Créez et qualifiez un ticket d’incident
Identifiez un incident
Nous allons voir dans ce chapitre comment créer un ticket d’incident dans GLPI, et étudier sa gravité pour définir l’ordre de priorité de traitement parmi toute la file d’incidents.
Mais tout d’abord, qu’est-ce qu’un incident au sens ITIL ?
Prenons comme exemple le service d’accès à Internet dont le débit normal serait défini comme supérieur à 50ko/s dans les SLA. Si un utilisateur se rend compte qu’il télécharge sur un débit de 70ko/s, même si c’est trop faible pour lui, ce n’est pas un incident car ça reste conforme aux SLA.
* La notion de niveau de service SLA est décrite dans la partie 1 de ce cours.
Un incident correspond donc à une interruption non planifiée ou une dégradation de la qualité d’un service informatique, qui sera donc souvent déclarée par un utilisateur.
Mais ITIL va plus loin : un incident est aussi une défaillance d’un élément de configuration n’ayant pas encore impacté le service, qui sera donc détecté par un outil de supervision de l’exploitation informatique.
Une fois que le technicien est informé de l’existence d’un incident, il va le prendre en charge dans l’objectif de le résoudre.
Que doit faire le technicien de support informatique lorsqu’il est avisé d’un incident ?
Le technicien va dérouler le processus ITIL de gestion des incidents (Incident Management, en anglais), dans l’objectif :
de restaurer dans les délais les plus courts le fonctionnement normal des services et de réduire au minimum l’impact sur les activités métiers/business (utilisateurs et clients) ;
et de s’assurer ainsi que les meilleurs niveaux de qualité de service et de disponibilité convenus sont maintenus, conformément au contrat de service (SLA).
ITIL structure l’organisation de la gestion des incidents, pour éviter l’écueil classique de mobiliser tous les informaticiens pour un incident qui peut être résolu directement par le technicien de support informatique.
En effet, le rétablissement du service normal dès que possible ne doit pas dégrader les autres activités (projets, études) menées par la DSI, qui doit respecter ses engagements en termes de délai, coût et qualité.
Identifions maintenant plusieurs cas typiques d’incidents.
Découvrez des exemples d’incidents plus ou moins graves
L’objectif de cette section est :
De citer des exemples d’incidents fréquemment rencontrés.
De commencer à catégoriser un incident et d’en évaluer la gravité.
Les pannes de matériel
La catégorie la plus fréquente d’incident concerne les pannes de matériel informatique :
panne d’un poste de travail (ordinateur fixe, PC portable, tablette, client léger…) d’un utilisateur ;
serveur hors service. Tous les utilisateurs voulant accéder aux applications/données sur ce serveur sont bloqués ;
dysfonctionnement global d’un smartphone/téléphone mobile/téléphone fixe du directeur commercial ;
remontée d’alerte automatique : avertissement sur seuil atteint de la capacité d’espace disque d’un serveur ;
imprimante bloquée pour tout un département ou service.
Les incidents réseau
Des incidents liés aux réseaux sont aussi très souvent rencontrés :
réseau défaillant : plus de communication vers Internet depuis un navigateur pour tous les salariés de l’entreprise ;
plus de connexion possible au système d’information pour tout un bâtiment/site ;
lenteur constatée sur un site de production situé en Espagne ;
remontée d’alerte automatique : avertissement sur seuil atteint de la bande passante ;
dysfonctionnement du WiFi sur le smartphone du PDG ;
compte bloqué après saisie de mot de passe invalide d’un comptable qui n’a plus que quelques heures pour finaliser la clôture comptable mensuelle.
Les défaillances de logiciels
Bon nombre d’incidents se rapportent aussi aux défaillances de logiciels ou d’applications métiers ou bureautiques :
application indisponible : impossible de respecter les engagements de ventes, impact direct sur le chiffre d’affaires ;
fonction applicative non disponible : calcul de paie de tous les salariés ;
erreur de programme (bug) lors de la passation d’une commande : risque d’impact sur le chiffre d’affaires ;
absence de synchronisation des emails entre la messagerie sur le PC et celle sur le smartphone de la directrice des opérations ;
page d’un site web inaccessible (erreur HTTP 404) pour une recherche d’information par un employé ;
diminution de la performance d’une application de contrôle de la qualité des produits fabriqués ;
impossibilité de sauvegarder un fichier MS-Word dans Office365.
