Traitez et suivez votre ticket problème dans GLPI
Nous allons voir dans ce chapitre le cycle de vie complet d’un ticket problème dans GLPI, jusqu’à sa clôture.
Découvrez le processus de la gestion des problèmes dans GLPI
Dans le chapitre précédent, nous avons (déjà !) passé en revue les activités en amont du processus de gestion des problèmes :
l’identification des problèmes à partir des incidents récurrents ou non : démarche corrective de traitement des « erreurs connues » en vue de prévenir la réapparition des incidents ;
l’identification des problèmes en démarche préventive/proactive ;
l’enregistrement du problème ;
la catégorisation et la définition de la priorité du problème.
Nous allons donc voir maintenant les étapes suivantes du processus de gestion des problèmes : l’analyse du problème, ses solutions possibles et la mise en œuvre de la/des solution(s).
Réalisez l’investigation pour trouver la cause réelle du problème
Afin de faire une analyse complète du problème, il est nécessaire d’avoir un maximum d’informations pour l’aide au diagnostic et à la recherche d’une résolution structurelle.
Ces informations existent lorsqu’un (ou plusieurs) ticket(s) ont mené à la création d’un problème. Lors de la gestion de l’incident, nous avons indiqué dans GLPI la solution de retour à la normale du service SI et avons documenté la base de connaissances. Pour profiter de ces informations, la clé est de rattacher l’incident au problème.
