Découvrez les approches modernes des Data Lakes
Explorez l'évolution des Data Lakes
Le terme Big Data s’est imposé au tournant des années 2010. Il illustre la révolution qui a permis à des domaines comme l’intelligence artificielle de faire des bonds spectaculaires, grâce à l’explosion de la quantité et de la diversité des données disponibles.
Jusqu’aux années 2000, les bases de données relationnelles (RDBMS) régnaient en maîtres. Elles étaient idéales pour stocker et analyser des données structurées (par ex. les commandes clients ou les transactions bancaires). Simples et fiables, elles suffisaient tant que les volumes restaient limités et prévisibles.
Mais au début des années 2000, avec la généralisation du web, l’explosion des smartphones et l’arrivée des objets connectés (IoT), les entreprises ont commencé à générer bien plus que de simples données tabulaires. C’est l’ère du Big Data, caractérisée par les fameux 5V :
Volume : des quantités massives de données produites en continu ;
Variété : une grande diversité de formats (logs web, images, vidéos, données IoT) ;
Vélocité : des flux rapides, parfois en temps réel, qu’il faut analyser sans délai ;
Véracité : des données parfois incomplètes ou bruitées, dont il faut garantir la qualité ;
Valeur : la nécessité d’extraire des insights utiles pour l’entreprise.
Face à ces nouveaux défis, les systèmes traditionnels ont rapidement montré leurs limites :
impossibilité d’absorber la variété des données modernes (logs web, images, vidéos, données IoT) ;
difficulté à gérer des volumes massifs en croissance continue ;
coûts et dépendances élevés avec les entrepôts de données traditionnels.
C’est dans ce contexte qu’Apache Hadoop, né en 2006 dans la fondation Apache, a marqué un tournant. Inspiré par les travaux de Google sur le traitement distribué, Hadoop a introduit un modèle inédit : stocker et traiter d’immenses ensembles de données sur un cluster de serveurs bon marché, plutôt que sur une seule machine puissante.
Son innovation repose sur deux briques principales :
HDFS (Hadoop Distributed File System) : un système de fichiers distribué, capable de stocker des volumes massifs de données en les répartissant automatiquement entre plusieurs machines.
MapReduce : un moteur de calcul distribué, qui divise une tâche complexe en sous-tâches parallèles, exécutées simultanément par les nœuds du cluster.
Grâce à cette approche, Hadoop a ouvert la voie au Data Lake, un réservoir capable d’accueillir tous types de données brutes, à grande échelle et à moindre coût.
Aujourd’hui, Hadoop reste utilisé, en particulier dans les entreprises qui maintiennent encore des infrastructures on-premise (sur leurs propres serveurs). Mais la tendance va de plus en plus vers des solutions managées de Data Lake proposées par les grands clouds :
AWS : Amazon S3 + EMR
Azure : Azure Data Lake Gen2 + Synapse / Fabrics ou Databricks
Google Cloud : Google Cloud Storage + BigQuery
Ces services offrent les mêmes principes qu’Hadoop (stockage distribué et calcul parallèle), mais avec une gestion simplifiée, de la scalabilité automatique et un coût ajusté à la consommation.
Comprenez ce qu’est un Data Lake
Un Data Lake est un dépôt centralisé qui permet de stocker une grande quantité de données dans leur format natif, sans transformation préalable. Contrairement à un Data Warehouse, qui impose une structure (schéma) avant l’ingestion des données, le Data Lake adopte une approche schema-on-read : les données sont stockées brutes et ne sont interprétées qu’au moment où elles sont utilisées.
Voici les caractéristiques clés d’un Data Lake :
Stockage brut et non intrusif : Un Data Lake ne force pas les données à s’adapter à un schéma unique. Les logs, vidéos, flux IoT ou fichiers CSV peuvent être déposés tels quels.
Support de tous les formats : Structurées (bases relationnelles), semi-structurées (JSON, XML, Avro, Parquet) ou non structurées (images, vidéos, sons).
