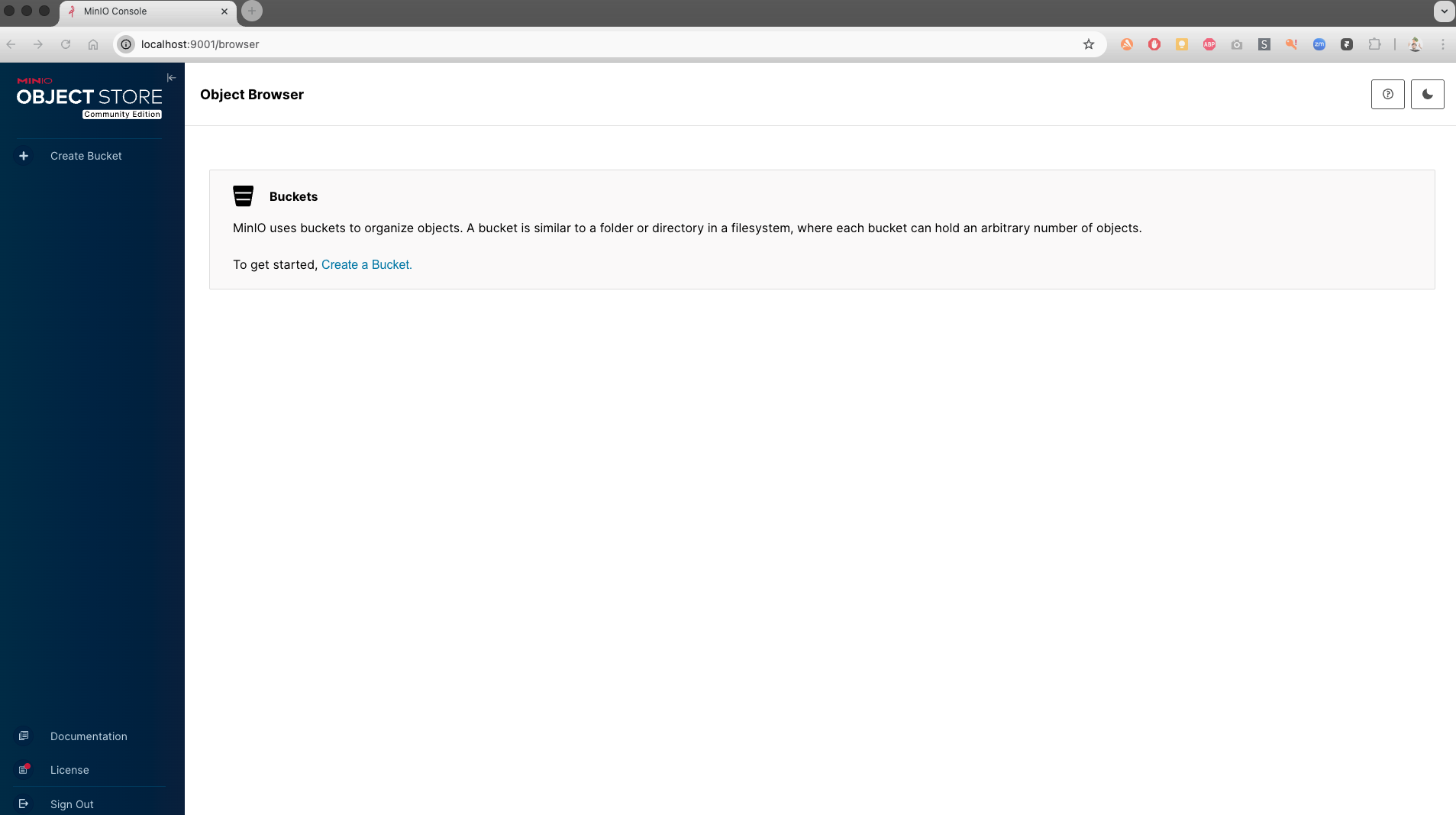
Mettez en place un Data Lake open source sous MinIO
Dans le chapitre précédent, GreenFarm a mis en place son premier Data Lake sur AWS S3. Cette solution cloud, robuste et scalable, permet de stocker des volumes massifs de données et de les rendre accessibles facilement aux équipes. C’est un excellent point de départ, mais GreenFarm ne souhaite pas mettre tous ses œufs dans le même panier.