Dans GLPI, afficher l’incident Impossible de sauvegarder la dernière modification de mon document Word sur le serveur de fichiers bureautique, cliquer sur l’onglet (menu vertical à gauche) Problèmes et ajouter le problème déjà ouvert Saturation de l'espace disque du serveur bureautique "Bur-75010" :
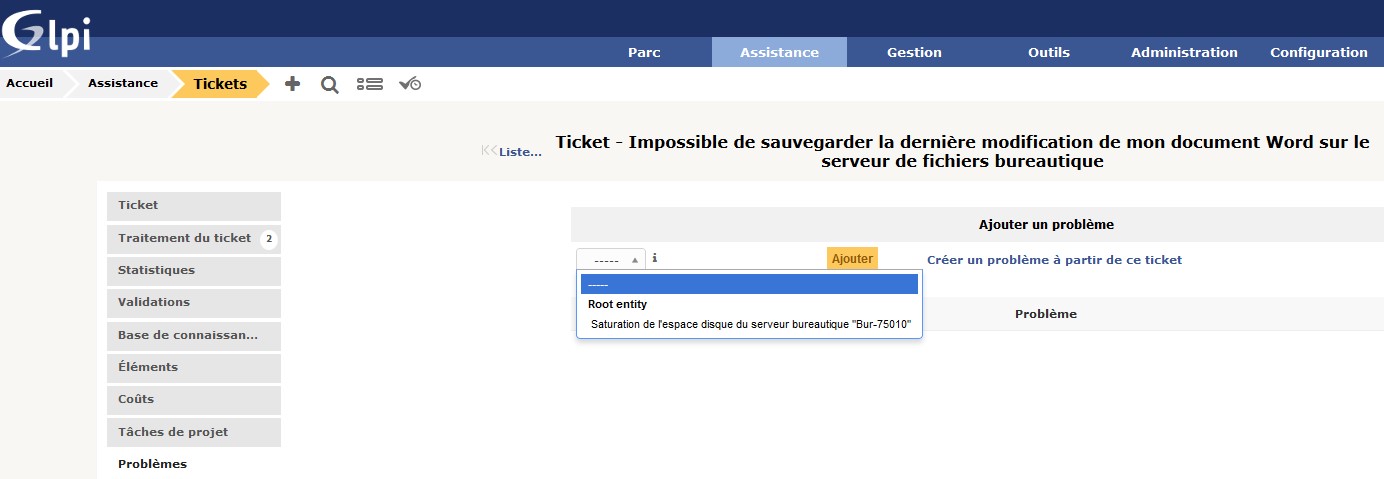
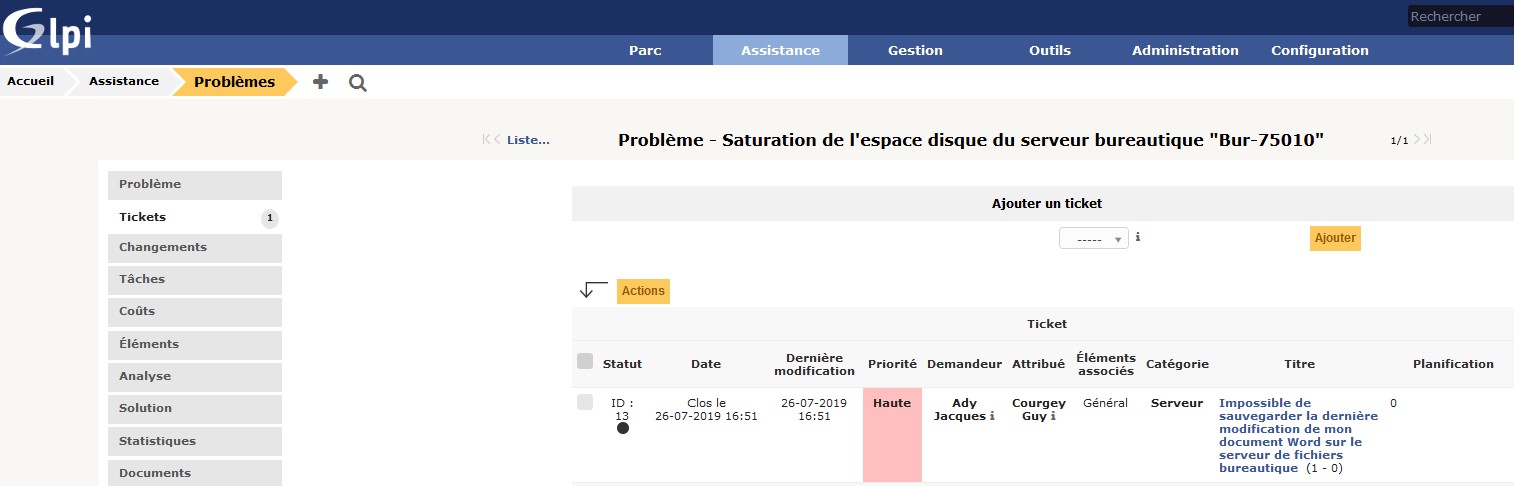
Lors de la consultation du problème dans GLPI, on voit bien que l’incident 13 est rattaché au problème 1 :
En complément de la connaissance et du détail de la résolution de(s) incident(s) lié(s) au problème, nous devons savoir quel(s) élément(s) de configuration est(sont) impactés par ce problème : quels sont les éléments de configuration qui fragilisent l’infrastructure et qui doivent être revus, améliorés ou remplacés.
Lorsque vous affichez le problème dans GLPI, cliquez sur l’onglet Éléments et ajoutez l’élément : « IBM System Storage EXP3000 ».
L’ensemble des données saisies jusqu’à maintenant va vous permettre de compléter l’analyse du problème dans GLPI : cliquez sur l’onglet Analyse, saisissez les 3 éléments suivants et cliquez sur Sauvegarder :
impacts : Impact business : le service commercial ne peut plus créer les devis ;
causes : Défaillance de la purge périodique des plus gros fichiers obsolètes et de la compression des fichiers de plus de 250 Mo ;
symptômes : La saturation de l'espace disque ne permet plus aux utilisateurs d'utiliser le serveur de fichiers bureautiques (plus de création, ni de modification de fichier possible).
