Créez et qualifiez un ticket de problème
Nous allons voir dans ce chapitre comment créer un ticket de problème dans GLPI, et comment le traiter jusqu’à sa clôture. Allons-y !
Identifiez un problème
L’objectif de cette section est de cerner ce qu’est un problème, de savoir le distinguer d’un incident et de comprendre l’importance de la démarche préventive dans le contexte de gestion de problèmes.
Mais tout d’abord, qu’appelle-t-on un problème ?
Là encore, le bon réflexe est de se référer au référentiel ITIL :-) qui nous décrit qu’un problème est la cause inconnue et sous-jacente d’un incident.
Cette définition mérite quelques explications issues de retours d’expérience de management des systèmes d’information : nous allons voir qu’un problème n’est pas seulement lié à un incident.
Un problème est issu d’un ou plusieurs incidents
Un problème s’identifie par :
un incident de cause inconnue : la cause définitive n'a pas été déterminée, donc l’incident est susceptible de se reproduire ;
un incident récurrent dans le temps (répétitivité de l’incident) ;
un incident qui entraîne en cascade d’autres incidents ;
un incident qui a un impact critique ou majeur sur l’activité ;
un afflux d’incidents présentant les mêmes symptômes ;
un défaut de l'infrastructure ou d'une application dont un outil d’alerte (supervision) a créé automatiquement un incident ;
l’analyse a posteriori des incidents survenus, dans le but de rechercher leur cause fondamentale et une solution définitive ;
un incident qui a été corrigé mais en dehors des délais de rétablissement des niveaux de services (SLA).
Un problème ne concerne pas seulement un incident, mais d’autres sujets comme la maintenance préventive
Un problème peut aussi concerner la demande d'un fournisseur pour installer en production un patch correctif, mais un point important dans la notion de problème est qu’il doit être vu selon 2 axes :
démarche réactive ou curative : l’objectif est de résoudre les problèmes identifiés, en analysant les incidents existants : actions a posteriori (on parle alors d’erreur inconnue) ;
approche proactive ou préventive : l’objectif, ici, est d’identifier d’éventuels problèmes potentiels avant qu’un incident ne survienne (on parle alors d’erreur connue) et ainsi d'éliminer les causes d’incidents potentiels.
Distinguez un incident d’un problème
La gestion des incidents vise à la mise en place d’un palliatif afin de rendre le service de nouveau disponible, le plus rapidement possible, sans contrainte de qualité.
L’enjeu est l’efficacité : la solution est souvent un contournement ponctuel qui permet dans les délais les plus courts, de rétablir le niveau de service normal.
Alors que la gestion des problèmes a pour objectif la mise en place d’une solution pérenne, une correction définitive.
Ici, la DSI prend le temps d’identifier la cause réelle (cause initiale ou sous-jacente) de l’incident en vue d’éliminer cette cause, et au final que l’incident ne se reproduise plus jamais.
Le processus de gestion des problèmes est donc au cœur de la réduction des risques IT.
Prenons l’exemple du plantage (crash) d’une machine virtuelle (VM) sur un serveur, pour illustrer la différence entre incident et problème :
dans le cadre de la gestion de l’incident, le centre de services procède au plus tôt au redémarrage de la VM, vérifie qu’elle fonctionne et clôt le ticket : restauration immédiate du service ;
dans le processus de gestion des problèmes, la DSI analyse en profondeur pourquoi la VM s’est plantée (origine du crash selon : analyse de logs, de dimensionnement, des services tournant sur cette VM…) et met en place les paramètres adéquats de la VM pour qu’elle ne tombe plus jamais en panne.