Les demandes diverses
Au-delà de ces incidents classiques, certaines sollicitations du service Desk peuvent se référer à des demandes diverses, qui sont aussi suivies dans le cadre de la gestion des incidents :
demande d’information, de documentation utilisateur (mode opératoire), d’assistance ou de conseil suite à un défaut de maîtrise de certaines fonctionnalités applicatives ;
demande de conseil d’utilisation ;
perte de droits d’accès, oubli d’un mot de passe au retour de congés.
Comme vous pouvez le voir au travers de ces exemples, un incident est plus ou moins important et peut impacter une ou plusieurs personnes. Nous allons découvrir dans la prochaine section comment établir la priorisation de la prise en charge des incidents.
Définissez la priorité de traitement de l'incident
Évaluer la gravité, l’étendue d'un incident pour déterminer son ordre de traitement dans la file des incidents, est un des rôles clés du technicien. Ainsi, à la fin de cette section, vous saurez comment prioriser la résolution de chaque incident.
La priorité d’un incident permet d’identifier dans quel ordre les incidents doivent être traités par les équipes du service Desk.
La priorité est la combinaison de l’impact et de l’urgence de l’incident :
impact (ou sévérité) : effet d'un incident sur l’activité, sur le business (risque sur le chiffre d’affaires ou sur les potentielles pertes financières).
Les incidents qui affectent beaucoup d’utilisateurs ont un effet plus sensible sur l’activité de l’entreprise et doivent être résolus plus rapidement qu’un incident qui concerne peu d’utilisateurs ;
urgence (ou criticité) : temps que peut mettre un incident à avoir des répercussions négatives sur les affaires. C’est donc la rapidité à laquelle l’entreprise a besoin d’une solution.
La priorisation dépend aussi du rôle de (des) personne(s) perturbées par l’incident :
VIP – Very Important Person : en général, les membres du comité exécutif, du comité de direction. La liste des VIP est établie par la Direction générale ;
VOP – Very Operational Person : souvent des personnes différentes en fonction du temps (par exemple, le responsable de la paie en fin de mois), les VOP se définissent par le fait qu’elles jouent un rôle clé sur l’activité. En général, il s’agit des personnes dont le métier est la vente (risque d’impact sur le chiffre d’affaires), d’un domaine sensible (médical, clôture comptable à J+6 du mois+1…) ou liées à la saisonnalité (pic d’activité).
Soyons pragmatique et simple : afin d’éviter une complexité avec un grand nombre de combinaisons possibles, nous pouvons restreindre à 3 niveaux d’impact et 3 niveaux d’urgence :
niveaux d’impact :
haut (ou élevé ou bloquant) : un grand nombre d’utilisateurs est impacté, ou c’est une application majeure qui est concernée, ou encore il s’agit d’un VIP/VOP,
moyen : un nombre limité d’utilisateurs est impacté, ou c’est une application standard qui est concernée,
bas (ou faible ou mineur) : un seul ou très peu d’utilisateurs (hors VIP/VOP) sont impactés, ou c’est une application bureautique qui est concernée ;
Niveaux d’urgence :
haut (ou critique) : application ou équipement critique,
moyen : application ou équipement non critique,
bas (ou faible) : utilisation acceptable en mode dégradé.