Immutabilité et traçabilité : Les données stockées deviennent la “source unique de vérité” pour l’entreprise. Toute transformation se fait en créant une version dérivée, garantissant traçabilité et reproductibilité.
Évolutivité quasi infinie : Grâce à des systèmes distribués (HDFS à l’origine, puis S3, Azure Data Lake, etc.), un Data Lake peut croître sans limite, en ajoutant simplement du stockage ou des machines.
Économie et flexibilité : Le coût du stockage reste faible comparé aux entrepôts traditionnels, notamment grâce aux solutions cloud facturées “à l’usage”.
Catalogue et gouvernance : Pour éviter que le Data Lake ne se transforme en Data Swamp (marécage), des outils de catalogage (Hive Metastore, AWS Glue, Apache Atlas) assurent la gestion des métadonnées, la qualité et les droits d’accès.
👉 Pour GreenFarm, cela signifie qu’il est possible de stocker toutes vos données – mesures IoT dans les champs, images de drones, données météorologiques, ventes en magasin et en ligne, ainsi que données clients – au même endroit, à moindre coût, et sans se soucier de leur format.
Un Data Lake sert de fondation pour :
la Business Intelligence (rapports, tableaux de bord),
la Data Science et le machine learning,
le temps réel, avec ingestion de flux continus.
👉 Chez GreenFarm, cela signifie pouvoir :
analyser les ventes passées de produits bio pour anticiper la demande,
entraîner des modèles prédictifs sur les données météo et capteurs IoT afin d’optimiser l’irrigation et réduire la consommation d’eau,
monitorer en direct les champs grâce aux capteurs et aux drones pour réagir rapidement aux anomalies (sécheresse, maladies, nuisibles).
Comparez Data Lakes et Data Warehouses
On compare souvent Data Lake et Data Warehouse comme deux approches concurrentes. En réalité, elles répondent à des besoins différents et se complètent très bien dans une architecture moderne. Voici un tableau récapitulatif de leurs principales différences :
Critère | Data Warehouse (DW) | Data Lake |
Type de données | Structurées (tables, colonnes, lignes) | Tous types : structurées, semi-structurées, non structurées |
Schéma | Schema-on-write (défini avant ingestion) | Schema-on-read (défini au moment de l’analyse) |
Coût | Élevé (licences, infrastructure) | Plus faible (stockage brut, cloud scalable) |
Performance | Optimisé pour les requêtes SQL rapides | Peut nécessiter plus de préparation pour être performant |
Usages typiques | Business Intelligence, reporting historique, KPIs | Machine Learning, Data Science, exploration, temps réel |
Qualité & gouvernance | Forte, avec règles strictes | Variable, dépend de la gouvernance mise en place |
Évolutivité | Limitée et coûteuse | Quasi infinie (scalable horizontalement) |
Outils typiques | Microsoft BI, Teradata, Snowflake, Redshift, BigQuery | Hadoop, AWS S3, Azure Data Lake, Google Cloud Storage |
De plus en plus d’entreprises choisissent de combiner les deux approches :
le Data Lake sert de réservoir brut et économique,
le Data Warehouse extrait et structure une partie des données pour la rendre exploitable rapidement par les métiers.
Et une nouvelle génération d’architecture à émerger : le Lakehouse, qui vise à combiner le meilleur des deux mondes. Mais pas de panique… nous en reparlerons un peu plus tard dans ce cours 😉 (spoiler alert).
L’émergence du métier de Data Engineer
Pendant longtemps, les entreprises pouvaient se contenter de deux profils principaux :
les DBA (Database Administrators), chargés de gérer et maintenir les bases de données relationnelles,
et les Data Analysts, qui produisaient des rapports et analyses pour les métiers.