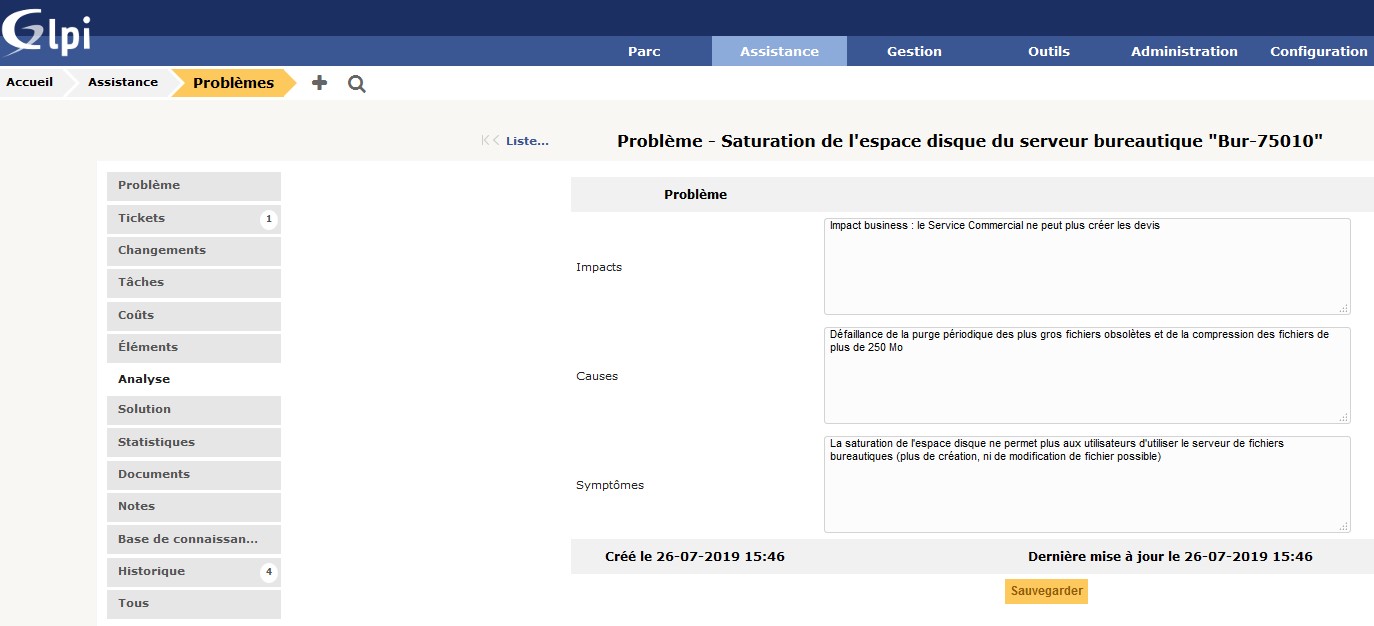
L’analyse a donc permis de trouver la cause réelle (sous-jacente ou encore le point exact d'origine) du problème : celle-ci est décrite dans GLPI.
Suivez le problème dans GLPI jusqu’à sa résolution
Une fois l’analyse du problème terminée, vous allez maintenant découvrir comment indiquer dans GLPI la description et la mise en œuvre de la solution (via la gestion des tâches et/ou la gestion des changements) et suivre le problème dans GLPI.
Un problème peut être résolu selon 2 axes :
solution via la gestion des tâches : pour ceux qui font l’objet d’actions immédiates qui n’ont pas d’impact négatif sur les services SI existants, les infrastructures existantes, comme par exemple des solutions de contournement ou la mise au point d’alertes par la supervision de l’exploitation ;
solution via la gestion des changements : des actions de fond de modification (paramétrages, remplacement de composants…) de l’infrastructure (ou des services SI) et qui nécessitent des tests avant livraison en production, comme la vérification de la non-régression, entre autres.
Définissez la résolution par des tâches
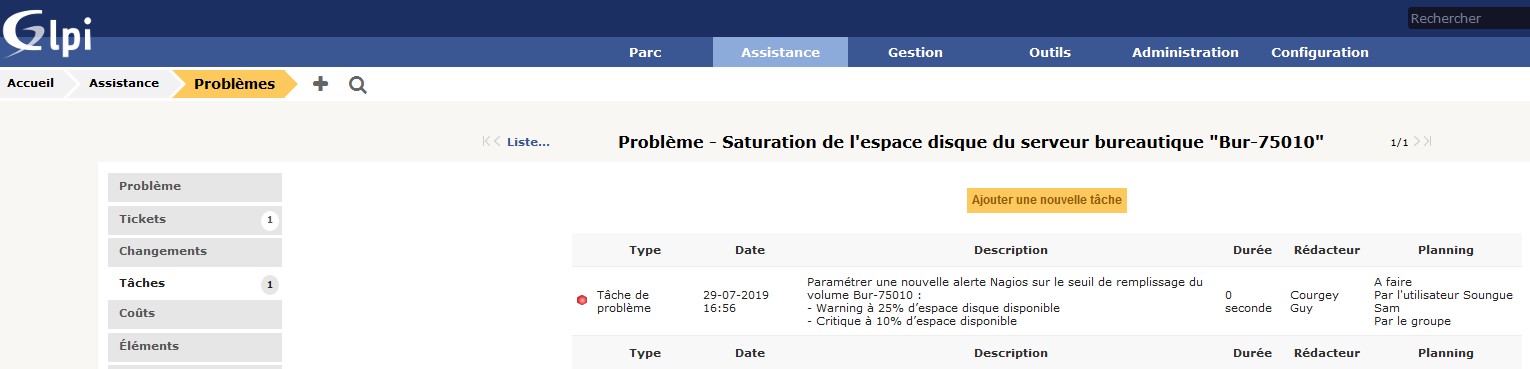
Dans notre exemple de problème, la solution fait l’objet d’une tâche (action sans risque de dégradation du SI) : ajout d’une alerte de supervision sur seuil de remplissage de l’espace disque.