Pour fixer correctement et rapidement la priorité sans avoir à repenser, recalculer à chaque fois les combinaisons possibles, nous constituons en amont la matrice de priorités, conformément aux contrats de niveaux de service. À l’intersection ligne (urgence)/colonne (impact), se situe la priorité :
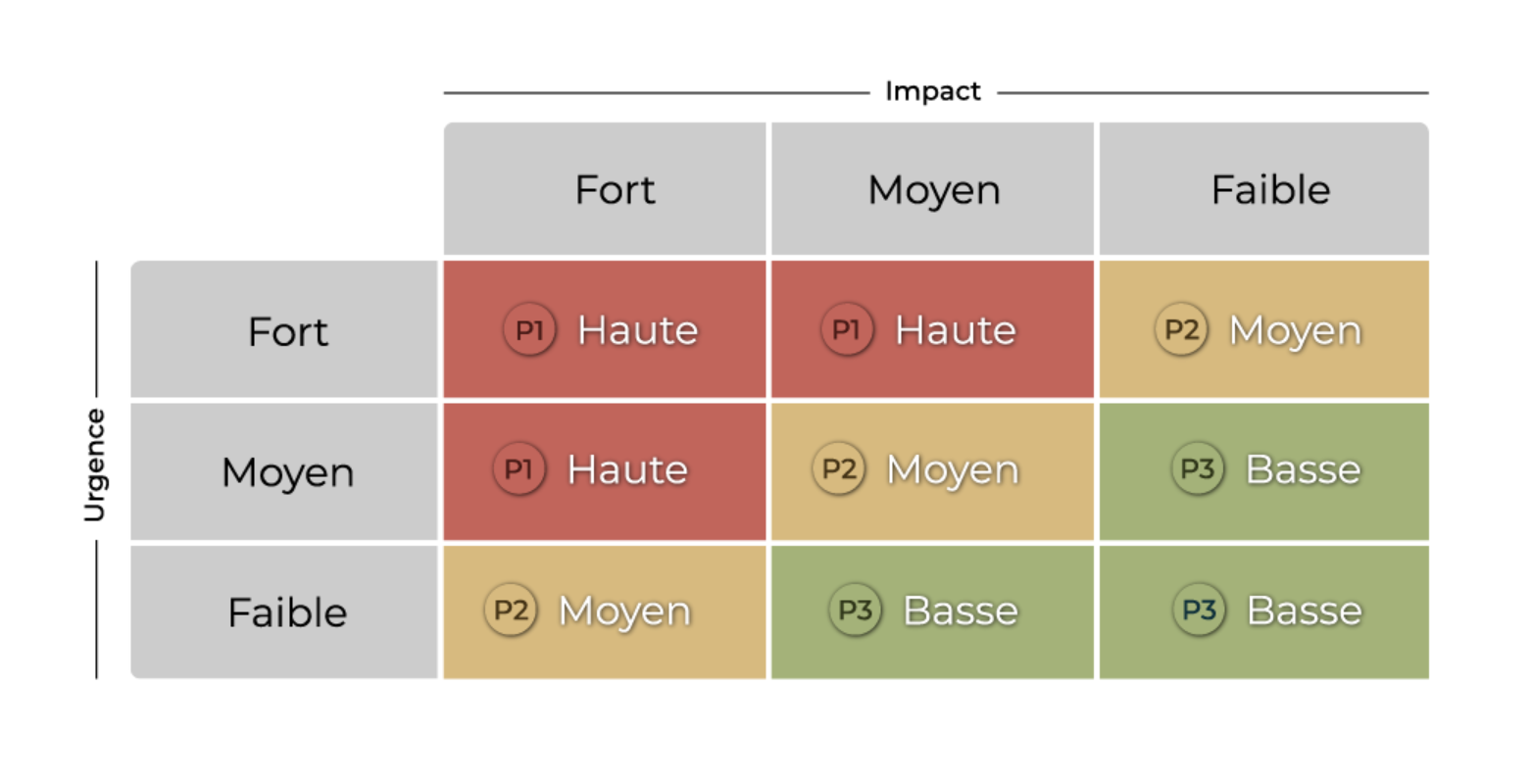
La matrice de priorité se configure dans GLPI via le menu Configuration > Générale > Assistance.
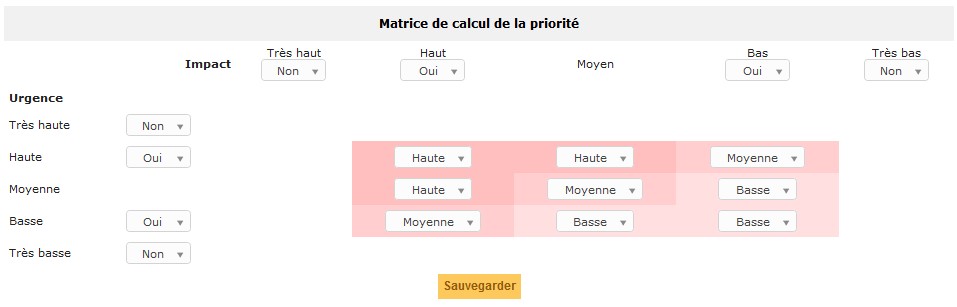
À chaque priorité est défini un délai maximum de remise en service. Chaque organisation définit ses propres délais.
Voici un exemple complet de délais maximum de résolution dans la matrice des priorités :
Priorité & Délai de résolution | Impact haut | Impact moyen | Impact bas |
Urgence haute | Priorité haute Résolution en 4 heures | Priorité haute Résolution en 4 heures | Priorité moyenne Résolution en 8 heures |
Urgence moyenne | Priorité haute Résolution en 4 heures | Priorité moyenne Résolution en 8 heures | Priorité basse Résolution en 24 heures |
Urgence basse | Priorité moyenne Résolution en 8 heures | Priorité basse Résolution en 24 heures | Priorité basse Résolution en 24 heures |
Au-delà des priorités haute, moyenne et basse, GLPI permet de saisir une priorité majeure que nous réservons aux cas d’incidents les plus graves.