Un autre exemple significatif pour distinguer problème et incident : le cas d’un serveur bureautique de documentation (où chacun dépose ses fichiers pour éviter de travailler en local sur son poste de travail) dont la volumétrie maximale est atteinte : plus personne ne peut sauvegarder de fichier sur ce serveur :
lors du traitement de l’incident, le centre de services établit la liste des fichiers les plus volumineux, demande à leur propriétaire de les supprimer dans la mesure du possible, et une fois que l’espace disque suffisant est à nouveau disponible, clôt l’incident ;
en gestion de problème, l’analyse en profondeur est menée : quel événement a provoqué la saturation de l’espace disque (étude des logs…), quelle est la prévision de l’augmentation de l’espace disque (capacity planning), quelle est l’efficience des purges (critères de suppression de fichiers)… Et des mesures précises sont alors décidées : nouvelle planification des purges, nouveaux critères de suppression de fichiers, mise en place d’un traitement de nuit de compression des fichiers d’une certaine taille et qui n’ont pas été modifiés depuis un certain temps, ajout d’une alerte de supervision sur seuil de remplissage de l’espace disque…
Découvrez comment initier un problème : tout incident ne donne pas lieu au traitement d’un problème
La source d’ouverture d’un problème est le plus souvent un incident significatif/majeur, une demande d’un fournisseur, une analyse préventive de l’infrastructure (capacité, disponibilité…), la veille (tendances permettant de rendre le SI plus robuste selon les avancées technologiques), les utilisateurs eux-mêmes via les enquêtes de satisfaction…
Mais doit-on systématiquement ouvrir un problème pour tous les incidents sévères, récurrents et impactant significativement l’activité ?
Les critères de sévérité, de répétitivité, de nombre d’utilisateurs impactés ne sont pas les seuls à entrer dans la décision d’ouvrir un problème.
En effet, toutes les « erreurs connues » peuvent ne pas être corrigées, lorsque par exemple la résolution est trop chère ou trop longue à mettre en œuvre.
Il convient alors de définir d’autres catégories pour ouvrir un problème, comme par exemple :
la perte de chiffre d’affaires ;
les incidents sur périmètre métier critique (services SI sensibles) ;
la durée et le coût de résolution du problème ;
les incidents dont la résolution a été effectuée en dépassement de délai des SLA ;
les incidents coûteux pour la DSI (et donc au final coûteux pour l’entreprise) : incidents déclarés en période non ouvrée car ils engendrent un surcoût lié au tarif horaire.
L’enjeu est aussi le retour sur investissement du traitement du problème : quel gain (ROI versus coût non justifié) a-t-on de mettre en place une solution pérenne versus de gérer l’incident même s’il est récurrent ?
Les facteurs clés de décision sont :
avoir une approche globale et transverse du système d’information sur l’ensemble des incidents et problèmes, pour décider de lancer ou pas l’analyse de certains incidents/problèmes ;
évaluer le risque opérationnel.
Ainsi, des arbitrages sont à mener par les responsables SI et/ou métiers (selon priorités, coûts de résolution, contraintes…) pour décider du traitement d’un problème.
Si la décision est prise de ne pas donner suite à un problème ouvert dans GLPI, il est possible de clôturer le ticket problème avec le motif par exemple : « sans suite, selon décision en comité d’arbitrage ».
Apprenez les objectifs et bénéfices de la gestion des problèmes
En synthèse, les objectifs de la gestion des problèmes sont de :
diagnostiquer/analyser la cause fondamentale (cause sous-jacente ou cause première) des incidents : Root Cause Analysis ;
déterminer et mettre en place une solution permanente et définitive, qui empêche la reproduction de l’incident ;
initier les actions d’amélioration des services SI (infrastructures, applications) pour prévenir proactivement que des incidents surviennent.
Un centre de service qui n’a pas instauré de gestion des problèmes est confronté aux risques suivants :
un fonctionnement en « mode pompier » : un support informatique agissant uniquement en réactivité, une fois que les utilisateurs sont bloqués ;
une faible efficacité avec des coûts élevés et des techniciens peu motivés du fait de la répétitivité du travail pour résoudre les incidents récurrents ;
une image négative auprès des utilisateurs, voire une perte de confiance en la capacité à maîtriser le système d’information, du fait d’incidents récurrents pour lesquels aucune solution structurelle n’est mise en œuvre.
Les principaux gains à établir un processus de gestion des problèmes sont :
la réduction du nombre d’incidents, et ainsi un impact positif sur l’activité de l’entreprise : contribution à la performance de l’entreprise ;
l'augmentation du taux de résolution immédiate des incidents par le centre de services ;
la qualité de service IT améliorée de façon significative : diminution du nombre d’utilisateurs peu satisfaits de l’IT, renforcement de l’image positive de la DSI.
Qualifiez le problème et définissez la priorité de son traitement
Dans cette section, nous allons appréhender la bonne classification d’un problème, afin de favoriser un meilleur traitement du problème en termes de qualité et de rapidité de correction.
2 grands thèmes permettent de classifier un problème :
la catégorie ;
la priorité (déduite de l’urgence et de l’impact du problème).
