Découvrez les défis en amont de l’apprentissage supervisé

Si vous avez déjà réalisé un projet d’apprentissage supervisé ou si vous avez suivi le cours “Maîtrisez l’apprentissage supervisé”, alors vous savez d’expérience qu’un modèle est entièrement tributaire de sa donnée en entrée (les features) qui elle-même est calculée à partir d’un jeu de données de départ dit “brut”.
En entreprise, ce jeu de données “brut” aux yeux du Data Scientist est rarement le vrai jeu de données brut. En réalité, nous avons souvent des jeux de données bruts qui permettent de construire le dataset de départ du Data Scientist. Ainsi, un projet de Machine Learning va fréquemment employer des données qui ne représentent que “le bout d'un iceberg”.
Dans un monde parfait, un Data Scientist n’aurait pas à s’intéresser aux rouages qui alimentent son dataset de départ, de la même manière que quand vous allumez votre lampe dans votre chambre, vous n’avez pas à vous soucier de comment votre appartement est connecté au réseau électrique de votre secteur. Malheureusement, les projets Data sont complexes et il est irréaliste de mener sérieusement un projet de ML en entreprise sans avoir une connaissance des défis rencontrés bien avant de pouvoir importer votre 1er DataFrame avec pandas.
L’objectif de cette 1ʳᵉ interview est justement de découvrir ensemble ces enjeux, via un cas d’usage chez Veepee et surtout via le témoignage de notre 1ᵉʳ expert Victor. On se retrouve juste après pour débriefer !
Lexique
Compute : Dans le jargon de la Data, on dit “Le projet nécessite du Compute” pour dire qu’un projet a besoin d’une machine avec une puissance de calcul significative. Dans un contexte Cloud, on paie pour du Compute à la demande. Autrement dit, on loue des ressources (machines virtuelles) pour une durée limitée afin de lancer certains calculs.
Data Platform : Sur le plan technique, il s’agit du système central de gestion des données et de leurs cycles de vie. Dans l’exemple de Veepee, elle regroupe les profils Data Engineering et Data Gouvernance.
Data gouvernance : De manière très simpliste, il s’agit de l’ensemble des guidelines et des bonnes pratiques à mettre en place pour garantir le bon usage de la donnée et des outils de la Data Platform. Nous renvoyons vers l'article de l'experte Charlotte Ledoux, sur la Data Gouvernance, pour en savoir plus.
Analytics Engineering : Un nouveau métier dans le monde de la Data, à mi-chemin entre Data Analyst et Data Engineer. Certains le qualifient de Data Engineer orienté business ou de Data Analyst avec une expertise technique plus forte.
Stack : On parle souvent de Stack technique quand on veut désigner l’ensemble des technologies utilisées pour réaliser les projets Data de bout en bout (de l’ingestion des données jusqu’à la mise en production). Comme les technologies et les pratiques évoluent beaucoup, on parle souvent de Modern Data Stack aujourd’hui, vous pouvez en savoir plus dans ce guide détaillé sur les technologies de data stack moderne, comme lecture d’approfondissement.
Cloud Warehouse : Plus connu sous le nom de Data Warehouse. Il s’agit d’une base de données hébergée dans le cloud, à l’opposé d’une base de données "On Premise" qui est hébergée dans des serveurs ou ressources physiques de l’entreprise. En outre, il s’agit d’une base de données optimisée (au niveau du coût et de la rapidité) pour des besoins d’analyse de données.
Mart : abréviation de Data Mart. C’est l’entrepôt qui va héberger toutes les données destinées aux analystes de données. Cela se présente généralement sous forme d’une base de données de plusieurs tables, que les Data Scientists peuvent requêter en SQL pour construire leur ETL. Ils choisissent comme dans un catalogue les données qu’ils veulent utiliser.
DBT : Il s’agit d’un software très utilisé aujourd’hui par les profils Data. Il est entièrement spécialisé dans la transformation des données en SQL. C’est un outil qui va plus loin qu’un simple éditeur de code SQL, car il propose une intégration très facile avec Git, des tests unitaires et d’autres fonctionnalités très intéressantes.
Kafka : C’est une plateforme de données spécialisée dans les traitements de données à très haute vitesse (pratiquement en temps réel). Dès que vous entendrez quelqu’un parler de Kafka, c’est qu’il travaille sur un projet avec une haute contrainte d’avoir des calculs et des résultats en temps réel.
C’était dense et riche en info ! Nous allons justement distiller tout ça dans les paragraphes qui suivent. ;)
Saisissez les enjeux de la qualité de données
Pour illustrer les challenges de qualité de données rencontrés chez Veepee, Victor a choisi un exemple très intéressant : le renseignement des descriptions des produits en ligne. Cet exemple est riche pour plusieurs raisons.