Dans ces circonstances, il est nécessaire de déclencher une procédure particulière permettant de mobiliser des ressources adaptées à la situation critique de l’entreprise :
mise en place d’une cellule de crise ;
information du haut management ;
communication périodique toutes les x heures pour informer de l’état de situation, de l’avancement de la résolution…
Ça y est, vous savez maintenant comment estimer la priorité de vos incidents et donc leur délai de traitement.
Dans la prochaine section : c’est parti, vous allez savoir créer un ticket d’incident dans GLPI.
Créez le ticket incident dans GLPI
Dans cette section, nous allons créer notre premier ticket d’incident (fiche incident) dans GLPI.
Prenons un cas concret qui est assez fréquent au sein des entreprises : un vendeur appelle le centre de services car son poste de travail est hors service.
GLPI offre 3 possibilités pour ouvrir un ticket :
par email : l’utilisateur envoie un mail préformaté à une adresse mail générique de type « centre-de-services-DSI@entreprise.com », en décrivant l’incident dans le corps du mail ;
dans l'interface simplifiée de GLPI : saisie directement dans GLPI par l’utilisateur avec le formulaire self-service de saisie allégé ;
dans l'interface standard de GLPI : saisie par le technicien avec le formulaire de saisie complet.
En tant que technicien, nous utilisons l’interface standard de GLPI, accessible depuis l’écran d’accueil de GLPI par le menu Assistance > Créer un ticket.
Renseignez les champs de base
Date d’ouverture : laissez la date et l’heure renseignées par défaut.
Type : “incident” (un Incident concerne un dépannage, alors que la Demande appelle un traitement suivant un circuit différent).
Demandeur : le vendeur s’appelle Martial LODEZ.
Attribué à : laisser ce champ renseigné par défaut avec votre nom.
Statut : nouveau (pour nouvel incident).
Source de la demande : appel au centre de services.
Lieu : important pour localiser le demandeur (site, étage, n° de bureau…) : Agence Paris XII - RdC - Bureau 047C.
Décrivez l’incident : soyez précis
C’est le moment le plus important du processus de gestion des incidents, car il permet de comprendre l’incident et d’envisager les premières pistes de résolution.
Titre : résumez le dysfonctionnement en quelques mots (soyez clair et succinct) : Poste de travail ne démarre pas.
Description : décrivez le fonctionnement anormal du service, de façon précise et détaillée. Si un autre technicien que vous doit intervenir plus tard sur ce ticket, toutes les précisions (contexte, cas d’utilisation…) lui serviront pour résoudre l’incident : M. Lodez appuie sur le bouton Power de son poste de travail, et celui-ci ne démarre pas, même après plusieurs tentatives.
Catégorie : permet d’évaluer sur quel composant de l’infrastructure se situe l’incident. Si le technicien n’a pas la compétence ou la capacité à résoudre l’incident, cette catégorisation permet d’identifier le groupe de support vers lequel l’incident sera à diriger : Matériel.
Saisissez les champs de classification de l’incident
C’est le moment d’évaluer la gravité de l’incident : vous saisissez Urgence et Impact, et GLPI en déduit la priorité :
urgence : l'urgence indique l'importance donnée par le demandeur au ticket. Cette valeur est donc définie par le demandeur(ici, Monsieur Lodez). Le technicien apporte son conseil au demandeur sur l’évaluation de l’urgence, en fonction des accords de niveaux de service :
rappel de la définition de l’urgence : temps que peut mettre un incident à avoir des répercussions négatives sur les affaires,
ici, choisir dans la liste déroulante : Haute ;
impact : cette valeur est définie par le technicien. C’est lui qui évalue l’impact en fonction de sa connaissance globale de l’entreprise et de sa compréhension du métier.