Mais avec l’essor du Big Data, des Data Lakes et la multiplication des formats et sources, ces rôles ne suffisaient plus. Les entreprises avaient besoin de profils capables de :
concevoir et maintenir des pipelines de données (collecte, ingestion, transformation, stockage),
garantir la qualité, la disponibilité et la sécurité des données dans des environnements distribués et massifs,
maîtriser les architectures modernes combinant Data Lake, Data Warehouse, streaming temps réel et outils cloud.
C’est ainsi qu’est né le métier de Data Engineer. 🛠️
👉 Chez GreenFarm, c’est exactement votre rôle :
faire en sorte que les données issues du site, du CRM, des capteurs IoT et drônes arrivent dans le Data Lake,
transformer ces données pour les rendre exploitables par les Data Scientists (qui entraînent des modèles d’IA) et par les Analystes (qui produisent des rapports BI),
et veiller à ce que l’architecture reste robuste, scalable et économique.
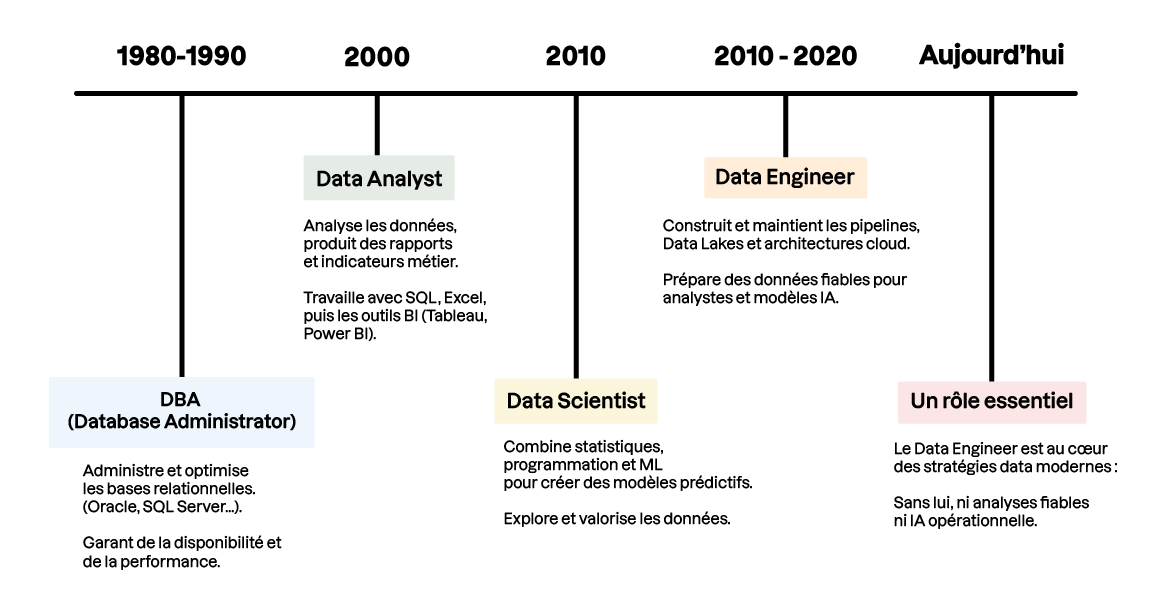
📚 L’évolution des métiers de la data
Années 1980-1990 – Le DBA (Database Administrator)
Garant du bon fonctionnement des bases relationnelles (Oracle, SQL Server, DB2…). Il installe, configure et administre les bases.Années 2000 – Le Data Analyst
Avec l’essor des entrepôts de données, il produit des rapports et indicateurs pour les métiers (finance, marketing, direction). Ses outils de prédilection : SQL, Excel, puis des solutions de BI comme Tableau ou Power BI.Années 2010 – Le Data Scientist
Avec l’explosion du Big Data et du Machine Learning, ce nouveau profil combine statistiques, programmation et business. Il explore les données et construit des modèles prédictifs.Années 2010-2020 – Le Data Engineer
Face à la complexification des architectures (Data Lakes, cloud, streaming), un nouveau rôle devient indispensable : celui qui construit et maintient les pipelines de données et les infrastructures qui alimentent analystes et data scientists.
