '
'all over with a fork.',
'Bake in the preheated oven for 5 minutes. Remove from oven '
'and reshape dough if necessary. Sprinkle the top of the dough '
'with 2 teaspoons of ranch seasoning. Top with shredded '
'mozzarella, chicken, and red onion. Crumble cooled bacon on '
'top.',
'Bake in the preheated oven until cheese is melted and top is '
'browned, about 20 minutes.',
'Remove pizza from the oven and top with tomato slices. Melt '
'butter and mix in the remaining dry ranch seasoning. Brush '
'crust with butter-ranch mixture.',
'Set an oven rack about 6 inches from the heat source and '
"preheat the oven's broiler.",
'Broil pizza until cheese is golden brown, 2 to 3 minutes, '
'being careful not to burn.'],
'ingredients': [[4, '', 'bacon', ''],
[2, '', 'vegetable_oil', ''],
[1, '', 'crust', 'refrigerated'],
[6, '', 'mozzarella_cheese', 'shredded'],
[0.3333333333333333, '', 'chicken', 'cubed'],
[0.125, '', 'onion', 'sliced'],
[1, '', 'tomato', 'sliced'],
[1, '', 'butter', '']],
'servings': ''}
{'categories': ['pizza'],
'directions': ['Preheat the oven to 400 degrees F (200 degrees C). Roll out '
'the bread dough into a rectangle, and spread out on a baking '
'sheet greased with olive oil. Set aside.',
'Place potato slices in a saucepan with enough water to cover. '
'Bring to a boil, and cook for about 5 minutes. Add bacon '
'slices to the water, and cook for an additional 5 minutes. '
'Drain. Remove bacon, then dice.',
'While the potatoes and bacon cook, melt the butter in a '
'skillet over medium heat. Add the onion, and cook, stirring '
'until tender. Remove from heat and stir in cream; season with '
'salt, pepper and nutmeg.',
'Spread the onion mixture over the bread dough. Arrange potato '
'slices evenly, and sprinkle with bacon.',
'Bake for 10 minutes in the preheated oven, until crust is '
'golden on the bottom. Let stand for a few minutes before '
'slicing.'],
'ingredients': [[18, '', 'bread', 'refrigerated'],
[1, '', 'olive_oil', 'needed'],
[1, '', 'potato', 'sliced'],
[3, '', 'bacon', ''],
[0.25, '', 'butter', ''],
[0.5, '', 'onion', 'chopped'],
[0.75, '', 'cream', ''],
[1, '', 'nutmeg', ''],
[None, '', 'pepper', '']],
'servings': ''}
:waw: Information overload!
ingredients_only = [t['ingredients'] for t in data_pizza]Check it out:
ingredients_only[0][[1, '', 'beef', ''],
[0.25, '', 'sausage', 'sliced'],
[1, '', 'sauce', ''],
[2, '', 'buttermilk', 'refrigerated'],
[0.5, '', 'onion', 'sliced_separated'],
[1, '', 'black', 'sliced'],
[1, '', 'mushroom', 'sliced'],
[1.5, '', 'mozzarella_cheese', 'shredded'],
[1, '', 'cheese', 'shredded']]
Now create a single string per pizza recipe from these ingredients:
joined_ingredients = []
for set_of_ingredients in ingredients_only:
str_ingredients = ''
for ingredient in set_of_ingredients:
str_ingredients += ' '.join([str(t) for t in ingredient]) + ' '
joined_ingredients.append(str_ingredients.replace(' ', ' '))Did it work?
joined_ingredients[0]'1 beef 0.25 sausage sliced 1 sauce 2 buttermilk refrigerated 0.5 onion sliced_separated 1 black sliced 1 mushroom sliced 1.5 mozzarella_cheese shredded 1 cheese shredded '
That looks better. Now make it simpler and join up all the text in one large part:
text = ' '.join(joined_ingredients).lower()Confirm the Data Format
You will need to take some steps to ensure the data is in the right format.
