Pour rappel, DuckDB peut lire directement de nombreux formats de fichiers, comme CSV, Parquet, Delta Lake et bien d’autres.
Cependant, dans un pipeline de données classique, il est souvent nécessaire d’ingérer des données provenant d’APIs. Votre manager vous a demandé de récupérer et centraliser des données depuis une API et depuis un fichier statique pour comparer l’usage réel des langages dans DuckDB avec leur popularité générale dans le monde.
Pour ce faire, vous allez suivre quatre grandes étapes dans ce chapitre et le suivant :
Exploration des données : Comprendre le format des données et la manière dont elles sont représentées à travers quelques requêtes simples en DuckDB.
Ingestion et centralisation des données : Extraire les langages du dépôt DuckDB via l’API GitHub, structurer ces données, les enrichir avec un dataset statique (popularité des langages sur Stack Overflow) et les centraliser dans une base de données DuckDB.
Transformation des données : Appliquer les transformations nécessaires et exporter les données pour obtenir un dataset final prêt à être visualisé.
Visualisation avec DuckDB : Représenter ces informations sous forme de graphiques (bar chart).
Regardez cette vidéo pour visualiser les deux premières étapes.
Explorez les données
Découvrez la source de données GitHub
L’API GitHub fournit les langages sous forme de JSON brut, avec une structure clé-valeur. Chaque langage est associé au nombre de bytes utilisés dans le repository GitHub où se trouve le code source. L’endpoint (adresse de l’API) pour accéder à ces informations est public et suit le format suivant :
1. Pour consulter les informations liées au projet DuckDB, vous allez utiliser “duckdb/duckdb” pour le nom de l’organisation et du repository. L’endpoint correspondant est donc :
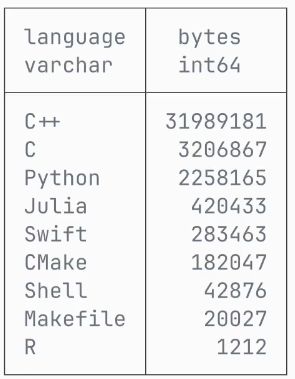
Cela veut donc dire qu’il y a dans le projet DuckDB, 31 785 575 bytes de code en C++, 3 205 177 bytes de code en C, etc.
Découvrez la source de données Stack Overflow Survey
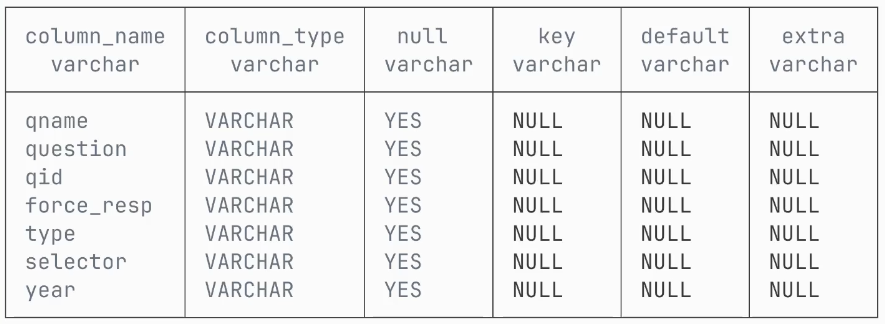
Stack Overflow réalise chaque année une étude sur les préférences des développeurs. Plusieurs milliers d’entre eux, à travers le monde, y participent. Nous allons utiliser les données de l’édition 2024. Le dataset est hébergé sur AWS S3 et contient deux fichiers Parquet : survey_results.parquet(les données des réponses) et survey_schemas.parquet(les données sur le schéma des réponses, incluant les questions, etc.).
Chaque question est représentée par une colonne dans le fichiersurvey_results.
1. Pour explorer un aperçu des données du fichier survey_results.parquet, utilisez une requête simple dans DuckDB :
FROM 's3://us-prd-motherduck-open-datasets/stackoverflow_survey/2017_2024/survey_results.parquet' limit 5;
Le résultat attendu est :
Capture d'écran du résultat attendu
2. Pour explorer la structure des questions et des réponses, interrogez le fichier survey_schemas.parquet avec :
Comme nous l'avons vu dans les exemples précédents, DuckDB permet d'exécuter des requêtes directement sur AWS S3. Pour des transformations légères, il est tout à fait possible d'effectuer ces opérations en mémoire, sans déplacer les données localement. Cependant, une bonne pratique consiste à centraliser les données dans une seule base DuckDB. Cela améliore les performances et réduit le trafic réseau entre AWS S3 ou l'API GitHub et le client DuckDB.