Premièrement, on y retrouve un classique de la data quality : les données déclaratives. Ce sont des informations qui nécessitent une intervention manuelle pour être saisies dans les systèmes. Autrement dit, la valeur doit être déclarée par un humain pour être renseignée. On peut alors facilement y retrouver des informations qui manquent de précision, pour des raisons diverses et variées.
Sur ce point, Victor nous parle des catégories de produits qui peuvent être mal renseignées :
Car les commerciaux vont trouver cela plus facile dans leur système de saisie de renseigner un produit d'une certaine manière et qu’ils ont développé une habitude par rapport à cela.
Car un commercial peut changer de compte (et donc de typologie de produits sous sa responsabilité) mais sans qu’il change les catégories de produits qu’il renseigne.
On ne peut pas particulièrement reprocher ce décalage à qui que ce soit ! Quand on n’est pas exposé à un projet Data, on ne peut pas deviner que toute donnée renseignée peut apporter de la valeur tangible à l’entreprise pour laquelle on travaille !
Considérez ainsi comme acquis le fait que toute donnée déclarative cache a priori un biais de saisie sous-jacent. À contrario, les données saisies par des systèmes automatisés (comme des capteurs de températures) sont beaucoup moins assujetties à ce biais humain aléatoire.
Le deuxième point intéressant dans l’exemple de Victor concerne la répartition des rôles et des responsabilités pour traiter ces catégories mal renseignées :
Les Data Scientists vont assainir des cas complexes comme ceux cités plus haut (données renseignées, mais avec peu de précision) en utilisant des méthodes comme des embeddings.
Alors que les équipes Data Engineering et Data Gouvernance vont traiter des cas beaucoup plus “évidents” mais plus problématiques et plus fréquents : des catégories qui ne sont pas du tout renseignées ou renseignées de manière absurde.
Vous avez souvent entendu que le cleaning et le preprocessing de la donnée représentent la majeure partie des projets Data, et ce, pour tous les profils Data. Il y a donc une famille de problèmes de qualité “simples” mais fréquents, qui concernent toutes les équipes, pour lesquelles il est peu pertinent de faire appel à l’expertise ML d’un Data Scientist.
Les équipes Data Platform vont venir utiliser des outils permettant de détecter des anomalies sur ces cas “relativement simples”. Victor a cité comme exemple l’implémentation de règles de type “une variable catégorielle ne peut faire partie que d’une liste finie de valeurs” ou “un montant ne peut pas être en moyenne supérieur à un montant seuil” etc.
Plus ces stratégies de contrôle de la donnée sont implémentées, moins les Data Scientists auront à se creuser la tête pour gérer intelligemment des valeurs manquantes - qui ne devraient pas l’être - et plus ils pourront migrer leurs efforts vers d’autres réflexions que seuls eux peuvent adresser.
C’est une phrase qui nous fait aussi une transition parfaite avec la section qui suit ;)
Mesurez l’importance de la visibilité des données
Cette notion de visibilité a été abordée largement pendant l’interview, via deux concepts clés : Le Data Contract et la Data Observability.
Commençons par le Data Contract. On voit pendant l’interview que ce concept possède 2 facettes :
La partie “descriptive” : liste des champs, leurs métadonnées, quel système source, quel format de données en sortie, la fréquence de rafraîchissement, comment cette donnée est consommée et par qui (stockage dans un dossier, mise à disposition d’une API etc.)
L’implémentation technique : génération des API, pipelines et tout le nécessaire pour transformer la donnée envoyée par les systèmes sources en la donnée cible accessible aux profils Data techniques, tout en précisant tous les éléments de la partie descriptive du contrat associés à ces transformations.
Si un code d’implémentation de ce concept vous intéresse, vous pouvez jeter un coup d’œil à cet article par exemple qui utilise Protobuf, le même outil que Victor a mentionné.
Parlons de la Data Observability ensuite ! C’est un concept qui englobe en réalité le Data Contract.
On peut dire que le Data Contract est un moyen et que la Data Observability est la finalité. De la même manière, les tests dont parlait Victor pour le renseignement des catégories de produit sont des moyens de mise en œuvre de l’observabilité.
Il existe d’ailleurs bien d’autres moyens. Entre autres, on trouve la notion de Data Lineage qui devient de plus en plus un incontournable des équipes Data.
Le Data Lineage répond à un besoin de traçabilité de la donnée. Prenons l’exemple concret suivant :
Mon script d'entraînement de mon modèle de ML n’a pas fonctionné car mon dataset initial n’a pas été rafraîchi, car les tables sous-jacentes n’ont pas été rafraichies.
C’est l’équipe Data Engineering qui est responsable des tables sous-jacentes, donc je n’ai pas la main pour corriger le tir moi-même.