Step 1:
As you know, machines aren't good at words or characters, but they are when it comes to numbers, so let’s first convert every character to numbers:

Step 2:
You will build a character generation model that receives one character at a time and generates the next. For example, if your text is”great,” you feed “g” into the model and expect it to predict “r.” You have a lot more text than one word, so you need first to split it into chunks for the model:

Step 3:
The chunks will be converted into input and target datasets. Input datasets are on the left, and target datasets on the right.
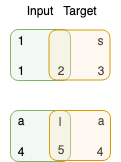
Step 4:
Create batches of the input and target datasets to use for training.
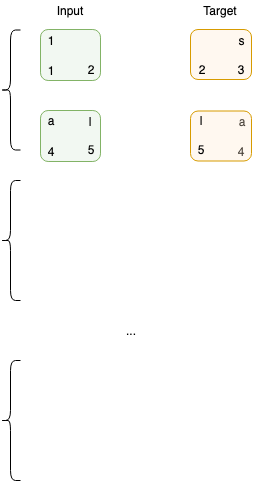
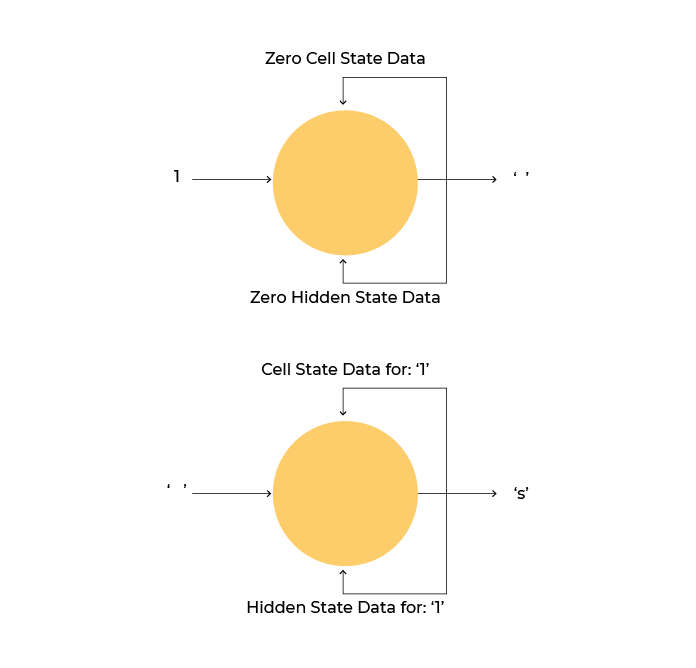
The model will finally see the data like this:
Create Batches of Data
Step 1:
Convert the joined ingredients into a list of numbers:
vocabulary = sorted(set(text))
character_to_number = {}
for idx, character in enumerate(vocabulary):
character_to_number[character] = idx
number_to_character = np.array(vocabulary)
print(f'There are {len(vocabulary)} different characters in the vocabulary')There are 39 different characters in the vocabulary.
character_to_number{' ': 0,
'.': 1,
'0': 2,
'1': 3,
'2': 4,
'3': 5,
'4': 6,
'5': 7,
'6': 8,
'7': 9,
'8': 10,
'9': 11,
'_': 12,
'a': 13,
'b': 14,
'c': 15,
'd': 16,
'e': 17,
'f': 18,
'g': 19,
'h': 20,
'i': 21,
'j': 22,
'k': 23,
'l': 24,
'm': 25,
'n': 26,
'o': 27,
'p': 28,
'q': 29,
'r': 30,
's': 31,
't': 32,
'u': 33,
'v': 34,
'w': 35,
'x': 36,
'y': 37,
'z': 38}
Convert the ingredients text to an array of numbers:
text_as_numbers = [character_to_number[character] for character in text]Let's see how the characters map:
print(f'"{text[:13]}" maps to:{text_as_numbers[:13]}')1 beef 0.25 s" maps to:[3, 0, 14, 17, 17, 18, 0, 2, 1, 4, 7, 0, 31]
Step 2:
Split the text into chunks. The chunk length (sequence_length) is 15 here as it should cover most of an ingredient, but feel free to change it however you want and try it out. You will also notice that 1 is added to this length. That is because the chunk will further be split into training and target data. To continue our example from earlier on, “great” will be converted into an input chunk “grea” and target chunk “reat” such that the algorithm always sees the next character.