Nous allons donc créer des tables DuckDB à partir des données de l'API GitHub et des fichiers statiques stockés sur AWS S3.
Lancez un processus DuckDB et créez une base de données
Suivez les étapes ci-dessous :
1. Démarrez un nouveau processus DuckDB et attachez une base de données, que nous appellerons openclassrooms.db, pour stocker vos données. La commande ATTACHpermet de créer ou d’attacher une base de données existante.
ATTACH 'openclassrooms.db'
2. Créez une table depuis l’API GitHub avec la requête suivante :
CREATE TABLE openclassrooms.repo_languages AS
UNPIVOT read_json_auto('https://api.github.com/repos/duckdb/duckdb/languages')
ON COLUMNS(*)
INTO
NAME language
VALUE bytes;
Comment peut-on décomposer la requête ?
CREATE TABLE ... AS: crée une table à partir d’une requête.
UNPIVOT: transforme le format JSON en une structure plus adaptée à l’analyse, avec une colonne “languages” et une colonne “bytes” via la commandeINTO … NAME/VALUE. Cela indique le nombre d’octets utilisés par chaque langage.
SansUNPIVOT, DuckDB créerait une colonne distincte par langage, ce qui ne serait pas optimal pour votre analyse.
read_json_auto: analyse automatiquement la réponse JSON de l’API et génère les colonnes correspondantes.
Cette requête récupère les données depuis l’endpoint de l’API GitHub et convertit la réponse en une table avec deux colonnes : language (langage de programmation) et bytes (quantité de code utilisée dans le projet).
Voici le résultat attendu :
Capture d'écran du résultat attendu
3. Créez une table à partir des fichiers statiques de l’enquête Stack Overflow avec la requête suivante :
CREATE TABLE openclassrooms.stack_overflow_popularity AS WITH lang_popularity AS
(SELECT LANGUAGE,
COUNT(*) AS COUNT
FROM
(SELECT UNNEST(STRING_SPLIT(LanguageHaveWorkedWith, ';')) AS LANGUAGE
FROM 's3://us-prd-motherduck-open-datasets/stackoverflow_survey/2017_2024/survey_results.parquet'
WHERE YEAR = '2024') AS languages
GROUP BY LANGUAGE),
total_responses AS
(SELECT SUM(COUNT) AS total
FROM lang_popularity)
SELECT LANGUAGE,
COUNT,
(COUNT * 100.0 / total) AS popularity_percentage
FROM lang_popularity,
total_responses;
Comment peut-on décomposer la requête Stack Overflow ?
Cette requête analyse la popularité des langages de programmation dans les réponses au questionnaire de Stack Overflow et stocke les résultats dans une table.
: Les données sont chargées directement depuis un fichier Parquet stocké sur S3. DuckDB permet de lire ce fichier sans téléchargement préalable, optimisant ainsi l'analyse sur des ensembles de données volumineux.
LanguageHaveWorkedWith: Cette colonne contient une liste de langages séparés par ;:
STRING_SPLIT(LanguageHaveWorkedWith, ';')divise cette liste en éléments distincts.
UNNEST(...)transforme ces éléments en lignes individuelles.
GROUP BYet COUNT: On regroupe ensuite les données par langage et on compte combien de fois chaque langage est mentionné.
SUM: On additionne toutes les occurrences pour obtenir le nombre total de mentions de langages.
COUNT * 100.0 / total: En divisant le nombre d’occurrences d’un langage par le total, on obtient son pourcentage de popularité.
4. Vous avez maintenant deux tables créées dans votre base de donnéesopenclassrooms.db. Pour afficher le résultat, tapez cette commande :
SHOW ALL TABLES;
Et voici le résultat :
Capture d'écran du résultat
En résumé
DuckDB peut interroger directement des fichiers distants et des APIs sans nécessiter d’importation préalable, grâce à des fonctions comme read_json_auto(),qui permet de charger automatiquement des données JSON en table sans configuration manuelle.
DuckDB optimise la gestion des données, permettant d’effectuer des requêtes en mémoire ou de stocker les données dans un fichier unique.
Passons maintenant à la transformation et à l’exportation des données.