Toutes les entreprises n’utilisent pas forcément AWS. Certaines privilégient Google Cloud Platform (GCP) avec Cloud Storage, d’autres Microsoft Azure avec Blob Storage. Ces services proposent des fonctionnalités similaires à S3, mais chacun avec ses spécificités. L’idée clé, c’est que la logique de Data Lake ne dépend pas d’un fournisseur unique : les principes restent les mêmes, quel que soit le cloud choisi.
Dans ce contexte, GreenFarm réfléchit déjà à des scénarios où elle aurait besoin de garder la maîtrise complète de son infrastructure, par exemple pour déployer certaines applications sensibles on-premise dans ses propres datacenters. Elle veut aussi pouvoir limiter ses coûts cloud et éviter une dépendance trop forte à un seul fournisseur. Enfin, ses développeurs aimeraient disposer d’un environnement de test local, leur permettant de prototyper des pipelines de données sans frais, tout en restant compatibles avec les APIs qu’ils utilisent en production.
C’est précisément ce que permet MinIO. Ce serveur de stockage objet open source, léger et performant, se déploie en quelques minutes sous forme de conteneur Docker. Son avantage majeur ? Il est nativement compatible avec l’API S3 d’Amazon. Cela signifie que tout le code Python que GreenFarm a écrit pour interagir avec AWS S3 fonctionnera immédiatement avec MinIO, sans modification.
Pour GreenFarm, la promesse est claire : expérimenter localement, apprendre à mieux maîtriser ses flux de données et préparer une architecture hybride ou multi-cloud, tout en gardant la continuité avec ses outils existants.
Déployez et configurez MinIO
Dans ce screencast, vous verrez comment GreenFarm déploie MinIO pour disposer d’un Data Lake local compatible avec AWS S3. Cet environnement leur permet de tester leurs pipelines sans dépendre du cloud, tout en conservant la même API et les mêmes pratiques que sur AWS.
Contenu de la démonstration :
Vérification du fonctionnement de Docker
Définition des identifiants administrateur pour MinIO (
minioadmin)Lancement d’un serveur MinIO en local via une commande Docker
Accès à la console web MinIO (
localhost:9001) et découverte de l’interfaceCréation d’un bucket MinIO dédié au projet GreenFarm
Mise en place d’un script Python utilisant Boto3 avec un
endpoint_urlMinIOUpload d’un fichier local dans le bucket MinIO avec la même logique que sur S3
Vérification dans la console web et démonstration de la compatibilité API S3
Pour tester cette alternative, l’équipe Data Engineering de GreenFarm décide de déployer MinIO sur les postes de développement. L’installation est extrêmement simple grâce à Docker. En une seule commande, le serveur MinIO démarre et expose deux interfaces : une API compatible S3 sur le port 9000, et une console web d’administration sur le port 9001.
export MINIO_ROOT_USER=minioadmin
export MINIO_ROOT_PASSWORD=minioadmin
docker run -p 9000:9000 -p 9001:9001 \
-e MINIO_ROOT_USER=$MINIO_ROOT_USER \
-e MINIO_ROOT_PASSWORD=$MINIO_ROOT_PASSWORD \
quay.io/minio/minio server /data --console-address ":9001"En quelques secondes, les ingénieurs de GreenFarm se connectent à l’interface web via http://localhost:9001. Ils peuvent y créer leurs premiers buckets, gérer les droits d’accès et explorer les objets stockés.