Voici ce que cela donne dans GLPI : d’abord affichez le problème, puis cliquez sur l’onglet Tâches et créez la tâche : Paramétrer une nouvelle alerte Nagios sur le seuil de remplissage du volume Bur-75010 : Warning à 25 % d’espace disque disponible et Critique à 10 % d’espace disponible.
Définissez la résolution par la gestion des changements
Dans notre exemple, la tâche précédemment créée n’est pas suffisante car des modifications de l’infrastructure sont nécessaires pour :
l’augmentation de l’espace disque : ajout de volumes physiques ;
la nouvelle planification des purges avec de nouveaux critères de suppression de fichiers anciens, après avoir été archivés ;
la mise en place d’un traitement de nuit de compression des fichiers d’une certaine taille.
Même si les 2 dernières actions sont mineures en termes de risque de dégrader l’existant, elles font quand même l’objet d’une demande de changement, pour qu'elles rentrent dans un cycle complet de tests avant mise en production (on aurait l’air de quoi, si on livre en production des éléments qui empirent la situation plutôt que de corriger le problème !).
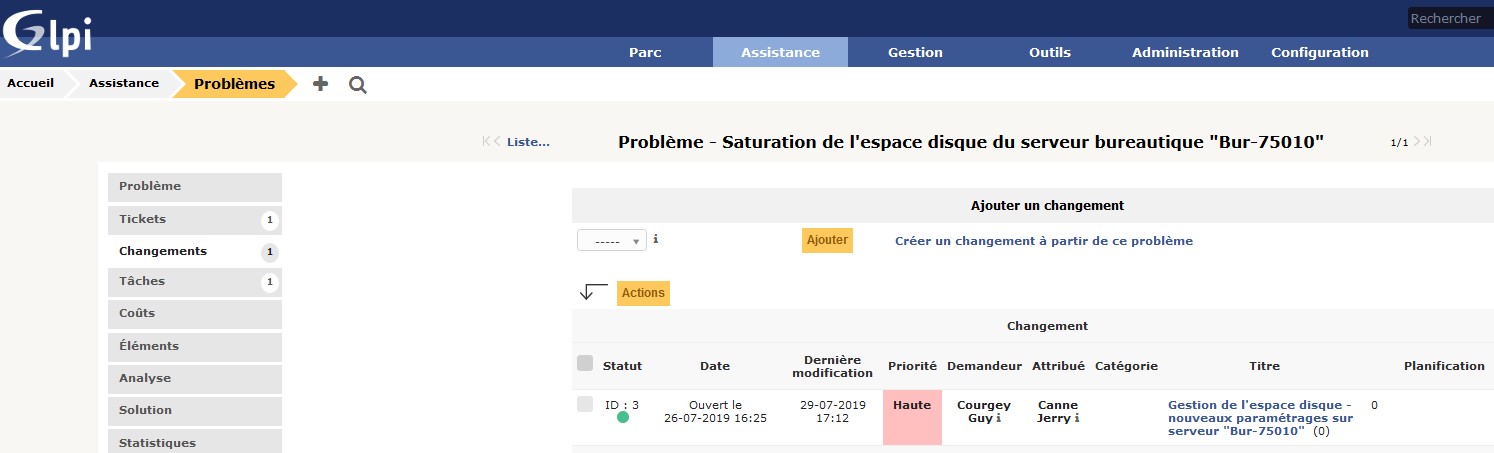
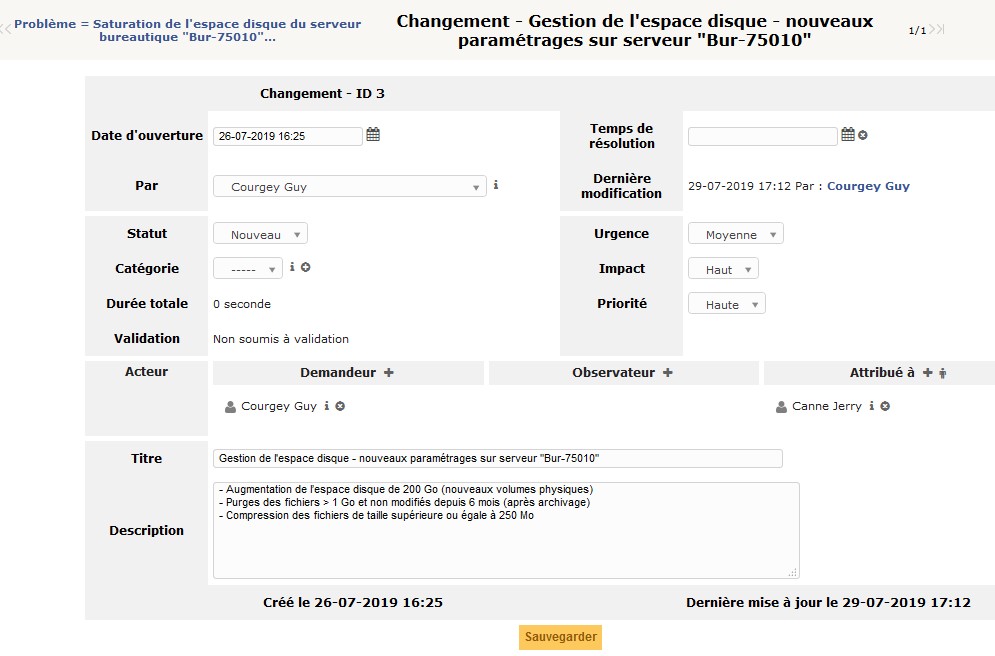
Et voilà ce que cela donne dans GLPI : sur le ticket Problème, cliquez sur l’onglet Changements et ajoutez un changement à partir de ce problème. Saisissez :
augmentation de l’espace disque de 200 Go (nouveaux volumes physiques) ;
purge des fichiers > 1 Go et non modifiés depuis 6 mois (après archivage) ;
compression des fichiers de taille supérieure ou égale à 250 Mo.
C’est donc le responsable de la gestion des changements qui va approuver, planifier et mettre en production la demande de changement (RFC – Request For Change), pour apporter la solution permanente au problème.
Dans le cas d'un problème urgent qui affecte sérieusement les métiers (impact sévère sur le business…), le processus de changement urgent sera suivi.
