Dans le chapitre d'introduction de ce cours, on est parti du principe que le concept de données massives (Big Data) était connu : nos applications et nos objets génèrent de plus en plus données qui sont porteuses de valeur et que l'on doit analyser pour en extraire cette valeur. On peut éventuellement créer des modèles relativement complexes à partir de ces données : des algorithmes de machine learning permettent de créer ces modèles. Dans le cas général, la quantité de données nécessaires à l'apprentissage d'un modèle est une fonction exponentielle de la dimension du modèle.
Mais cette description de nos besoins en données est relativement abstraite. Et surtout, elle ne dit pas comment on doit gérer nos données. Or, c'est précisément cette question qui intéresse les data architects, et c'est celle à laquelle nous allons répondre dans ce cours. Donc, pour bien comprendre les critères auxquels doit répondre une architecture big data, on va partir d'un scénario d'exemple relativement simple.
Imaginons que vous soyez en charge de l'administration d'une application web qui connaît un certain succès. Des utilisateurs visitent le site, s'inscrivent, réalisent des recherches et consultent des pages. Pour mesurer l'évolution de la popularité de votre application, vous devez mettre en place les deux fonctionnalités suivantes :
Pour chaque page du site, donner le nombre de visites qu'elle a reçues.
Lister les 100 pages ayant reçu le plus grand nombre de visites.
En somme, vous devez réaliser un Google Analytics simplifié.
Vous souhaitez professionnaliser vos compétences ? Jetez un oeil sur les formations big datas proposées par OpenClassrooms : architecture big data
Une architecture qui laisse des SQL
Votre application web utilise déjà une base de données MySQL, donc il paraît logique de stocker les données relatives aux visites dans cette même base. Pour implémenter les deux fonctionnalités demandées, vous n'avez besoin que d'une tablevisitsdotée de deux colonnes :url(de type VARCHAR) etcount(de type BIGINT). Nous allons voir pourquoi ce choix technique ne permet pas de passer à l'échelle.
Au début, c'est votre application web qui incrémente directement les valeurs decountà chaque visite :
UPDATE visits SET count = count + 1 WHERE url = "http://www.plonk.com/index.html"Ce mécanisme fonctionne correctement tant que vous n'avez pas énormément de visites. Mais avec le temps, votre application devient de plus en plus populaire et vous avez un nombre de pages et de visites de plus en plus grand. Vous vous rendez compte que l'incrémentation des valeurs prend de plus en plus de temps. Et pour cause : les bases de données SQL ne sont pas faites pour supporter un grand nombre d'écritures concurrentes.
On pourrait imaginer une succession de solutions différentes à ce problème : vous pourriez par exemple créer une file d'événements qui seront ensuite traités par lot (100 à la fois) par des workers fonctionnant en parallèle. Mais avec l'augmentation du trafic, vous parviendriez toujours à la même conclusion : l'écriture en base SQL est un goulot d'étranglement ("bottleneck") que vous ne pouvez pas surmonter. Vous pourriez contourner ce problème en répartissant les lignes de la tablevisitssur différents serveurs : c'est la solution dite de sharding (une shard est alors une partie de la table). Mais cela rend l'administration de la base de données considérablement plus complexe et source de bogues. Par exemple, pour ajouter un shard, vous devez réaliser une manipulation hasardeuse consistant à déplacer une partie des données vers le nouveau shard.