Mais l’intérêt principal reste la programmabilité. Grâce à boto3, la librairie Python qu’ils utilisent déjà avec AWS, ils peuvent piloter MinIO exactement de la même façon. La seule différence est qu’ils précisent l’endpoint local de MinIO au lieu de celui d’AWS.
import boto3
s3 = boto3.client(
"s3",
endpoint_url="http://localhost:9000",
aws_access_key_id="minioadmin",
aws_secret_access_key="minioadmin",
region_name="us-east-1"
)GreenFarm apprécie cette transparence : les scripts écrits pour AWS fonctionnent ici à l’identique. Mais, selon les usages, l’équipe aime aussi disposer d’outils “natifs MinIO” pour certaines opérations.
Alternative A — Utiliser le SDK MinIO (optionnel)
Quand ils veulent manipuler MinIO sans la surcouche AWS, les développeurs installent le SDK officiel :
pip install minioPuis ils initialisent un client orienté MinIO pour créer un bucket ou vérifier son existence :
from minio import Minio
client = Minio(
"localhost:9000",
access_key="minioadmin",
secret_key="minioadmin",
secure=False,
)
bucket = "greenfarm-datalake-demo"
if not client.bucket_exists(bucket):
client.make_bucket(bucket)Cette voie est pratique pour des scripts d’administration ciblés, tout en restant complémentaire de l’approche boto3 utilisée dans les pipelines.
Alternative B — Administrer avec MinIO Client (mc)
Les ops de GreenFarm préfèrent parfois la CLI d’admin pour des tâches rapides : déclarer un alias, créer un bucket, lister des objets, appliquer une policy.
# Installer mc (cf. doc MinIO), puis :
mc alias set local http://localhost:9000 minioadmin minioadmin
mc mb local/greenfarm-datalake-demo
mc ls local/greenfarm-datalake-demo
# Ex. ouvrir en lecture un préfixe processed (à adapter à vos besoins)
mc anonymous set download local/greenfarm-datalake-demo/processedEn quelques commandes, ils retrouvent les gestes du quotidien : création, listing, politiques d’accès.