Nous venons de le voir : le processus de gestion des problèmes peut faire l’objet d’actions mineures qui ne réclament que quelques minutes pour le déploiement (et qui sont sans risque d’impact négatif sur les services SI), mais aussi des changements de plus grande ampleur qui se transforment en véritables projets. Le Problem Manager est bien le pilote de mini projets.
Suivez un problème majeur
Après la gestion et résolution d’un problème majeur (problème de sévérité très élevée), il est temps de faire le bilan du traitement du problème, dans l’objectif d’améliorer la prise en charge de ce type de problème s’il survient à nouveau : documentation de procédures (instructions de travail), formation des techniciens du centre de services…
Lors de ce retour d’expérience, vous veillerez à étudier :
comment prévenir la récidive,
quelles sont les éventuelles responsabilités des sous-traitants (et ont-ils bien pris en compte les enseignements de ce problème majeur) ;
quelles sont les attitudes et actions bien effectuées, mal effectuées ;
quelles sont les attitudes et actions qu’il faut mettre en œuvre la prochaine fois dans le cas d’un problème majeur.
En résumé
Dans ce chapitre, nous avons :
parcouru l’ensemble du cycle de vie d’un ticket problème dans GLPI ;
recueilli les informations (lien problème à incident, lien avec les éléments de configuration impactés par le problème) permettant l’analyse du problème pour en trouver la cause réelle (sous-jacente ou première) ;
indiqué dans GLPI qu’un problème peut être résolu par la conjonction de 2 types d’actions : la gestion des tâches (pour la mise en place de solutions de contournement) et la demande de changements (pour la gestion de mini projet d’implémentation de solutions de fond. Dans ce cas, vous passez la main à la gestion des changements) ;
fait un zoom sur les problèmes majeurs.
Dans le chapitre suivant, nous allons clôturer le ticket de problème.