chunk_length = 15
chunk_length_with_extra_character = chunk_length + 1
chunks = []
for idx in range(0, len(text_as_numbers), chunk_length_with_extra_character):
chunks.append(text_as_numbers[idx:idx+chunk_length_with_extra_character])
print(f'You split the text into {len(chunks)} of {chunk_length} characters')You split the text into 1807 of 15 characters
Let's check the chunks:
for number_chunk in chunks[:5]:
text_chunk = [number_to_character[item] for item in number_chunk]
print(f"Number sequence: {number_chunk}")
print(f"As text: {''.join(text_chunk)}")
print('')Number sequence: [3, 0, 14, 17, 17, 18, 0, 2, 1, 4, 7, 0, 31, 13, 33, 31]
As text: 1 beef 0.25 saus
Number sequence: [13, 19, 17, 0, 31, 24, 21, 15, 17, 16, 0, 3, 0, 31, 13, 33]
As text: age sliced 1 sau
Number sequence: [15, 17, 0, 4, 0, 14, 33, 32, 32, 17, 30, 25, 21, 24, 23, 0]
As text: ce 2 buttermilk
Number sequence: [30, 17, 18, 30, 21, 19, 17, 30, 13, 32, 17, 16, 0, 2, 1, 7]
As text: refrigerated 0.5
Number sequence: [0, 27, 26, 21, 27, 26, 0, 31, 24, 21, 15, 17, 16, 12, 31, 17]
As text: onion sliced_se
Step 3:
Now convert all the chunks into input (x) and target (y) chunks:
x = []
y = []
for chunk in chunks:
x.append(chunk[:-1])
y.append(chunk[1:])And let's take a look:
print(f"Input chunk: {''.join([number_to_character[item] for item in x[0]])}")
print(f"Target chunk: {''.join([number_to_character[item] for item in y[0]])}")Input chunk: 1 beef 0.25 sau
Target chunk: beef 0.25 saus
Step 4:
Now create batches of these chunks:
batched_x = []
batched_y = []
for idx in range(0, min(len(x), len(y)), batch_size):
if (
len(x[idx:idx+batch_size]) == batch_size and
len(y[idx:idx+batch_size]) == batch_size
):
batched_x.append(np.asarray(x[idx:idx+batch_size]))
batched_y.append(np.asarray(y[idx:idx+batch_size]))You now have batches of data to train with:
print(f'You have {len(batched_x)} batches of {len(batched_x[0])} '
f'chunks of {len(batched_x[0][0])} characters each.')You have 28 batches of 64 chunks of 15 characters each.
Set Up Your First Recurrent Neural Network
Your first layer in the model will be an embedding layer. The embedding layer will convert the characters from having values from 0 to 39 to being represented by vectors, which allows the model to capture relationships between the characters. The embedding layer has the following configuration:
Input shape is the size of the vocabulary.
Batch_input_shape will be the size of the batches above - 64.
Output shape will be the size of the vector that the characters will be transformed into - this is set to 256 dimensions, but feel free to change it.
Next, add an LSTM layer with a memory size of 256. Set them up to return sequences such that the output is of the shape (number of samples, number of time steps, LSTM units) and be stateful - remember information between batches.
The output layer has to be able to output the next character in the sequence. That means it needs to have as many neurons as there are characters in your vocabulary. For this final layer, use a dense setup with linear activation.