👉 Aujourd’hui, le Data Engineer est un maillon essentiel de toute stratégie data moderne. Sans lui, pas de données fiables pour les analystes, ni de datasets prêts pour les modèles d’IA.
Choisissez les formats de données adaptés à votre Data Lake
Dans un Data Lake, toutes les données ne se valent pas : le format de stockage a un impact direct sur les performances, les coûts et la facilité d’exploitation.
CSV, JSON et XML : les formats simples mais limités
CSV (Comma-Separated Values)
Probablement le format le plus simple et universel.
Facile à lire, facile à écrire, largement supporté par tous les outils.
👉 Chez GreenFarm : un CSV peut suffire pour exporter rapidement une liste de partenaires ou d’exploitations agricoles, mais devient inefficace dès qu’on parle de millions de relevés IoT collectés chaque jour.
JSON et XML
Flexibles et auto-descriptifs, très utilisés pour l’ingestion de données venant d’APIs ou de logs.
Lisibles par un humain, mais très verbeux.
Peu adaptés à l’analytique à grande échelle : fichiers lourds, requêtes lentes, pas de compression optimisée.
👉 Chez GreenFarm : les données météorologiques issues d’APIs externes ou les flux IoT des capteurs de sol peuvent être stockés en JSON lors de l’ingestion.
Parquet, Avro et ORC : les formats optimisés pour les Data Lakes modernes
Parquet (le champion actuel 🏆)
Format colonnaire open source, pensé pour l’analytique.
Excellente compression et lecture sélective (on lit uniquement les colonnes nécessaires).
Massivement adopté dans les environnements modernes (Spark, Hive, Presto, BigQuery, Snowflake).
👉 Chez GreenFarm : analyser rapidement l’évolution de l’humidité du sol ou des ventes par région, sans lire l’intégralité des fichiers.
Avro
Format binaire compact, auto-descriptif (inclut le schéma).
Excellente gestion de l’évolution des schémas (ajout de champs sans casser la compatibilité).
Très utilisé pour la sérialisation et les flux (Kafka, streaming).
👉 Chez GreenFarm : conserver l’historique des mesures IoT ou des récoltes tout en permettant d’ajouter de nouveaux attributs (ex. ajout futur d’un capteur “qualité du sol”).
ORC (Optimized Row Columnar)
Format colonnaire performant, historiquement lié à l’écosystème Hadoop et Hive.
Très efficace pour les requêtes analytiques lourdes.
Moins universel que Parquet, mais encore largement utilisé dans certaines plateformes.
👉 Chez GreenFarm : intéressant si l’entreprise utilise encore une infrastructure Hadoop pour l’archivage de données agricoles.
La “guerre des formats” : pourquoi Parquet domine aujourd’hui
Dans les années 2010, ORC et Parquet se sont imposés comme les principaux formats analytiques. ORC a longtemps dominé dans les environnements Hadoop, mais Parquet a pris l’avantage grâce à :
sa compatibilité plus large (support natif dans la majorité des moteurs analytiques modernes),
ses optimisations de compression,
sa communauté et son adoption massive dans le cloud.
Aujourd’hui, Parquet est souvent le format par défaut dans les projets de Data Lake et de Lakehouse, tandis qu’Avro reste préféré pour la sérialisation et le streaming, et que ORC continue d’exister surtout dans des écosystèmes hérités.
En résumé
Les Data Lakes sont nés de l’essor du Big Data et des limites des entrepôts de données classiques.
Ils permettent de stocker tous types de données, à bas coût et sans schéma fixe.
Ils sont essentiels pour les architectures modernes et les cas d’usage avancés.
Leur mise en œuvre nécessite une réflexion sur les formats utilisés et les cas d’usage cibles.
Parquet et Avro sont vos meilleurs alliés pour la performance et l’évolutivité.
Bravo, et continuez sur cette lancée !