Not Only NoSQL
Vous décidez donc de remplacer MySQL par une solution NoSQL qui supporte nativement le sharding et assure la cohérence de vos données. Par exemple, vous choisissez MongoDb. Votre architecture ressemble alors à cela :
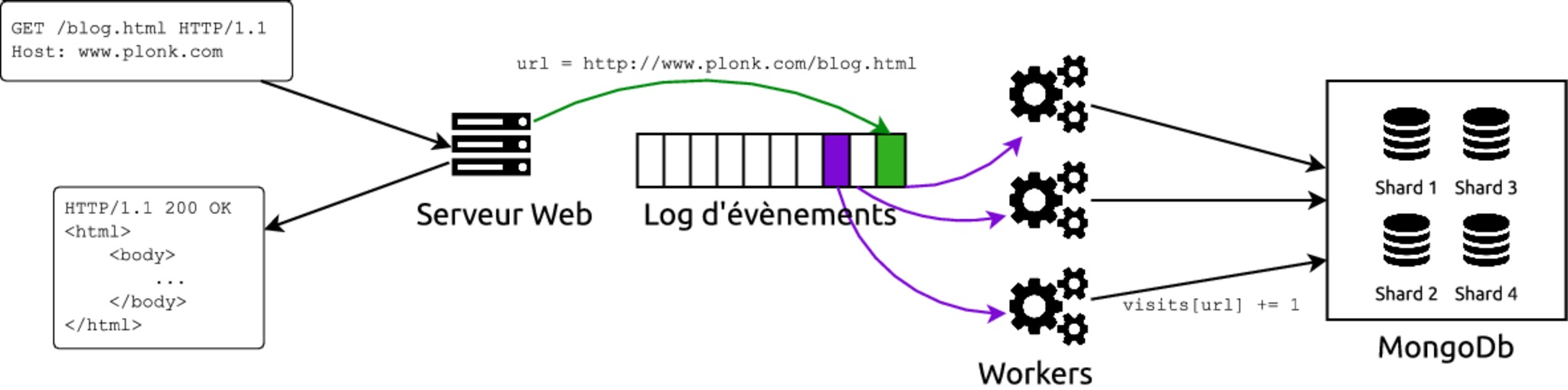
Cette architecture passe à l'échelle sans problème : elle va continuer de fonctionner en ajoutant de nouveaux workers et en augmentant le sharding de la base MongoDb au fur et à mesure de l'augmentation du nombre d'urls et de visites. Cependant, le code des workers évolue et un jour un développeur commet une erreur : au lieu d'incrémenter le nombre de visite pour chaque url de 1, certains workers incrémentent ce nombre de 2. Vous voilà bien ennuyé, puisque vous n'avez pas moyen de retrouver le décompte exact du nombre de visites pour les urls impactées. Vous êtes obligés d'informer les utilisateurs de votre service d'analytics que les stats de visite de votre site sont biaisées sur la période pendant laquelle le bogue a été mis en production.
La conclusion qu'on tire de cet exemple, certes théorique, mais au combien réaliste, c'est que les bases NoSQL sont indispensables au big data, mais ne sont qu'une partie de la solution. Vous ne pouvez pas vous contenter de ne stocker que le décompte agrégé des visites. Pour être à l'abri d'une erreur de programmation, vous devez faire en sorte que les statistiques de visites des différentes pages soient recalculables à tout instant. Pour cela, vous devez disposer du log intégral de toutes les visites. Vous serez alors en mesure de regénérer les statistiques agrégées à tout instant. Mais il faut alors se poser la question : quelle seront la forme et le support de ces données brutes ?
On pourrait commencer à rentrer dans les détails ce qui va en fait s'appeler un data lake, mais ça serait du spoil sur le reste de ce cours... Les contraintes qu'on a rencontrées dans ce scénario imaginaires vont en fait guider la description d'une solution globale à notre problème de données.
"Chooooooorando se foi"... sur le rythme endiablé de la lambda architecture
Il existe une solution complète et suffisamment générique pour pouvoir être appliquée dans la quasi totalité des cas nécessitant de manipuler des données massives : cette solution a été formalisée et décrite intégralement dans Big Data: Principles and best practices of scalable realtime data systems. Dans ce livre, les auteurs introduisent la notion d'Architecture Lambda que nous allons détailler dans le reste de ce cours.
La conception d'une architecture lambda est guidée par les contraintes suivantes :
Passage à l'échelle : l'architecture proposée doit pouvoir passer à l'échelle de manière horizontale, c'est à dire en ajoutant des serveurs. Cette croissance doit se faire en garantissant la robustesse et la tolérance aux pannes des différents systèmes.
Facilité de maintenance : les choix techniques réalisés ne doivent pas contraindre l'architecture à être figée dans le marbre. Il doit être aisé de déboguer et de modifier les applications exploitant cette architecture. Enfin, peu d'interventions manuelles doivent être nécessaires pour réaliser la maintenance des systèmes.