Un autre avantage clé est que ces commandes peuvent être facilement intégrées dans des pipelines CI/CD. Cela signifie que GreenFarm pourrait, par exemple, automatiser la création et la configuration de ses buckets MinIO lors du déploiement d’un environnement de test ou de production, garantissant une infrastructure reproductible et cohérente à chaque fois.
En quelques lignes, GreenFarm a donc un environnement local qui imite fidèlement le comportement de S3. Les développeurs peuvent expérimenter en toute sécurité, sans consommer de ressources cloud.
Gérez les données dans MinIO
Une fois le serveur en place, les ingénieurs de GreenFarm commencent à y déposer des données. Comme pour AWS, ils créent un bucket qui servira de base à leur Data Lake local.
bucket_name = "greenfarm-datalake-demo"
s3.create_bucket(Bucket=bucket_name)Dans ce bucket, ils reproduisent la même organisation que sur AWS : une zone raw/current pour les fichiers bruts, une zone processed pour les données transformées et une zone raw/archived pour conserver l’historique.
Par exemple, lorsqu’ils reçoivent un fichier JSON contenant les mesures des capteurs IoT installés dans leurs champs, ils l’ajoutent directement dans la zone brute :
s3.upload_file("iot.json", bucket_name, "raw/current/iot.json")
print("Fichier JSON déposé dans raw/current/")Pour vérifier que le fichier est bien là, ils listent le contenu du bucket :
resp = s3.list_objects_v2(Bucket=bucket_name, Prefix="raw/")
for obj in resp.get("Contents", []):
print(" -", obj["Key"])On peut également vérifier que le fichier à été chargé via l’interface graphique de Minio:
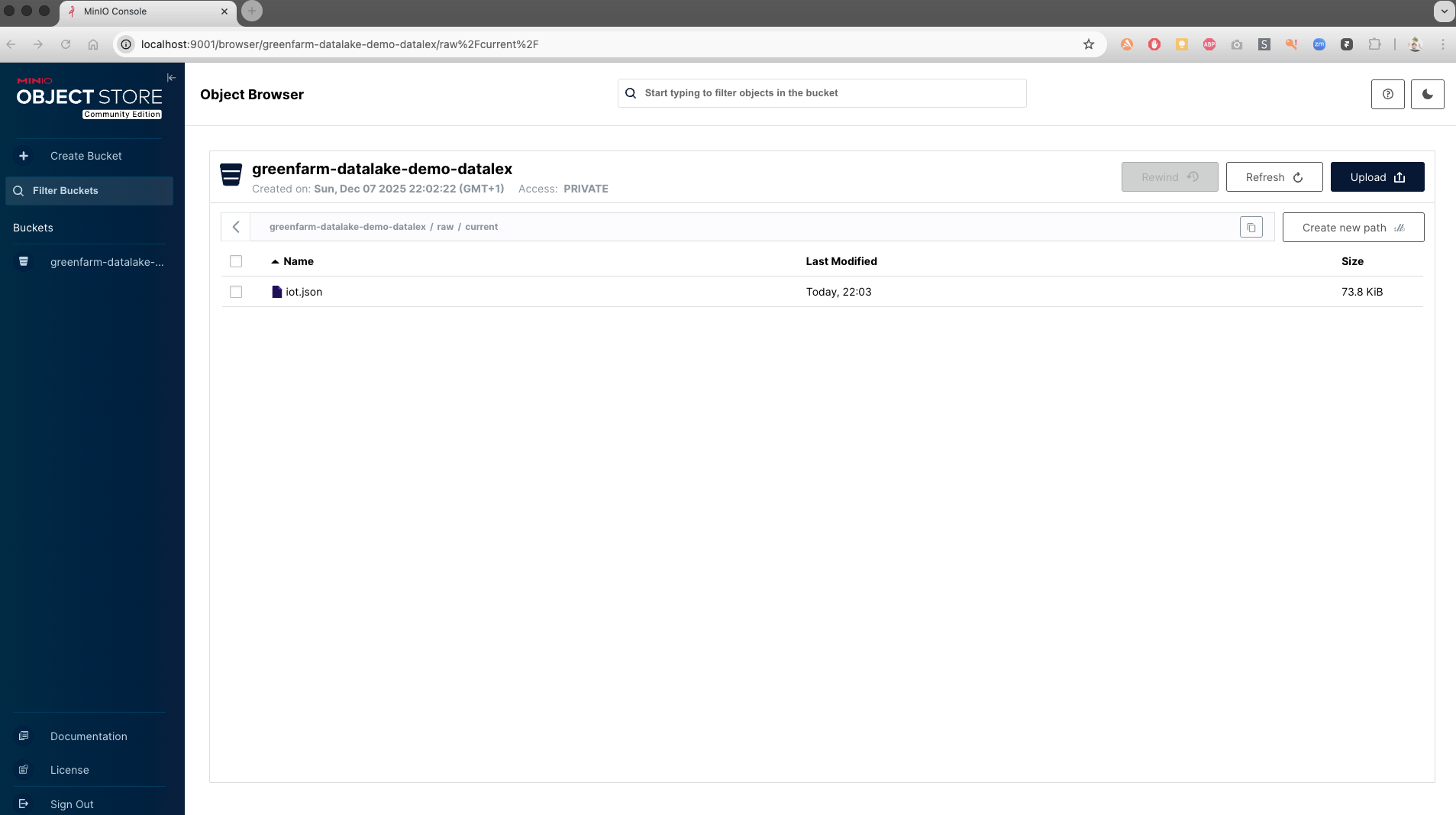
Ce qui est intéressant pour GreenFarm, c’est que tout fonctionne exactement comme sur AWS. Les ingénieurs n’ont pas à réapprendre de nouvelles commandes ou bibliothèques. Ils gèrent leurs données de la même manière, que ce soit dans un environnement cloud ou open source.
Créez un flux de données avec MinIO
GreenFarm ne veut pas seulement stocker ses fichiers : elle veut aussi en faire des pipelines complets, même dans cet environnement de test. Les données IoT sont un excellent cas d’usage pour valider ce fonctionnement.