rappel de la définition de l’impact : plus l’incident a des répercussions négatives sur le business, plus l’impact est haut,
ici, choisir dans la liste déroulante : Moyen ;
priorité : Laissez GLPI calculer la priorité, selon la combinaison de l’urgence et de l’impact. Dans notre exemple :
l’urgence est haute : plus on attend, plus l’impact sur les ventes et le chiffre d’affaires sera élevé,
l’impact est moyen : il ne s’agit que d’un seul vendeur qui est affecté par l’incident,
ainsi, la priorité qui découle d’urgence et impact est : haute (selon la matrice des priorités définie dans la section 3) ;
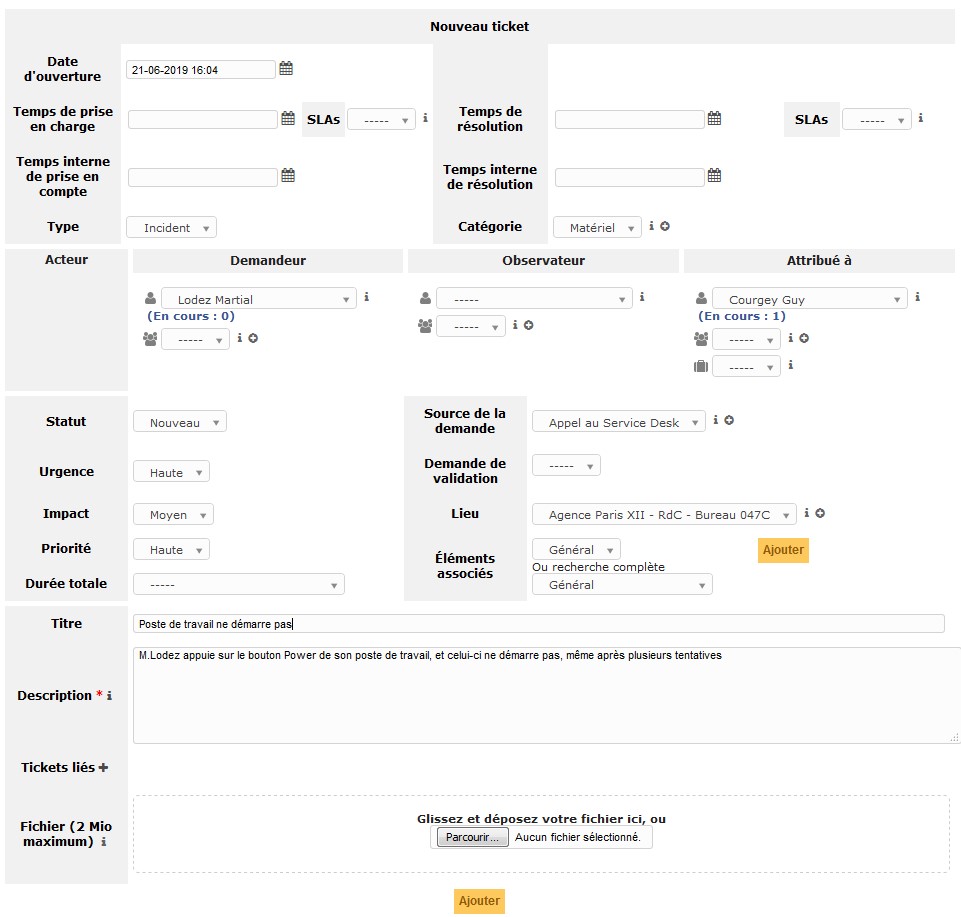
demande de validation : nécessaire lorsque les actions demandées au centre de services sont soumises à autorisation. Par exemple, il faut saisir ici le nom du responsable du parc informatique si le ticket concerne une demande d’un tout nouveau matériel ;
les temps de prise en charge et de résolution sont gérés automatiquement en fonction des SLA configurés dans GLPI :
temps de prise en charge = la garantie de temps d'intervention (GTI) : délai dans lequel un service accidentellement interrompu doit avoir occasionné un début d'intervention,
temps de résolution = la garantie de temps de rétablissement (GTR) : délai dans lequel un service accidentellement interrompu doit être rétabli ;
idem pour les temps internes de prise en compte et de résolution interne : ils sont gérés automatiquement en fonction des OLA configurés dans GLPI (un OLA est un engagement interne aux différents pôles de la DSI) ;
le champ Fichier permet d’ajouter au ticket un document utile à la compréhension et la résolution de l’incident par les techniciens de la DSI. Il s’agit le plus souvent d’une capture d’écran, et/ou de la description des circonstances de l’incident (se produit dans tel cas, mais ne se produit pas dans tel autre).