Déterminez la catégorie d’un problème
La catégorie permet de comprendre quel élément du système d’information, quel service SI est concerné par le problème.
Ce sont généralement des familles regroupant des domaines techniques, comme par exemple : matériel PC/imprimante, serveur, réseau, téléphonie, messagerie, applications métier, bureautique…
Déterminez la priorité de traitement d’un problème
L’utilité de la priorité est d’identifier dans quel ordre les problèmes doivent être traités.
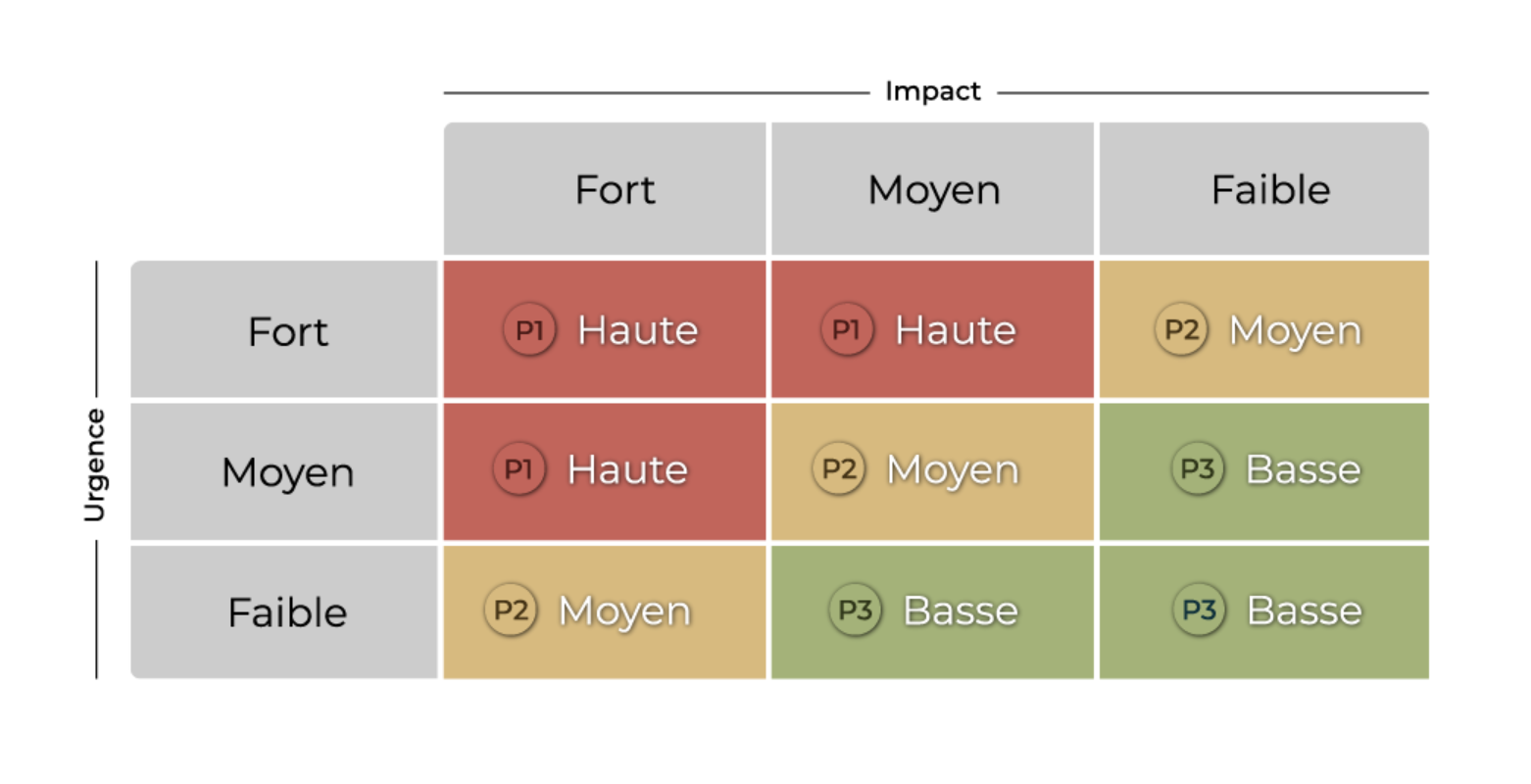
Notion d’impact : c’est l’effet sur les activités métiers, sur le chiffre d’affaires.