Le fichier brut, iot.json, contient des mesures de température et d’humidité relevées toutes les quelques secondes par différents capteurs. Voici un extrait :
[
{"device_id": "capteur_01", "timestamp": "2025-08-30T10:15:00Z", "temperature": 22.5, "humidity": 45},
{"device_id": "capteur_02", "timestamp": "2025-08-30T10:15:05Z", "temperature": 23.1, "humidity": 47}
]La première étape du pipeline consiste à lire ce fichier brut et à préparer les données pour l’analyse. Les data engineers de GreenFarm utilisent pandas pour convertir le champ timestamp en un objet datetime manipulable.
import pandas as pd
df = pd.read_json("iot.json")
df["timestamp"] = pd.to_datetime(df["timestamp"])
print(df.head())Ensuite, ils appliquent une transformation simple pour enrichir le jeu de données. Ici, ils choisissent de renommer la colonne temperature en temp_c pour plus de clarté et de calculer une moyenne glissante sur trois mesures consécutives.
df = df.rename(columns={"temperature": "temp_c"})
df = df.sort_values(["device_id", "timestamp"])
df["temp_c_roll3"] = df.groupby("device_id")["temp_c"].rolling(3, min_periods=1).mean().reset_index(level=0, drop=True)Une fois les données préparées, ils les stockent dans un format optimisé pour l’analyse, le Parquet, et les déposent dans la zone processed.
df.to_parquet("iot.parquet")
s3.upload_file("iot.parquet", bucket_name, "processed/iot.parquet")
print("Fichier transformé stocké dans processed/")Enfin, pour garder la zone raw/current propre, le fichier brut est archivé avec un horodatage dans son nom.
import datetime
raw_key = "raw/current/iot.json"
ts = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
archived_key = f"raw/archived/iot_{ts}.json"
s3.copy_object(
Bucket=bucket_name,
CopySource={"Bucket": bucket_name, "Key": raw_key},
Key=archived_key
)
s3.delete_object(Bucket=bucket_name, Key=raw_key)
print(f"Fichier brut archivé sous {archived_key}")En un seul pipeline, GreenFarm est donc capable de simuler la réception de données brutes, de les transformer et de gérer leur cycle de vie complet, le tout dans un environnement open source local.
Avec MinIO, GreenFarm a désormais un environnement de Data Lake qui reproduit fidèlement AWS S3, mais sans dépendance au cloud. Les ingénieurs peuvent tester, expérimenter et valider leurs pipelines en local, puis les déployer presque tels quels en production.
Ce double environnement – AWS S3 pour la production et MinIO pour le développement – donne à GreenFarm une grande souplesse et une vraie indépendance technologique.
À vous de jouer !

Contexte
GreenFarm souhaite vérifier que ses pipelines de données fonctionnent aussi bien sur MinIO que sur AWS S3.
Consignes
Reprenez exactement le même exercice que dans le chapitre précédent (P1C3) : ingestion d’un fichier JSON IoT, transformation en DataFrame pandas, enrichissement des données, sauvegarde en Parquet, puis archivage du fichier brut.
La seule différence : au lieu de pointer vers AWS S3, configurez votre code pour utiliser l’endpoint MinIO local (http://localhost:9000) avec les identifiants minioadmin / minioadmin.
Livrable : Docker + python
En résumé
MinIO est une alternative open source à AWS S3, simple à déployer (ex. via Docker).
Il est compatible à 100 % avec l’API S3, donc vos pipelines Python fonctionnent sans modification.
GreenFarm l’utilise pour prototyper en local, réduire sa dépendance cloud et garder la maîtrise de son infra.
On peut l’administrer via boto3, le SDK MinIO ou la CLI mc, avec possibilité d’intégrer ces commandes dans des pipelines CI/CD.
GreenFarm possède maintenant deux Data Lakes fonctionnels : l’un sur AWS S3 et l’autre sur MinIO. Mais si ces environnements ne sont pas structurés et gouvernés correctement, ils risquent de devenir de simples silos de fichiers difficiles à exploiter. La prochaine étape est donc essentielle : apprendre à structurer vos Data Lakes en différentes zones logiques et à mettre en place des règles de gouvernance claires pour transformer ces réservoirs de données en un véritable levier stratégique.