Mais je ne sais pas quel Data Engineer ou Analytics Engineer contacter, chacun étant spécialisé sur certaines tables.
Ma seule façon d’aller le savoir est d’aller chercher dans le code SQL des data engineers où se trouve mon nom de table et de deviner par tâtonnement qui contacter.
C’est typiquement le genre de problème rencontré quand un Data Lineage n’existe pas, ce qui fait perdre inutilement beaucoup de temps aux Data Scientists, Data Analysts et tout profil arrivant en bout de chaîne des pipelines de transformation de la donnée !
La solution est de mettre en place une traçabilité qui prend souvent la forme d’un graphe et ressemble à quelque chose comme ceci :
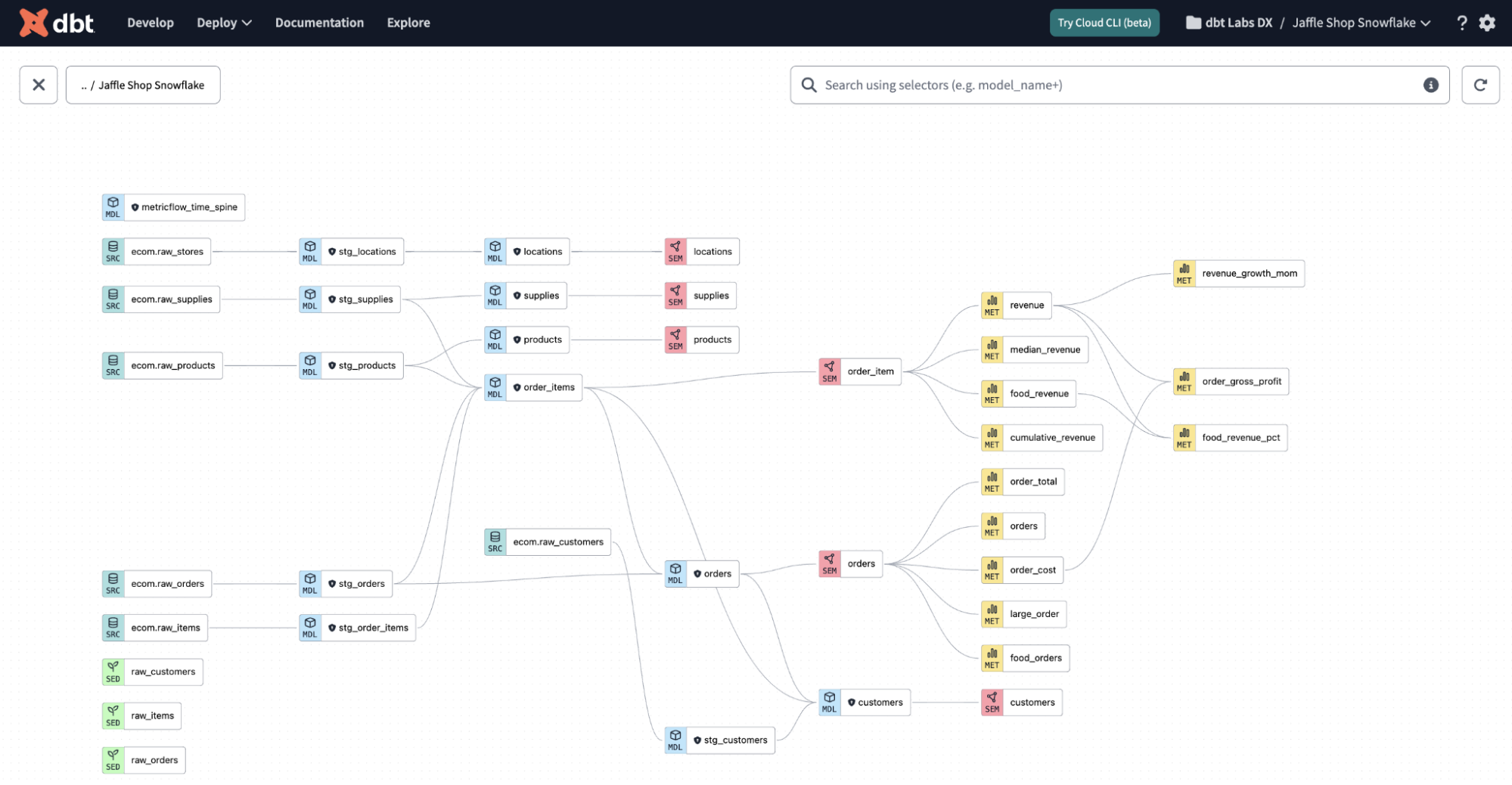
Au final, avec l’observabilité des données, le Data Scientist peut consulter de manière autonome et à n’importe quel moment l’état de qualité de son jeu de données ainsi que l’existence ou non d’une anomalie le concernant. On se rapproche un peu du monde parfait décrit au début du chapitre, où l’on peut importer notre dataset initial sur Pandas et se concentrer sur la partie ML sans avoir à se soucier du reste !
