Découvrez la stack ELK

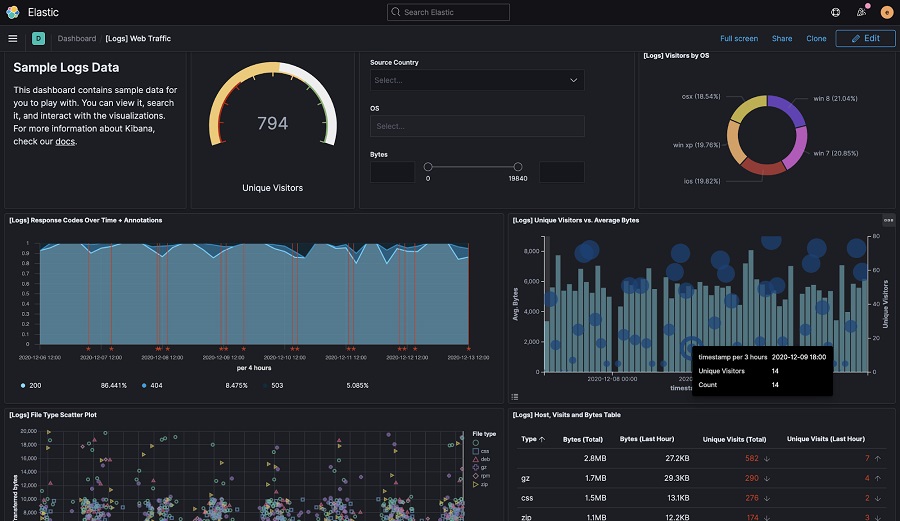
ELK est une suite open source comprenant 3 composants principaux : Elasticsearch, Logstash et Kibana. Beats a ensuite été ajouté pour former la stack ELK. ELK permet l’indexation et l’analyse de données. Vous pourrez par exemple charger différents types de données, comme vos logs, et les visualiser sous forme de diagrammes personnalisés comme dans le screenshot ci-dessous :
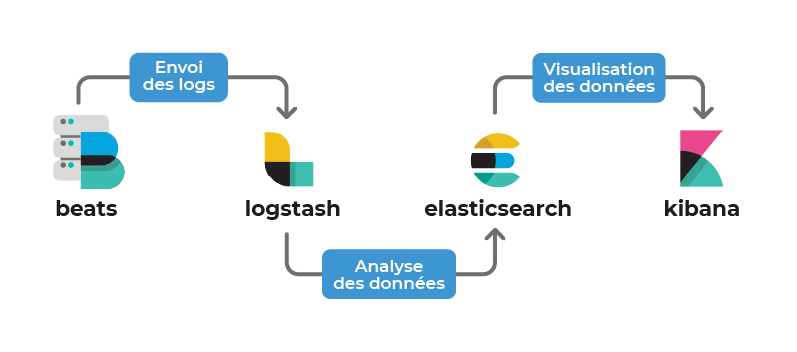
Beats : peut être installé sur les machines à monitorer en agent pour vous remonter les logs.
Logstash : permet l'agrégation des données dans Elasticsearch.
Elasticsearch : le composant principal, qui centralise les informations et y accède via une API RESTful.
Kibana : permet la création de dashboards et la visualisation des données dans ElasticSearch.
Apprenez-en plus sur les composants de la stack ELK
Comme nous venons de le voir, ELK est composée de plusieurs éléments. Regardons ensemble comment ils fonctionnent, et comment les utiliser.
Remontez vos logs avec Beats
Beats est un ensemble d’outils permettant l’envoi de logs. Ces outils devront être installés sur les machines que vous souhaitez monitorer. Ils agiront comme des agents qui collectent les journaux d'événement et logs :
Filebeat : ingestion de fichiers de logs.
Packetbeat : ingestion de fichiers de capture réseau.
Auditbeat : ingestion de fichiers audit.
Heartbeat : vérification si un service est disponible ou non.
Functionbeat : monitoring des environnements cloud.
Journalbeat : ingestion des logs systemd.
Metricbeat : collection des métriques de différents systèmes.
Winlogbeat : collection de logs Windows.