Notion d’urgence : temps que peut supporter l’entreprise avant résolution du problème.
Notion de priorité : ordre de traitement du problème dans la liste d’attente des problèmes. La priorité se déduit de l’urgence et de l’impact selon la matrice de calcul des priorités paramétrée dans GLPI :
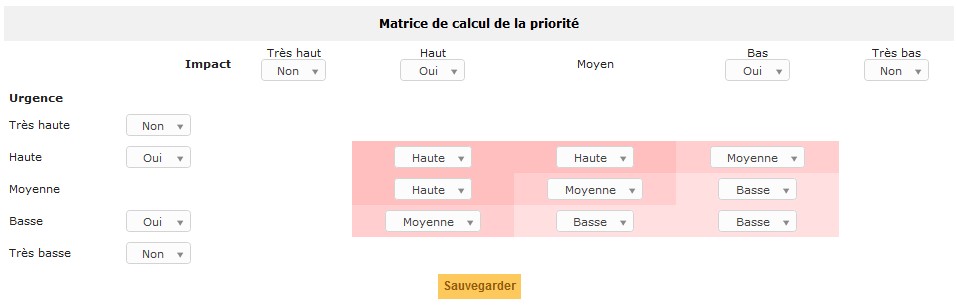
Ainsi, GLPI calcule automatiquement la priorité, mais comme pour les incidents, GLPI permet au technicien d’adapter la priorité selon d’autres critères que l’urgence et l'impact ; par exemple, selon :
la fréquence de répétitivité des incidents liés au problème ;
l’ampleur/l'étendue imaginée de la correction à apporter ;
l’estimation du délai nécessaire à la mise en place de la correction ;
l’appréciation du coût de mise en œuvre de la correction.
Découvrez le rôle du Problem Manager dans la qualification du problème
Le Problem Manager est le responsable du processus de gestion des problèmes : c’est lui qui au final gère la priorité de traitement du problème.
Son activité de pilote de mini projets s’inscrit entre 2 processus :
la gestion des incidents, qui est prioritaire pour permettre le retour des services en mode nominal le plus rapidement possible, et dont les ressources niveau 2/niveau 3 sont souvent les mêmes que celles impliquées dans la gestion des problèmes ;
la gestion des changements, qui suit un planning précis établi avant que ne soit déclaré un problème.
Ainsi, le Problem Manager :
doit fédérer et convaincre les acteurs du support pour traiter les problèmes (bien souvent en justifiant du retour sur investissement rapide) ;
n’est pas nécessairement un expert technique ;
ne peut pas avoir le rôle de responsable du centre de services, ni d’Incident Manager, ni de Change Manager.
Créez le ticket problème dans GLPI
L’objectif de cette section est d’ouvrir dans GLPI votre tout premier ticket de problème.
Allons-y : lançons GLPI et cliquons sur le menu Assistance > Problèmes.
Renseignez les champs de base
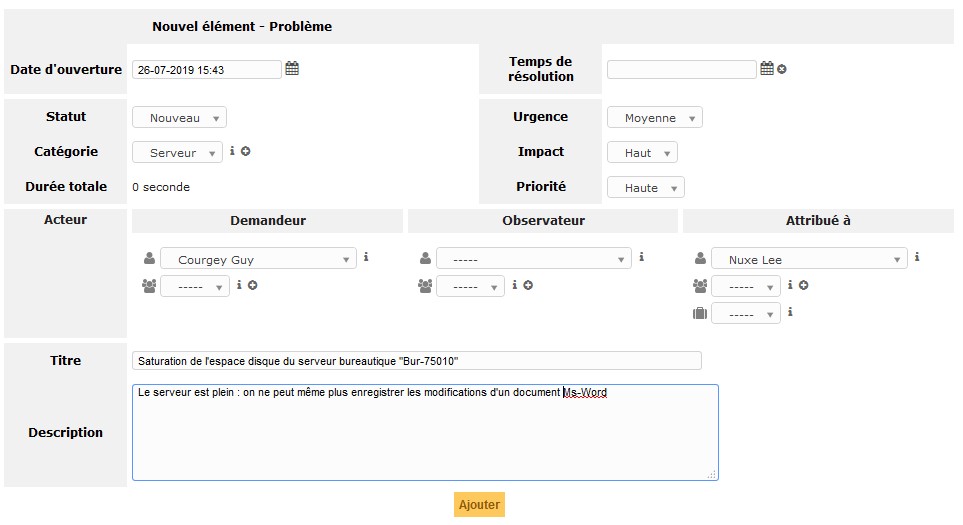
Date d’ouverture : laissez la date et l’heure renseignées par défaut.