Après avoir cliqué sur le bouton Ajouter, le ticket apparaît en tête de la file d’incidents, et une notification par mail est envoyée au demandeur indiquant la référence (le numéro) du ticket créé :

Gérez les tickets récurrents
Qu’est-ce qu’un ticket récurrent dans GLPI ?
Un ticket récurrent est ouvert pour que GLPI crée automatiquement un ticket d’incident « juste avant » que l’incident prévu ne soit effectif.
Ceci permet d’alerter le centre de services sur des cas comme :
se préparer à intervenir suite à un bourrage papier lors de l’édition périodique d’un sujet sensible ;
ouvrir un ticket tous les mois pour se rappeler de vérifier le résultat de la sauvegarde mensuelle ;
valider que le traitement de clôture comptable à J+6 de M+1 s’est bien effectué ;
etc.
Dans GLPI, ce type de ticket se crée via le menu Assistance > Tickets récurrents :
saisissez le nom du ticket récurrent : Imprimante KDA2830 – Bourrage papier hebdo ;
rendez ce ticket actif (choisissez Oui dans la liste déroulante) : cela permet de générer le ticket incident, selon les critères/éléments suivants :
gabarit de ticket : Bourrage Papier. C’est ce modèle de ticket qui sera utilisé pour créer le ticket incident,
date de début et date de fin de la création du ticket d’incident,
périodicité de création du ticket (ici la fréquence est : tous les 7 jours),
création anticipée : 2 heures avant l’incident hebdomadaire,
calendrier : 2019 (permet de ne créer le ticket que sur les jours ouvrés de l’année 2019, et report à J+1 ouvré si le jour n’est pas ouvré) ;
décrivez l’incident dans la zone commentaires : Lors de l'édition hebdomadaire des factures, l'imprimante KDA2830 est en bourrage papier à la moitié de l'impression des factures.
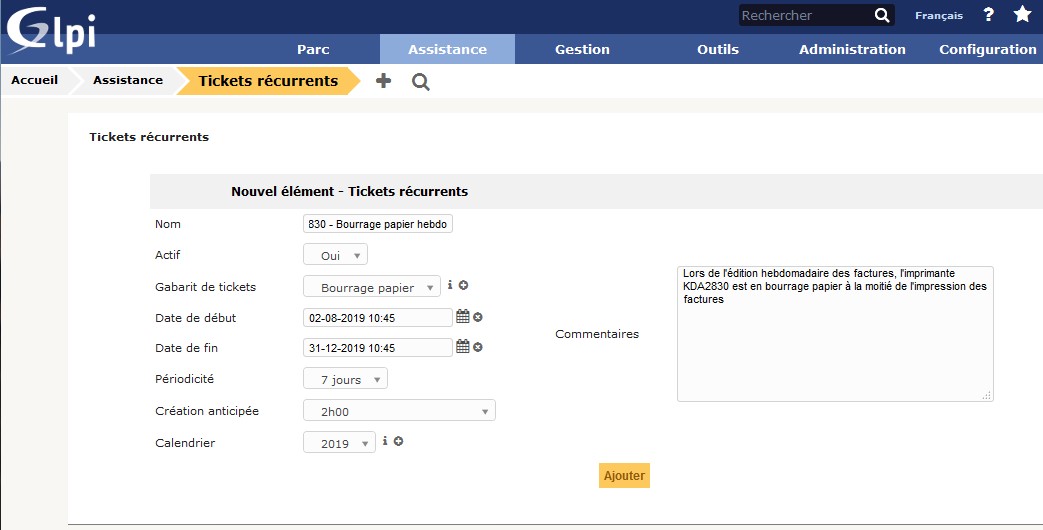
Puis cliquez sur le bouton Ajouter.
Dès lors que le flag « Actif » est positionné à « Oui » et que l’action automatique « ticket recurrent » est activée dans GLPI, alors le ticket sera créé automatiquement.
En résumé
Dans ce chapitre, nous avons :
découvert ce qu’est un incident au sens ITIL ;
évalué le niveau de gravité de cet incident en veillant à recueillir de manière précise et exhaustive toutes les informations relatives au dysfonctionnement rencontré, de manière à être en mesure de prioriser, catégoriser et effectuer le diagnostic ;
priorisé la résolution de l’incident, sachant que la priorité est la combinaison de l’impact et de l’urgence, servant à identifier le délai acceptable de résolution d’un incident ;
créé notre premier ticket d’incident ;
et enfin appris à générer automatiquement un ticket récurrent.
Dans le prochain chapitre, nous allons suivre le traitement du ticket d'incident.