Vous vous en doutez, ici nous allons nous intéresser plus particulièrement à Winlogbeat, Filebeat et Packetbeat.
Agrégez les données avec Logstash
Logstash permet l'agrégation et le formatage de données pour l’envoi dans Elasticsearch. Logstash vous permettra donc d'envoyer différents types de données autres que des logs.
Centralisez vos données avec Elasticsearch
ElasticSearch est le moteur principal de la stack ELK : c’est lui qui va stocker les données et les rendre accessibles.
Il peut être utilisé pour plusieurs objectifs, mais sa fonctionnalité principale est l'indexation de flux de données. Dans notre cas, cette fonctionnalité permet le stockage centralisé des logs, tels que des journaux ou des paquets réseau, par exemple. Il est donc très utile pour notre monitoring de la sécurité.
Comment Elasticsearch stocke les données remontées ?
Elasticsearch stocke les données au format JSON. Ces données sont contenues dans des index qui sont des bases de données. Je vous conseille de créer un index par type de données ingérées (index1, index2...).
Et comment sont organisés ces index ?
Les index contiennent des documents dans lesquels les données sont organisées dans des “fields”, c'est-à-dire des champs. Dans le screenshot ci-dessous, nous pouvons voir que les fields sont définis dans la colonne de gauche.
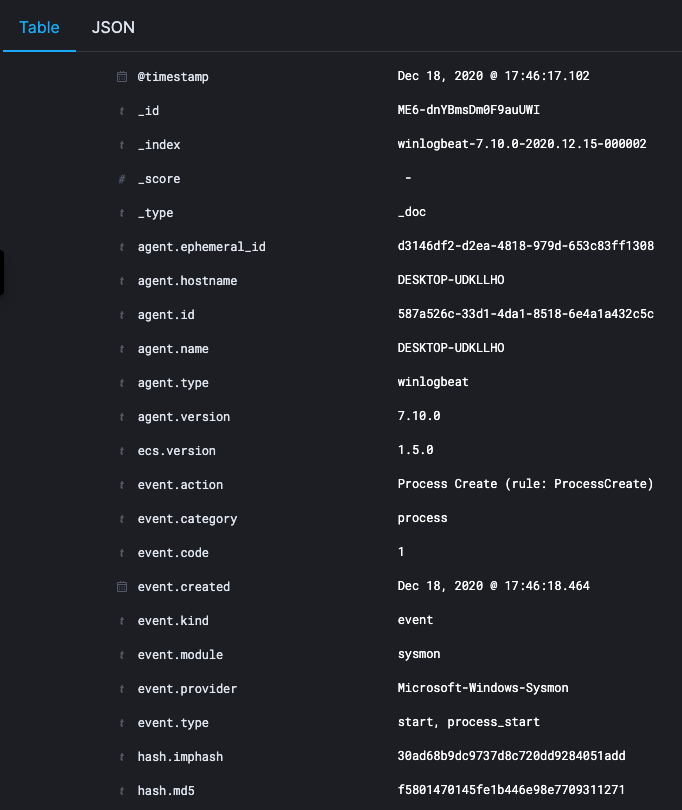
Pour récupérer les données, Elasticsearch fonctionne comme une API RESTful.
Visualisez vos données avec Kibana
Kibana va permettre de visualiser les données d’Elasticsearch en temps réel. Cet outil vous propose des dashboards préconfigurés pour analyser les logs qui vous sont remontés. Il est également possible de visualiser et d'explorer vos données dans la section Discover. Ceci est très utile pour visualiser vos logs et comprendre ce qu'ils contiennent. Cela vous permettra de mettre en place vos règles de SIEM plus facilement. Dans le screencast ci-dessous, découvrons cette fonctionnalité et la stack ELK :
En résumé
Nous venons de découvrir la solution SIEM que nous utiliserons dans ce cours. Elle est composée de 4 outils :
Beats, installé sur les machines à monitorer pour remonter les logs ;
Logstash, qui reçoit et agrège les logs dans Elasticsearch ;
Elasticsearch, le composant principal qui centralise les données ;
Kibana, où l’on peut visualiser les données avec des dashboards.
Maintenant, installons et configurons la suite ELK – suivez-moi au prochain chapitre !