You will need to change the embedding layer to accept smaller batches so bring everything together into one function that builds the model for you:
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.models import Sequential
def create_model(batch_size):
input_layer = Embedding(
input_dim=len(vocabulary),
output_dim=256,
batch_input_shape=[batch_size, None]
)
hidden_layer = LSTM(
units=256,
return_sequences=True,
stateful=True
)
output_layer = Dense(units=len(vocabulary), activation='softmax')
rnn_model = Sequential([
input_layer,
hidden_layer,
output_layer,
])
return rnn_modelAnd now call it:
rnn_model = create_model(batch_size)
rnn_model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (64, None, 256) 9984
_________________________________________________________________
lstm_1 (LSTM) (64, None, 256) 525312
_________________________________________________________________
dense_1 (Dense) (64, None, 39) 10023
=================================================================
Total params: 545,319
Trainable params: 545,319
Non-trainable params: 0
_________________________________________________________________
Your target data is encoded as numbers and not one-hot as usual, so you need to use sparse categorical cross-entropy instead of normal cross-entropy to make the algorithm aware of this:
rnn_model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy'
)This time around, you will be saving the model as it trains after every epoch. That is because you want to change the embedding layer's settings to from using batches of 64 chunks data to only use one chunk when using the model.
Set up Keras to store the model during training:
import os
from tensorflow.keras.callbacks import ModelCheckpoint
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback = ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True
)And start training:
history = rnn_model.fit(
batched_x,
batched_y,
epochs=200,
callbacks=[checkpoint_callback],
batch_size=batch_size
)Epoch 197/200
1/1 [==============================] - 0s 71ms/step - loss: 0.5649
Epoch 198/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5392
Epoch 199/200
1/1 [==============================] - 0s 103ms/step - loss: 0.5526
Epoch 200/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5175
The model is trained. It's now time to build a new version of it that takes in 1 batch of 1 character:
from tensorflow.train import latest_checkpoint
from tensorflow import TensorShape
latest_checkpoint = latest_checkpoint(checkpoint_dir)
single_input_rnn_model = create_model(batch_size=1)
single_input_rnn_model.load_weights(latest_checkpoint)
single_input_rnn_model.build(TensorShape([1, None]))To generate lists of ingredients, first determine the average size of a list of ingredients from your input data:
average_length_ingredients = np.mean([len(t) for t in joined_ingredients])
print(average_length_ingredients)143.5
Use this value and round it up:
output_sequence_length = int(np.round(average_length_ingredients))
print(output_sequence_length)144
To run the model, you can choose a starting character that will then be converted to a number and fed to the model. The model will output a probability from 0 to 100% of what the next character should be. Let's try it:
starting_character = 'a'And now call the model:
# convert starting character to a number and store it as a (batch, sample)
model_input = [[character_to_number[s] for s in starting_character]]
# store the generated text in here
generated_text = []
# reset the model
single_input_rnn_model.reset_states()
for i in range(output_sequence_length):
predictions = single_input_rnn_model.predict(model_input)
# np.argmax only returns the max of the predictions
predicted_id = np.argmax(predictions)
# use the predicted character as input now
model_input = np.array([np.array([predicted_id])])
generated_text.append(number_to_character[predicted_id])
print(starting_character + ''.join(generated_text))atonion sliced_seast 1 gliced 1 mushroom 1 beef 0.25 saustared 1 clove 1 oril 1 crust refrigerated 0.5 onion chopped 1 dreded 1 chopped 1 green_o
You have now trained your first Recurrent Neural Network! Congratulations
Let’s Recap!
When building RNNs, it’s common to split an input text series into smaller batches that are then used to train on.
Embedding layers will convert input data into vectors that better capture the information between data points i.e., some data points group together or stay at similar distances from others.
To add an LSTM layer, grab one from keras.layers.
The stateful setting for the LSTM layer in Keras allows the RNN to maintain its memory between batches.
Model parameters can be saved during training and re-loaded later using a ModelCheckpoint callback.
Now you know how more advanced types of networks work. But it's not ever yet! The BONUS chapter coming up next will provide a brief introduction to more advanced architectures and use cases!