Facilité d'exploitation des données : le but d'une architecture lambda n'est pas uniquement de stocker des données, mais également de les mettre à disposition d'autres applications pour les exploiter et en extraire de la valeur. Il doit être possible de réaliser des analyses personnalisées sur ces données de manière aisée.
À partir de ces contraintes, ce que propose l'architecture lambda c'est de décomposer en trois couches ("layers") : la "batch layer", la "speed layer" et la "serving layer".
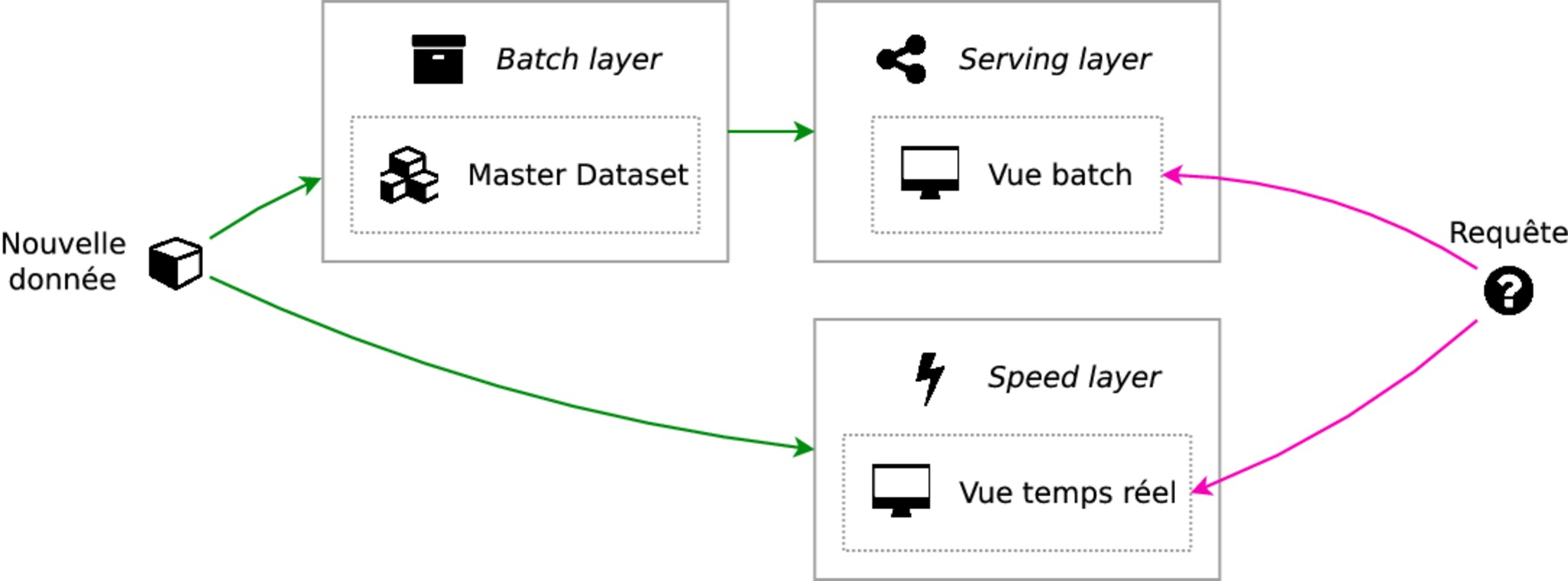
Les données reçues vont être collectées à l'état brut dans le master dataset qui se trouve dans la batch layer. Ces données seront agrégées et le résultat de ces agrégations sera exposée aux clients par une vue dans la serving layer. Les clients pourront alors faire des requêtes sur cette vue. Cependant, l'agrégation de données en batch prend du temps ; pour que les utilisateurs disposent à tout moment des données les plus fraîches, il est nécessaire de stocker les données collectées en temps réel durant le calcul en batch dans la speed layer. Ces données seront exposées aux clients dans une vue temps réel. Les clients devront donc faire la fusion de deux vues : la vue contenant les données traitées en batch, et la vue contenant les données temps réel.
Ce schéma n'est évidemment qu'une esquisse. Dans les chapitres qui suivent, on va rentrer dans le détails des différents blocs de cette architecture et voir comment ils répondent aux contraintes qu'on s'est fixées.