Pour en savoir plus, vous pouvez consulter cet article détaillé de l’entreprise Monte Carlo, un acteur très connu dans le domaine de la Data Observability
C’est pour cela que plusieurs entreprises avec des équipes Data établies vont avoir au sein de leurs effectifs plus de profils Data Engineer & Analytics Engineer que de profils Data Scientist & ML Engineer. Ce sont des entreprises qui ont bien compris que la qualité des données est la pierre angulaire derrière le succès de tout projet de Machine Learning ou de Business Intelligence.
Comprenez l’avantage de la disponibilité des données
Abordons effectivement un point, qui a été rapidement évoqué par Victor, sans être développé davantage pendant l’interview.
Il s’agit du fait que tous les visiteurs de Veepee ont un compte chez Veepee. Autrement dit, toutes les informations de navigation du site (passage d’une page web à l’autre, ajout au panier, achat etc.) peuvent être rattachées à un client dont on connaît les caractéristiques (et donc les features ;)).
C’est une richesse à ne pas sous-estimer et qui ne doit pas être considérée comme acquise ! Certains sites permettent la navigation sans compte client, voire l’achat sans compte client. Ce point a toute son importance quand nous souhaitons lancer un projet de ML pour personnaliser la recommandation d’un produit à un client, par exemple.
En effet, un site web qui ne demande à un client de s’identifier qu’au moment de l’achat, risquera de collecter un contexte de données partiel. On n’aura pas toute l’histoire du début jusqu’à la fin entre le 1ᵉʳ atterrissage sur le site et l’achat des articles, ce qui rend difficile des analyses complètes des patterns pour une majorité des clients
Ce manque de complétude n’impactera pas que les projets centrés autour du site web (comme la conception d’un système de recommandation en ligne), mais tout type de projet ML orienté client. Illustrons un exemple d’impact avec un exemple concret :
Vous souhaitez réaliser une modélisation ML pour identifier les clients qu’un service commercial doit appeler en priorité pour proposer des conditions de ventes avantageuses
La direction commerciale vous fournit une liste de 30k clients avec leur ID unique ainsi que les données de ventes passées et d’appels commerciaux
Afin d’avoir une vision complète de ces clients, vous souhaitez enrichir votre feature engineering avec des données issues de leur navigation du site web. Vous croisez alors ces 30k identifiants avec le dataset de tracking du site web.
Vous ne trouvez dans les données de navigation du site que 5k identifiants parmi 30k ! Justement parce que plusieurs clients n’ont jamais réalisé d’achat via le site
Cette situation n’est pas hors du commun pour des entreprises avec un modèle de vente hybride (physique et en ligne). Nous avons pris l’exemple d'appels commerciaux, mais l’histoire est la même pour d’autres projets classiques d’omnicanalité, comme les clusterings clients, les campagnes marketing hyperpersonalisés etc.
En résumé
Les jeux de données bruts utilisés par les Data Scientists sont souvent issus de plusieurs sources, et la qualité des données dépend des systèmes opérationnels. Comprendre leur cycle de vie est crucial pour anticiper les défis liés à la qualité et éviter les biais, notamment pour les données déclaratives (saisies manuellement).
La répartition des responsabilités est essentielle pour traiter les problèmes de qualité : les Data Scientists se concentrent sur des cas complexes (embeddings, valeurs imprécises), tandis que les Data Engineers et les équipes de gouvernance gèrent des problèmes fréquents mais simples (valeurs absentes, seuils incohérents) grâce à des règles automatisées.
La Data Observability et les Data Contracts permettent de garantir la traçabilité et la fiabilité des données. Les Data Contracts définissent les métadonnées, les transformations et la fréquence des données, tandis que l'observabilité englobe des outils comme la Data Lineage pour visualiser l’origine et les transformations des données dans tout l’écosystème.
La disponibilité des données complètes et connectées à des clients (comme chez Veepee) est un atout stratégique. Des identifiants clients bien intégrés permettent des analyses riches pour les projets ML (systèmes de recommandation, segmentation client), contrairement aux entreprises qui collectent des données partielles ou anonymes.
Le succès d’un projet ML repose sur des bases solides de qualité et d’accessibilité des données, nécessitant souvent davantage de profils techniques comme des Data Engineers que de Data Scientists. Ces rôles garantissent que les pipelines de données fonctionnent efficacement, minimisant les anomalies et optimisant les performances des modèles.
Après avoir découvert les défis liés à la qualité et à la disponibilité des données en amont des projets de Machine Learning, plongeons désormais en aval pour explorer comment répondre aux besoins métier complexes et assurer la réussite des déploiements !