Statut : nouveau (pour nouveau problème).
Demandeur : champ renseigné par défaut avec le nom de la personne qui crée le ticket : Courgey Guy.
Attribué à : c’est le plus souvent le PM – Problem Manager – qui attribuera le ticket dans un second temps à une personne qualifiée et disponible. Ainsi, choisir dans la liste déroulante le Problem Manager : Nuxe Lee.
Saisissez les champs de classification du problème
Catégorie : permet de cibler sur quel composant de l’infrastructure se situe le problème : Serveur.
Urgence : délai que peut accepter l’entreprise avant résolution du problème : Moyenne.
Impact : effet du problème sur les activités métiers, sur le chiffre d’affaires : Haut.
Priorité : GLPI calcule la priorité, selon la combinaison de l’urgence et de l’impact de la matrice des priorités. Dans notre exemple, priorité = Haute. Vous pouvez modifier la priorité proposée par GLPI, selon le contexte du problème.
Décrivez le problème : soyez le plus précis possible
Plus la description est explicite, plus le problème sera vite cerné et donc résolu.
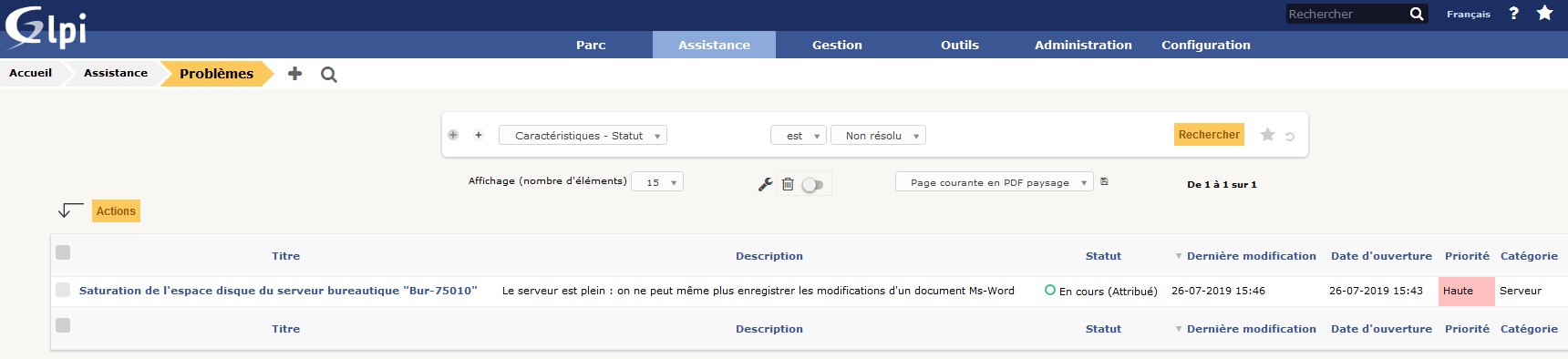
Titre : résumez le problème en quelques mots en étant clair et succinct : Saturation de l'espace disque du serveur bureautique "Bur-75010".
Description : décrivez de manière précise et détaillée le problème : Le serveur est plein : on ne peut même plus enregistrer les modifications d'un document MS Word.
Après avoir cliqué sur le bouton Ajouter, le ticket apparaît en tête de la file des problèmes, avec sa référence : le numéro de ticket problème.
En résumé
Dans ce chapitre, nous avons :
découvert ce qu’est un problème au sens ITIL, en le distinguant d’un incident ;
appris à créer un problème à bon escient : soit en approche réactive/curative sur la base d’un incident (récurrent ou non récurrent), soit en démarche proactive/préventive avant qu’un incident ne survienne ;
compris qu’un centre de services qui n’a pas mis en place de gestion de problèmes prend le risque de gérer ad vitam aeternam les mêmes incidents, et donc de démotiver les techniciens ;
qualifié et priorisé le traitement du problème, sachant que la priorité est le même concept que pour les incidents : la combinaison de l’impact et de l’urgence ;
et enfin créé votre premier ticket de problème.
Dans le chapitre suivant, nous allons suivre l'avancement de notre problème avec GLPI.
